diff --git a/.idea/.gitignore b/.idea/.gitignore
new file mode 100644
index 0000000..35410ca
--- /dev/null
+++ b/.idea/.gitignore
@@ -0,0 +1,8 @@
+# 默认忽略的文件
+/shelf/
+/workspace.xml
+# 基于编辑器的 HTTP 客户端请求
+/httpRequests/
+# Datasource local storage ignored files
+/dataSources/
+/dataSources.local.xml
diff --git a/.idea/6.824.iml b/.idea/6.824.iml
new file mode 100644
index 0000000..5e764c4
--- /dev/null
+++ b/.idea/6.824.iml
@@ -0,0 +1,9 @@
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/modules.xml b/.idea/modules.xml
new file mode 100644
index 0000000..6d0f03a
--- /dev/null
+++ b/.idea/modules.xml
@@ -0,0 +1,8 @@
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/vcs.xml b/.idea/vcs.xml
new file mode 100644
index 0000000..35eb1dd
--- /dev/null
+++ b/.idea/vcs.xml
@@ -0,0 +1,6 @@
+
+
+
+
+
+
\ No newline at end of file
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..a000f7d
--- /dev/null
+++ b/README.md
@@ -0,0 +1,24 @@
+# 6.5840: Distributed Systems
+
+---
+
+Announcements:
+Jan 25: Please use Piazza to read announcements and ask and answer questions about labs, lectures, and papers.
+
+What is 6.5840 about?
+6.5840 is a core 12-unit graduate subject with lectures, readings, programming labs, an optional project, a mid-term exam, and a final exam. It will present abstractions and implementation techniques for engineering distributed systems. Major topics include fault tolerance, replication, and consistency. Much of the class consists of studying and discussing case studies of distributed systems.
+
+Prerequisites: 6.1910 (6.004) and one of 6.1800 (6.033) or 6.1810, or equivalent. Substantial programming experience will be helpful for the lab assignments.
+
+---
+
+[1. Information](./docs/6.5840%3A%20Distributed%20System/1.%20Information.md)
+[2. Lab Guidance](./docs/6.5840%3A%20Distributed%20System/2.%20Lab%20Guidance.md)
+[3. Lab 1: MapReduce](./docs/6.5840%3A%20Distributed%20System/3.%20Lab%201%3A%20MapReduce.md)
+[4. Lab 2: Key-Value Server](./docs/6.5840%3A%20Distributed%20System/4.%20Lab%202%3A%20Key-Value%20Server.md)
+[5. Lab 3: Raft](./docs/6.5840%3A%20Distributed%20System/5.%20Lab%203%3A%20Raft.md)
+[6. Lab 4: Fault-tolerant Key-Value Service](./docs/6.5840%3A%20Distributed%20System/6.%20Lab%204%3A%20Fault-tolerant%20Key-Value%20Service.md)
+[7. Lab 5: Sharded Key-Value Service](./docs/6.5840%3A%20Distributed%20System/7.%20Lab%205%3A%20Sharded%20Key-Value%20Service.md)
+
+--
+*From: [6.5840: Distributed Systems](https://pdos.csail.mit.edu/6.824/index.html)*
\ No newline at end of file
diff --git a/README.zh-CN.md b/README.zh-CN.md
new file mode 100644
index 0000000..b39de49
--- /dev/null
+++ b/README.zh-CN.md
@@ -0,0 +1,24 @@
+# 6.5840: Distributed Systems
+
+---
+
+公告:
+1 月 25 日:请使用 Piazza 查看公告,并就实验、课程与论文提问与回答。
+
+6.5840 讲什么?
+6.5840 是一门 12 学分的核心研究生课程,包含课堂讲授、阅读、编程实验、可选项目、期中考试与期末考试。课程介绍构建分布式系统所用的抽象与实现技术。主要议题包括容错、复制与一致性。课程相当一部分是对分布式系统案例的学习与讨论。
+
+先修要求:6.1910(6.004)以及 6.1800(6.033)或 6.1810 之一,或同等水平。具备较多编程经验对完成实验会有帮助。
+
+---
+
+[1. Information](./docs/6.5840%3A%20Distributed%20System/1.%20Information-cn.md)
+[2. Lab Guidance](./docs/6.5840%3A%20Distributed%20System/2.%20Lab%20Guidance-cn.md)
+[3. Lab 1: MapReduce](./docs/6.5840%3A%20Distributed%20System/3.%20Lab%201%3A%20MapReduce-cn.md)
+[4. Lab 2: Key-Value Server](./docs/6.5840%3A%20Distributed%20System/4.%20Lab%202%3A%20Key-Value%20Server-cn.md)
+[5. Lab 3: Raft](./docs/6.5840%3A%20Distributed%20System/5.%20Lab%203%3A%20Raft-cn.md)
+[6. Lab 4: Fault-tolerant Key-Value Service](./docs/6.5840%3A%20Distributed%20System/6.%20Lab%204%3A%20Fault-tolerant%20Key-Value%20Service-cn.md)
+[7. Lab 5: Sharded Key-Value Service](./docs/6.5840%3A%20Distributed%20System/7.%20Lab%205%3A%20Sharded%20Key-Value%20Service-cn.md)
+
+--
+*来源: [6.5840: Distributed Systems](https://pdos.csail.mit.edu/6.824/index.html)*
diff --git a/docs/6.5840: Distributed System/1. Information-cn.md b/docs/6.5840: Distributed System/1. Information-cn.md
new file mode 100644
index 0000000..1c5d4a0
--- /dev/null
+++ b/docs/6.5840: Distributed System/1. Information-cn.md
@@ -0,0 +1,94 @@
+# 课程基本信息
+
+## 课程结构
+
+6.5840 是一门 12 学分的核心研究生课程,包含课堂讲授、实验、可选项目、期中考试和期末考试。
+
+课程于 TR1-2:30 在 54-100 教室线下进行。多数课堂将部分用于讲授、部分用于论文讨论。你应在课前阅读指定论文并准备参与讨论。课表会标明每次课对应的论文。
+
+我们将在课表上每篇论文对应课程开始前 24 小时发布一个关于该论文的问题(见每篇论文的 Question 链接)。你的回答只需足够长以表明你理解了论文,通常一两段即可。我们不会逐条反馈,但会浏览你的回答以确认言之有理,这些回答会计入成绩。若对论文有疑问,你也可以(可选)提交问题;我们可能会回答和/或调整讲授内容以解答。
+
+6.5840 将在正常上课时间进行期中考试,在期末考试周进行期末考试。你必须参加两场考试。考试不设补考或冲突时段。若选修 6.5840,请勿选修与上课时间冲突的其他课程。
+
+本学期每隔一两周会有编程实验截止。实验旨在帮助你更深入理解 6.5840 中讨论的部分思想;更一般的目标是让你积累分布式系统编程与调试经验。学期中我们会要求你参加五次随机抽取实验的检查会,届时我们会就你的实验代码如何工作提问。
+
+学期末你可以在基于自己想法的期末项目与做 Lab 5 之间二选一。若选择做项目,须组成 2–3 人小组,项目须与 6.5840 主题紧密相关,且须事先经我们批准。你需要提交简短的项目提案;若获批准,则设计并实现系统;学期末提交结果摘要(我们会公布)与代码,并在课上做简短展示与演示。
+
+要在 6.5840 中取得好成绩,你应已具备 6.1910(6.004)水平的计算机系统基础,以及 6.1800(6.033)或 6.1810 至少其一,并擅长调试、实现与设计软件,例如修读过 6.1810、6.1100(6.035)等编程密集型课程。
+
+---
+
+## 成绩评定
+
+最终成绩由以下部分构成:
+- 40% 实验(编程作业),含可选项目
+- 20% 期中考试
+- 20% 期末考试
+- 15% 实验检查
+- 5% 论文问题回答
+- 各次实验提交按完成该作业所给周数(不含开学第一周、期中周和春假周)加权。
+
+为应对突发情况,Lab 1、2、3、4 和 5A 可以迟交,但所有实验迟交时间总和不得超过 72 小时。这 72 小时可在各次实验间任意分配,无需事先告知我们。迟交时长仅适用于 Lab 1、2、3、4 和 5A;不能用于 Lab 5B–D 或项目的任何部分。
+
+若某次实验迟交,且你的总迟交时间(含该次)超过 72 小时,但在学期最后一天前提交,我们将按按时提交所得分数的一半给分。若迟交超过 72 小时仍希望我们批改,请发邮件说明。无论迟交时长多少,学期最后一天之后我们不再接受任何作业。若在学期最后一天前未提交某次作业,该次作业记零分。
+
+若需豁免上述规则,请让 S3 向我们发送说明函。
+
+---
+
+## 合作政策
+
+请独立完成课程实验:欢迎与他人讨论实验内容,但请勿查看或提交他人代码。若考虑用 AI 助手代写代码,请注意你会相应减少从实验中的学习。无论如何,我们要求你理解并能解释所提交的全部代码,并能回答考试中与实验相关的问题。
+
+请勿公开你的代码或提供给当前或未来的 6.5840 学生。github.com 上仓库默认公开,因此除非将仓库设为私有,否则请勿将代码放在该处。使用 MIT 的 GitHub 时请务必创建私有仓库。
+
+论文问题可与他人讨论,但不得查看他人答案。答案必须由本人撰写。
+
+## 课程人员
+
+有关课程的问题或意见请发至 6824-staff@lists.csail.mit.edu。
+
+### 主讲教师
+
+Frans Kaashoek 32-G992 kaashoek@csail.mit.edu
+
+Robert Morris 32-G972 rtm@csail.mit.edu
+
+### 助教
+
+Baltasar Dinis
+
+Ayana Alemayehu
+
+Upamanyu Sharma
+
+Yun-Sheng Chang
+
+Danny Villanueva
+
+Brian Shi
+
+Nour Massri
+
+Beshr Islam Bouli
+
+---
+
+## 答疑时间
+
+日期 时间 地点 助教
+
+待定
+
+如需在所列答疑时间之外与课程人员见面,可通过邮件或私人 Piazza 帖子预约。
+
+---
+
+## 致谢
+
+6.5840 课程材料的很大一部分由 Robert Morris、Frans Kaashoek 和 Nickolai Zeldovich 开发。该课程在 2023 年前名为 6.824。
+
+有关 6.5840 的问题或意见?请发送邮件至 6824-staff@lists.csail.mit.edu。
+
+---
+*来源: [General Information](https://pdos.csail.mit.edu/6.824/general.html)*
diff --git a/docs/6.5840: Distributed System/1. Information.md b/docs/6.5840: Distributed System/1. Information.md
new file mode 100644
index 0000000..d7e059b
--- /dev/null
+++ b/docs/6.5840: Distributed System/1. Information.md
@@ -0,0 +1,94 @@
+# General Information
+
+## Structure
+
+6.5840 is a 12-unit core graduate subject with lectures, labs, an optional project, a mid-term exam, and a final exam.
+
+Class meets TR1-2:30 in person in 54-100. Most class meetings will be part lecture and part paper discussion. You should read the paper before coming to class, and be prepared to discuss it. The schedule indicates the paper to read for each meeting.
+
+We will post a question about each paper 24 hours before the beginning of class on the schedule (see the Question link for each paper). Your answer need only be long enough to demonstrate that you understand the paper; a paragraph or two will usually be enough. We won't give feedback, but we will glance at your answers to make sure they make sense, and they will contribute to your grade. If you have a question about a paper, you may also (optionally) submit it; we may answer and/or adjust the lecture to answer your question.
+
+6.5840 will have a midterm exam during the ordinary lecture time, and a final exam during finals week. You must attend both exams. There will be no make-up or alternate conflict times for the exams. If you take 6.5840, please do not register for any other class with a conflicting lecture time.
+
+There are programming labs due every week or two throughout the term. The labs will help you understand more deeply some of the ideas discussed in 6.5840; a more general goal is for you to gain experience programming and debugging distributed systems. During the semester we will ask you to attend five check-off meetings, for randomly chosen labs, in which we will ask you questions about how your lab code works.
+
+Towards the end of the term you can choose between doing a final project based on your own ideas, or doing Lab 5. If you want to do a project, you must form a team of two or three people, the project must be closely related to 6.5840 topics, and we must approve it in advance. You'll hand in a short project proposal, and, if we approve, you'll design and build a system; at the end of the term you'll hand in a summary of your results (which we'll post) and your code, and do a short presentation and demo in class.
+
+To do well in 6.5840, you should already be familiar with computer systems to the level of 6.1910 (6.004) and at least one of 6.1800 (6.033) or 6.1810, and you should be good at debugging, implementing, and designing software, perhaps as a result of taking programming-intensive courses such as 6.1810 and 6.1100 (6.035).
+
+---
+
+## Grading
+
+Final course grades will be based on:
+- 40% labs (programming assignments), including optional project
+- 20% mid-term exam
+- 20% final exam
+- 15% lab check-offs
+- 5% paper question answers
+- Each lab submission is weighted proportionally to the number of weeks that you have to complete the assignment, excluding the first week of classes, midterm week, and spring break week.
+
+To help you cope with unexpected emergencies, you can hand in your Lab 1, 2, 3, 4, and 5A solutions late, but the total amount of lateness summed over all the lab deadlines must not exceed 72 hours. You can divide up your 72 hours among the labs however you like; you don't have to ask or tell us. You can only use late hours for Labs 1, 2, 3, 4, and 5A; you cannot use late hours for Lab 5B-D or for any aspect of the project.
+
+If you hand a lab in late, and your total late time (including the late time for that assignment) exceeds 72 hours, and you hand it in by the last day of classes, then we'll give it half the credit we would have given if you had handed it in on time. Please send us e-mail if you want us to grade an assignment that's more than 72 hours late. We will not accept any work after the last day of classes, regardless of late hours. If you don't hand in an assignment by the last day of classes, we'll give the assignment zero credit.
+
+If you want an exception to these rules, please ask S3 to send us an excuse note.
+
+---
+
+## Collaboration policy
+Please do the course labs individually: you are welcome to discuss the labs with others, but please do not look at (or hand in) anyone else's solution. If you are tempted to use an AI assistant to write code for you, consider that you'll then learn correspondingly less from the labs. Regardless, we will expect you to understand and be able to explain all of the code that you hand in, and to be able to reason about lab-related questions on the exams.
+
+Please do not publish your code or make it available to current or future 6.5840 students. github.com repositories are public by default, so please don't put your code there unless you make the repository private. You may find it convenient to use MIT's GitHub, but be sure to create a private repository.
+
+You may discuss the paper questions with other students, but you may not look at other students' answers. You must write your answers yourself.
+
+
+## Staff
+
+Please use 6824-staff@lists.csail.mit.edu to send questions or comments about the course to the staff.
+
+### Lecturer
+
+Frans Kaashoek 32-G992 kaashoek@csail.mit.edu
+
+Robert Morris 32-G972 rtm@csail.mit.edu
+
+### Teaching assistants
+
+Baltasar Dinis
+
+Ayana Alemayehu
+
+Upamanyu Sharma
+
+Yun-Sheng Chang
+
+Danny Villanueva
+
+Brian Shi
+
+Nour Massri
+
+Beshr Islam Bouli
+
+---
+
+## Office hours
+
+Day Time Location TA
+
+TBD
+
+Appointments with staff outside of the listed office hours can be setup via email or private Piazza post.
+
+---
+
+## Acknowledgements
+
+Robert Morris, Frans Kaashoek, and Nickolai Zeldovich developed much of the 6.5840 course material. The course was called 6.824 before 2023.
+
+Questions or comments regarding 6.5840? Send e-mail to 6824-staff@lists.csail.mit.edu.
+
+---
+*From: [General Information](https://pdos.csail.mit.edu/6.824/general.html)*
\ No newline at end of file
diff --git a/docs/6.5840: Distributed System/2. Lab Guidance-cn.md b/docs/6.5840: Distributed System/2. Lab Guidance-cn.md
new file mode 100644
index 0000000..6c0b301
--- /dev/null
+++ b/docs/6.5840: Distributed System/2. Lab Guidance-cn.md
@@ -0,0 +1,48 @@
+# 实验指南
+
+---
+
+## 作业难度
+
+每个实验任务都标有大致预计用时:
+
+* **Easy(简单)**:数小时。
+* **Moderate(中等)**:约每周 6 小时。
+* **Hard(困难)**:每周超过 6 小时。若起步较晚,你的实现很可能无法通过全部测试。
+
+多数实验只需适度的代码量(每个实验部分可能几百行),但**概念上可能较难**,需要较多思考和调试。部分测试较难通过。
+
+**不要在截止前一晚才开始做实验**;分多天、多次完成会更高效。由于并发、崩溃和不可靠网络,在分布式系统中排查 bug 较为困难。
+
+---
+
+## 提示
+
+* 完成 [Go 在线教程](https://go.dev/tour/)并参考 [Effective Go](https://go.dev/doc/effective_go)。参见 [Editors](https://go.dev/doc/editors.html) 配置 Go 编辑器。
+* 实验的 Makefile 已配置为使用 Go 的 **race detector**。请修复其报告的所有数据竞争。参见 [race detector 博客文章](https://go.dev/blog/race-detector)。
+* 实验中的 [加锁建议](../papers/raft-locking-cn.txt)。
+* [Raft 实验结构建议](../papers/raft-structure-cn.txt)。
+* 该 [Raft 交互示意图](../papers/raft_diagram.pdf) 有助于理解系统各部分之间的代码流程。
+* 学习 Go 的 Printf 格式字符串:[Go format strings](https://pkg.go.dev/fmt)。
+* 进一步了解 git,可参阅 [Pro Git 书](https://git-scm.com/book/en/v2) 或 [git 用户手册](https://git-scm.com/docs/user-manual)。
+
+---
+
+## 调试
+
+高效调试需要经验。**系统化**会很有帮助:对可能原因形成假设;收集可能相关的证据;分析已收集的信息;按需重复。长时间调试时做笔记有助于积累证据并提醒自己为何排除之前的假设。
+
+最有效的调试方法之一往往是在代码中**添加 print 语句**,运行失败的测试并将输出保存到文件,然后浏览输出找出开始出错的位置。可能需多轮迭代,随问题更清晰而增加更多 print。
+
+不同节点之间以及同一节点内多线程的**并发**会使操作以意想不到的方式交错。例如,前一个 leader 仍认为自己是 leader 时,某个 Raft 节点可能已被选为新 leader;或 leader 发出 RPC 但在失去 leader 身份后才收到回复。添加 print 有助于发现这类情况。
+
+可以**查看测试代码**(`mr/mt_test.go`、`raft1/raft_test.go` 等)以理解测试在测什么。可以在测试中加 print 帮助理解其行为及失败原因,但**提交前请确保你的代码在原始测试代码下能通过**。
+
+Raft 论文的 **Figure 2** 必须较为严格地遵守。很容易漏掉 Figure 2 要求检查的条件或要求发生的状态变化。若有 bug,**请再次核对你的代码是否严格遵循 Figure 2**。
+
+在写代码时(即尚未出现 bug 时),对代码假定成立的条件添加**显式检查**可能很有用,例如使用 Go 的 [panic](https://go.dev/blog/defer-panic-and-recover)。这类检查有助于发现后续代码无意违反假设的情况。
+
+助教乐于在答疑时间帮你思考代码,但若你**已经尽可能深入分析过**,有限的答疑时间才能发挥最大作用。
+
+---
+*来源: [Lab guidance](https://pdos.csail.mit.edu/6.824/labs/guidance.html)*
diff --git a/docs/6.5840: Distributed System/2. Lab Guidance.md b/docs/6.5840: Distributed System/2. Lab Guidance.md
new file mode 100644
index 0000000..caf1ed4
--- /dev/null
+++ b/docs/6.5840: Distributed System/2. Lab Guidance.md
@@ -0,0 +1,48 @@
+# Lab Guidance
+
+---
+
+## Hardness of Assignments
+
+Each lab task is tagged to indicate roughly how long we expect the task to take:
+
+* **Easy**: A few hours.
+* **Moderate**: ~ 6 hours (per week).
+* **Hard**: More than 6 hours (per week). If you start late, your solution is unlikely to pass all tests.
+
+Most of the labs require only a modest amount of code (perhaps a few hundred lines per lab part), but can be **conceptually difficult** and may require a good deal of thought and debugging. Some of the tests are difficult to pass.
+
+**Don't start a lab the night before it is due**; it's more efficient to do the labs in several sessions spread over multiple days. Tracking down bugs in distributed systems is difficult, because of concurrency, crashes, and an unreliable network.
+
+---
+
+## Tips
+
+* Do the [Online Go tutorial](https://go.dev/tour/) and consult [Effective Go](https://go.dev/doc/effective_go). See [Editors](https://go.dev/doc/editors.html) to set up your editor for Go.
+* The lab Makefiles are set up to use Go's **race detector**. Fix any races it reports. See the [race detector blog post](https://go.dev/blog/race-detector).
+* Advice on [locking](../papers/raft-locking.txt) in labs.
+* Advice on [structuring your Raft lab](../papers/raft-structure.txt).
+* This [Diagram of Raft interactions](../papers/raft_diagram.pdf) may help you understand code flow between different parts of the system.
+* Learn about Go's Printf format strings: [Go format strings](https://pkg.go.dev/fmt).
+* To learn more about git, look at the [Pro Git book](https://git-scm.com/book/en/v2) or the [git user's manual](https://git-scm.com/docs/user-manual).
+
+---
+
+## Debugging
+
+Efficient debugging takes experience. It helps to be **systematic**: form a hypothesis about a possible cause of the problem; collect evidence that might be relevant; think about the information you've gathered; repeat as needed. For extended debugging sessions it helps to keep notes, both to accumulate evidence and to remind yourself why you've discarded specific earlier hypotheses.
+
+The most effective debugging technique is often to **add print statements** to your code, run the test that is failing and collect the print output in a file, and then look through the output file to identify the point at which things start to go wrong. You may need to iterate, adding more print statements as you learn more about what is going wrong.
+
+**Concurrency** among different peers and among the threads in a single peer can cause actions to be interleaved in unexpected ways. For example, it's quite possible for a Raft peer to be elected leader while the previous leader still thinks it is the leader, or for a leader to send an RPC but receive the reply after it has lost leadership. Adding print statements may help you spot such situations.
+
+Feel free to **examine the test code** (`mr/mt_test.go`, `raft1/raft_test.go`, &c) to understand what the tests are exploring. You can add print statements to the tests to help you understand what they are doing and why they are failing, but **be sure your code passes with the original test code before submitting**.
+
+The Raft paper's **Figure 2** must be followed fairly exactly. It is easy to miss a condition that Figure 2 says must be checked, or a state change that it says must be made. If you have a bug, **re-check that all of your code adheres closely to Figure 2**.
+
+As you're writing code (i.e., before you have a bug), it may be worth adding **explicit checks** for conditions that the code assumes to be true, perhaps using Go's [panic](https://go.dev/blog/defer-panic-and-recover). Such checks may help detect situations where later code unwittingly violates the assumptions.
+
+The TAs are happy to help you think about your code during office hours, but you're likely to get the most mileage out of limited office hour time if you've **already dug as deep as you can** into the situation.
+
+---
+*From: [Lab guidance](https://pdos.csail.mit.edu/6.824/labs/guidance.html)*
diff --git a/docs/6.5840: Distributed System/3. Lab 1: MapReduce-cn.md b/docs/6.5840: Distributed System/3. Lab 1: MapReduce-cn.md
new file mode 100644
index 0000000..269c052
--- /dev/null
+++ b/docs/6.5840: Distributed System/3. Lab 1: MapReduce-cn.md
@@ -0,0 +1,221 @@
+# 6.5840 Lab 1: MapReduce
+
+## 简介
+
+在本实验中你将实现一个 MapReduce 系统。你需要实现:调用应用 Map 和 Reduce 函数并负责读写文件的 worker 进程,以及向 worker 分配任务并应对 worker 失败的 coordinator 进程。你将实现与 [MapReduce 论文](../papers/mapreduce-cn.md) 中类似的内容。(注:本实验使用 "coordinator" 代替论文中的 "master"。)
+
+## 起步
+
+你需要先安装并配置 Go 才能完成实验。
+
+用 git 获取初始实验代码。进一步了解 git 可参阅 [Pro Git 书](https://git-scm.com/book/en/v2) 或 [git 用户手册](https://git-scm.com/docs/user-manual)。
+
+```bash
+$ git clone git://g.csail.mit.edu/6.5840-golabs-2026 6.5840
+$ cd 6.5840
+$ ls
+Makefile src
+$
+```
+
+我们在 `src/main/mrsequential.go` 中提供了一个简单的单进程顺序 MapReduce 实现,在一个进程内逐个执行 map 和 reduce。我们还提供了若干 MapReduce 应用:`mrapps/wc.go` 中的词频统计,以及 `mrapps/indexer.go` 中的文本索引。可以按如下方式顺序运行词频统计:
+
+```bash
+$ cd ~/6.5840
+$ cd src/main
+$ go build -buildmode=plugin ../mrapps/wc.go
+$ rm mr-out*
+$ go run mrsequential.go wc.so pg*.txt
+$ sort mr-out-0
+A 509
+ABOUT 2
+ACT 8
+ACTRESS 1
+...
+```
+
+(若希望 sort 产生上述输出,可能需设置环境变量 `LC_COLLATE=C`:`LC_COLLATE=C sort mr-out-0`)
+
+`mrsequential.go` 将输出写入文件 `mr-out-0`。输入来自名为 `pg-xxx.txt` 的文本文件。
+
+可以复用 `mrsequential.go` 中的代码。也可查看 `mrapps/wc.go` 了解 MapReduce 应用代码的形式。
+
+对本实验及后续实验,我们可能会对提供的代码进行更新。为便于用 `git pull` 获取并合并更新,建议保留我们提供的代码在原始文件中。你可以按实验说明在现有代码上增补,但不要移动它们。可以把你自己新增的函数放在新文件中。
+
+## 你的任务
+
+你的任务是实现一个分布式 MapReduce,包含两个程序:**coordinator** 和 **worker**。只有一个 coordinator 进程,以及一个或多个并行运行的 worker 进程。在实际系统中 worker 会运行在多台机器上,本实验中将全部在同一台机器上运行。Worker 通过 RPC 与 coordinator 通信。每个 worker 进程循环向 coordinator 请求任务,从若干文件中读取该任务的输入,执行任务,将输出写入若干文件,然后再次向 coordinator 请求新任务。Coordinator 应在合理时间内(本实验为十秒)检测 worker 是否未完成任务,并将同一任务交给其他 worker。
+
+我们已提供少量起步代码。Coordinator 和 worker 的 "main" 例程在 `main/mrcoordinator.go` 和 `main/mrworker.go` 中;**不要修改这两个文件**。你的实现应放在 `mr/coordinator.go`、`mr/worker.go` 和 `mr/rpc.go` 中。
+
+在词频统计 MapReduce 应用上运行你的代码的步骤。首先构建词频统计插件:
+
+```bash
+$ cd main
+$ go build -buildmode=plugin ../mrapps/wc.go
+```
+
+在一个终端中运行 coordinator:
+
+```bash
+$ rm mr-out*
+$ go run mrcoordinator.go sock123 pg-*.txt
+```
+
+参数 `sock123` 指定 coordinator 接收 worker RPC 的 socket。传给 `mrcoordinator.go` 的 `pg-*.txt` 是输入文件;每个文件对应一个 "split",即一个 Map 任务的输入。
+
+在另一个或多个终端中运行若干 worker:
+
+```bash
+$ go run mrworker.go wc.so sock123
+```
+
+当 worker 和 coordinator 都结束后,查看 `mr-out-*` 中的输出。完成实验后,对所有输出文件排序后的并集应与顺序实现的输出一致,例如:
+
+```bash
+$ cat mr-out-* | sort | more
+A 509
+ABOUT 2
+ACT 8
+ACTRESS 1
+...
+```
+
+我们提供了批改时将使用的全部测试。测试源码在 `mr/mr_test.go`。可在 src 目录下运行测试:
+
+```bash
+$ cd src
+$ make mr
+...
+```
+
+测试会检查:在给定 pg-xxx.txt 作为输入时,wc 和 indexer 两个 MapReduce 应用是否产生正确输出;你的实现是否并行执行 Map 和 Reduce 任务;以及是否能在运行任务的 worker 崩溃后恢复。
+
+若现在运行测试,会在第一个测试中卡住:
+
+```bash
+$ cd ~/6.5840/src
+$ make mr
+...
+cd mr; go test -v -race
+=== RUN TestWc
+...
+```
+
+你可以把 `mr/coordinator.go` 中 `Done` 函数里的 `ret := false` 改为 `true`,这样 coordinator 会立即退出。然后:
+
+```bash
+$ make mr
+...
+=== RUN TestWc
+2026/01/22 14:56:24 reduce created no mr-out-X output files!
+exit status 1
+FAIL 6.5840/mr 4.516s
+make: *** [Makefile:44: mr] Error 1
+$
+```
+
+测试期望看到名为 `mr-out-X` 的输出文件,每个 reduce 任务一个。`mr/coordinator.go` 和 `mr/worker.go` 的空实现不会生成这些文件(也几乎不做别的事),因此测试会失败。
+
+完成后,测试输出应类似:
+
+```bash
+$ make mr
+...
+=== RUN TestWc
+--- PASS: TestWc (8.64s)
+=== RUN TestIndexer
+--- PASS: TestIndexer (5.90s)
+=== RUN TestMapParallel
+--- PASS: TestMapParallel (7.05s)
+=== RUN TestReduceParallel
+--- PASS: TestReduceParallel (8.05s)
+=== RUN TestJobCount
+--- PASS: TestJobCount (10.04s)
+=== RUN TestEarlyExit
+--- PASS: TestEarlyExit (6.05s)
+=== RUN TestCrashWorker
+2026/01/22 14:58:14 *re*-starting map ../../main/pg-tom_sawyer.txt 0
+2026/01/22 14:58:14 *re*-starting map ../../main/pg-metamorphosis.txt 2
+2026/01/22 14:58:39 *re*-starting map ../../main/pg-metamorphosis.txt 2
+2026/01/22 14:58:40 map 2 already done
+2026/01/22 14:58:45 *re*-starting reduce 0
+--- PASS: TestCrashWorker (40.18s)
+PASS
+ok 6.5840/mr 86.932s
+$
+```
+
+根据你终止 worker 进程的方式,可能会看到类似错误:
+
+```
+2026/02/11 16:21:32 dialing:dial unix /var/tmp/5840-mr-501: connect: connection refused
+```
+
+每个测试中出现少量这类消息是可以的;它们出现在 coordinator 已退出后 worker 无法联系到 coordinator 的 RPC 服务时。
+
+## 若干规则
+
+- Map 阶段应将中间 key 划分到 **nReduce** 个 reduce 任务的桶中,其中 nReduce 是 reduce 任务数量,即 `main/mrcoordinator.go` 传给 `MakeCoordinator()` 的参数。每个 mapper 应为 reduce 任务创建 nReduce 个中间文件。
+- Worker 实现应把第 X 个 reduce 任务的输出放在文件 **mr-out-X** 中。
+- **mr-out-X** 文件应包含 Reduce 函数输出的每一行。该行应由 Go 的 `"%v %v"` 格式生成,传入 key 和 value。可参考 `main/mrsequential.go` 中注释为 "this is the correct format" 的那行。若你的实现与该格式偏差过大,测试会失败。
+- 可以修改 `mr/worker.go`、`mr/coordinator.go` 和 `mr/rpc.go`。可以临时修改其他文件做测试,但须确保在原始版本下你的代码能正确运行;我们会用原始版本测试。
+- Worker 应将 Map 的中间输出放在当前目录的文件中,以便之后在 Reduce 任务中读取。
+- `main/mrcoordinator.go` 期望 `mr/coordinator.go` 实现 **Done()** 方法,在 MapReduce 作业完全结束时返回 true;此时 mrcoordinator.go 会退出。
+- 当作业完全结束时,worker 进程应退出。一种简单做法是利用 `call()` 的返回值:若 worker 无法联系到 coordinator,可认为 coordinator 因作业结束已退出,于是 worker 也可终止。根据你的设计,也可以让 coordinator 给 worker 一个 "please exit" 的伪任务。
+
+## 提示
+
+- [Guidance](./2.%20Lab%20Guidance-cn.md) 页有一些开发和调试建议。
+- 一种起步方式是修改 `mr/worker.go` 的 `Worker()`,向 coordinator 发 RPC 请求任务。然后修改 coordinator,用尚未开始的 map 任务的文件名回复。再修改 worker 读取该文件并调用应用的 Map 函数,如 `mrsequential.go` 中所示。
+- 应用的 Map 和 Reduce 函数在运行时通过 Go 的 plugin 包从以 `.so` 结尾的文件加载。
+- 若修改了 `mr/` 目录下的任何内容,很可能需要重新构建所用 MapReduce 插件,例如 `go build -buildmode=plugin ../mrapps/wc.go`。`make mr` 会为你构建插件。可用 `make RUN="-run Wc" mr` 运行单个测试,该命令会把 `-run Wc` 传给 go test,只运行 `mr/mr_test.go` 中匹配 Wc 的测试。
+- 本实验依赖 worker 共享文件系统。所有 worker 在同一台机器上时很简单;若 worker 在不同机器上,则需要 GFS 之类的全局文件系统。
+- 中间文件的合理命名是 **mr-X-Y**,其中 X 为 Map 任务编号,Y 为 reduce 任务编号。
+- Worker 的 map 任务代码需要一种方式将中间 key/value 对写入文件,以便在 reduce 任务中正确读回。一种做法是使用 Go 的 `encoding/json` 包。将 key/value 对以 JSON 格式写入已打开的文件:
+
+ ```go
+ enc := json.NewEncoder(file)
+ for _, kv := ... {
+ err := enc.Encode(&kv)
+ }
+ ```
+
+ 读回该文件:
+
+ ```go
+ dec := json.NewDecoder(file)
+ for {
+ var kv KeyValue
+ if err := dec.Decode(&kv); err != nil {
+ break
+ }
+ kva = append(kva, kv)
+ }
+ ```
+
+- Worker 的 map 部分可使用 **ihash(key)** 函数(在 worker.go 中)为给定 key 选择对应的 reduce 任务。
+- 可从 `mrsequential.go` 借鉴读取 Map 输入文件、在 Map 和 Reduce 之间排序中间 key/value 对、以及将 Reduce 输出写入文件的代码。
+- Coordinator 作为 RPC 服务器是并发的;别忘了**对共享数据加锁**。
+- Worker 有时需要等待,例如 reduce 须等最后一个 map 完成才能开始。一种做法是 worker 周期性地向 coordinator 请求工作,每次请求之间用 `time.Sleep()` 休眠。另一种做法是 coordinator 中相应的 RPC 处理函数里用循环等待,可用 `time.Sleep()` 或 `sync.Cond`。Go 为每个 RPC 在独立线程中运行处理函数,因此一个处理函数在等待不会阻止 coordinator 处理其他 RPC。
+- Coordinator 无法可靠区分崩溃的 worker、存活但卡住的 worker、以及执行过慢的 worker。能做的是让 coordinator 等待一段时间后放弃,并把任务重新发给其他 worker。本实验中请让 coordinator 等待**十秒**;之后应假定该 worker 已死(当然也可能没死)。
+- 若选择实现 Backup Tasks(论文 3.6 节),请注意我们测试在 worker 不崩溃时你的代码不会调度多余任务。Backup tasks 应只在相对较长时间(例如 10 秒)后才调度。
+- 测试崩溃恢复可使用 **mrapps/crash.go** 应用插件,它会在 Map 和 Reduce 函数中随机退出。
+- 为确保在崩溃情况下无人看到未写完的文件,MapReduce 论文提到使用临时文件并在完全写完后原子重命名的技巧。可用 `ioutil.TempFile`(或 Go 1.17 及以上的 `os.CreateTemp`)创建临时文件,用 `os.Rename` 原子重命名。
+- Go RPC 只发送**首字母大写**的 struct 字段名。子结构体的字段名也须大写。
+- 调用 RPC 的 `call()` 时,reply 结构体应包含全部默认值。RPC 调用应类似:
+
+ ```go
+ reply := SomeType{}
+ call(..., &reply)
+ ```
+
+ 在 call 之前不要设置 reply 的任何字段。若传入的 reply 结构体含有非默认字段,RPC 系统可能静默返回错误值。
+
+## 不计分挑战
+
+- 实现你自己的 MapReduce 应用(参考 `mrapps/*` 中的示例),例如分布式 Grep(MapReduce 论文 2.3 节)。
+- 让 MapReduce coordinator 和 worker 在不同机器上运行,与实际部署一致。需要将 RPC 改为通过 TCP/IP 而非 Unix socket 通信(参见 `Coordinator.server()` 中的注释行),并通过共享文件系统读写文件。例如可 ssh 到 MIT 的多台 Athena 集群机器,它们使用 AFS 共享文件;或租用几台 AWS 实例并用 S3 存储。
+
+---
+*来源: [6.5840 Lab 1: MapReduce](https://pdos.csail.mit.edu/6.824/labs/lab-mr.html)*
diff --git a/docs/6.5840: Distributed System/3. Lab 1: MapReduce.md b/docs/6.5840: Distributed System/3. Lab 1: MapReduce.md
new file mode 100644
index 0000000..4606b3f
--- /dev/null
+++ b/docs/6.5840: Distributed System/3. Lab 1: MapReduce.md
@@ -0,0 +1,221 @@
+# 6.5840 Lab 1: MapReduce
+
+## Introduction
+
+In this lab you'll build a MapReduce system. You'll implement a worker process that calls application Map and Reduce functions and handles reading and writing files, and a coordinator process that hands out tasks to workers and copes with failed workers. You'll be building something similar to the [MapReduce paper](../papers/mapreduce.md). (Note: this lab uses "coordinator" instead of the paper's "master".)
+
+## Getting started
+
+You need to setup Go to do the labs.
+
+Fetch the initial lab software with git (a version control system). To learn more about git, look at the [Pro Git book](https://git-scm.com/book/en/v2) or the [git user's manual](https://git-scm.com/docs/user-manual).
+
+```bash
+$ git clone git://g.csail.mit.edu/6.5840-golabs-2026 6.5840
+$ cd 6.5840
+$ ls
+Makefile src
+$
+```
+
+We supply you with a simple sequential mapreduce implementation in `src/main/mrsequential.go`. It runs the maps and reduces one at a time, in a single process. We also provide you with a couple of MapReduce applications: word-count in `mrapps/wc.go`, and a text indexer in `mrapps/indexer.go`. You can run word count sequentially as follows:
+
+```bash
+$ cd ~/6.5840
+$ cd src/main
+$ go build -buildmode=plugin ../mrapps/wc.go
+$ rm mr-out*
+$ go run mrsequential.go wc.so pg*.txt
+$ sort mr-out-0
+A 509
+ABOUT 2
+ACT 8
+ACTRESS 1
+...
+```
+
+(You might need to set `LC_COLLATE=C` environment variable for sort to produce the above output: `LC_COLLATE=C sort mr-out-0`)
+
+`mrsequential.go` leaves its output in the file `mr-out-0`. The input is from the text files named `pg-xxx.txt`.
+
+Feel free to borrow code from `mrsequential.go`. You should also have a look at `mrapps/wc.go` to see what MapReduce application code looks like.
+
+For this lab and all the others, we might issue updates to the code we provide you. To ensure that you can fetch those updates and easily merge them using `git pull`, it's best to leave the code we provide in the original files. You can add to the code we provide as directed in the lab write-ups; just don't move it. It's OK to put your own new functions in new files.
+
+## Your Job
+
+Your job is to implement a distributed MapReduce, consisting of two programs, the **coordinator** and the **worker**. There will be just one coordinator process, and one or more worker processes executing in parallel. In a real system the workers would run on a bunch of different machines, but for this lab you'll run them all on a single machine. The workers will talk to the coordinator via RPC. Each worker process will, in a loop, ask the coordinator for a task, read the task's input from one or more files, execute the task, write the task's output to one or more files, and again ask the coordinator for a new task. The coordinator should notice if a worker hasn't completed its task in a reasonable amount of time (for this lab, use ten seconds), and give the same task to a different worker.
+
+We have given you a little code to start you off. The "main" routines for the coordinator and worker are in `main/mrcoordinator.go` and `main/mrworker.go`; **don't change these files**. You should put your implementation in `mr/coordinator.go`, `mr/worker.go`, and `mr/rpc.go`.
+
+Here's how to run your code on the word-count MapReduce application. First, build the word-count plugin:
+
+```bash
+$ cd main
+$ go build -buildmode=plugin ../mrapps/wc.go
+```
+
+In one window, run the coordinator:
+
+```bash
+$ rm mr-out*
+$ go run mrcoordinator.go sock123 pg-*.txt
+```
+
+The `sock123` argument specifies a socket on which the coordinator receives RPCs from workers. The `pg-*.txt` arguments to `mrcoordinator.go` are the input files; each file corresponds to one "split", and is the input to one Map task.
+
+In one or more other windows, run some workers:
+
+```bash
+$ go run mrworker.go wc.so sock123
+```
+
+When the workers and coordinator have finished, look at the output in `mr-out-*`. When you've completed the lab, the sorted union of the output files should match the sequential output, like this:
+
+```bash
+$ cat mr-out-* | sort | more
+A 509
+ABOUT 2
+ACT 8
+ACTRESS 1
+...
+```
+
+We supply you with all the tests that we'll use to grade your submitted lab. The source code for the tests are in `mr/mr_test.go`. You can run the tests in the src directory:
+
+```bash
+$ cd src
+$ make mr
+...
+```
+
+The tests check that the wc and indexer MapReduce applications produce the correct output when given the pg-xxx.txt files as input. The tests also check that your implementation runs the Map and Reduce tasks in parallel, and that your implementation recovers from workers that crash while running tasks.
+
+If you run the tests now, they will hang in the first test:
+
+```bash
+$ cd ~/6.5840/src
+$ make mr
+...
+cd mr; go test -v -race
+=== RUN TestWc
+...
+```
+
+You can change `ret := false` to `true` in the `Done` function in `mr/coordinator.go` so that the coordinator exits immediately. Then:
+
+```bash
+$ make mr
+...
+=== RUN TestWc
+2026/01/22 14:56:24 reduce created no mr-out-X output files!
+exit status 1
+FAIL 6.5840/mr 4.516s
+make: *** [Makefile:44: mr] Error 1
+$
+```
+
+The tests expect to see output in files named `mr-out-X`, one for each reduce task. The empty implementations of `mr/coordinator.go` and `mr/worker.go` don't produce those files (or do much of anything else), so the test fails.
+
+When you've finished, the test output should look like this:
+
+```bash
+$ make mr
+...
+=== RUN TestWc
+--- PASS: TestWc (8.64s)
+=== RUN TestIndexer
+--- PASS: TestIndexer (5.90s)
+=== RUN TestMapParallel
+--- PASS: TestMapParallel (7.05s)
+=== RUN TestReduceParallel
+--- PASS: TestReduceParallel (8.05s)
+=== RUN TestJobCount
+--- PASS: TestJobCount (10.04s)
+=== RUN TestEarlyExit
+--- PASS: TestEarlyExit (6.05s)
+=== RUN TestCrashWorker
+2026/01/22 14:58:14 *re*-starting map ../../main/pg-tom_sawyer.txt 0
+2026/01/22 14:58:14 *re*-starting map ../../main/pg-metamorphosis.txt 2
+2026/01/22 14:58:39 *re*-starting map ../../main/pg-metamorphosis.txt 2
+2026/01/22 14:58:40 map 2 already done
+2026/01/22 14:58:45 *re*-starting reduce 0
+--- PASS: TestCrashWorker (40.18s)
+PASS
+ok 6.5840/mr 86.932s
+$
+```
+
+Depending on your strategy for terminating worker processes, you may see errors like:
+
+```
+2026/02/11 16:21:32 dialing:dial unix /var/tmp/5840-mr-501: connect: connection refused
+```
+
+It is fine to see a handful of these messages per test; they arise when the worker is unable to contact the coordinator RPC server after the coordinator has exited.
+
+## A few rules
+
+- The map phase should divide the intermediate keys into buckets for **nReduce** reduce tasks, where nReduce is the number of reduce tasks -- the argument that `main/mrcoordinator.go` passes to `MakeCoordinator()`. Each mapper should create nReduce intermediate files for consumption by the reduce tasks.
+- The worker implementation should put the output of the X'th reduce task in the file **mr-out-X**.
+- A **mr-out-X** file should contain one line per Reduce function output. The line should be generated with the Go `"%v %v"` format, called with the key and value. Have a look in `main/mrsequential.go` for the line commented "this is the correct format". The tests will fail if your implementation deviates too much from this format.
+- You can modify `mr/worker.go`, `mr/coordinator.go`, and `mr/rpc.go`. You can temporarily modify other files for testing, but make sure your code works with the original versions; we'll test with the original versions.
+- The worker should put intermediate Map output in files in the current directory, where your worker can later read them as input to Reduce tasks.
+- `main/mrcoordinator.go` expects `mr/coordinator.go` to implement a **Done()** method that returns true when the MapReduce job is completely finished; at that point, mrcoordinator.go will exit.
+- When the job is completely finished, the worker processes should exit. A simple way to implement this is to use the return value from `call()`: if the worker fails to contact the coordinator, it can assume that the coordinator has exited because the job is done, so the worker can terminate too. Depending on your design, you might also find it helpful to have a "please exit" pseudo-task that the coordinator can give to workers.
+
+## Hints
+
+- The [Guidance](./2.%20Lab%20Guidance.md) page has some tips on developing and debugging.
+- One way to get started is to modify `mr/worker.go`'s `Worker()` to send an RPC to the coordinator asking for a task. Then modify the coordinator to respond with the file name of an as-yet-unstarted map task. Then modify the worker to read that file and call the application Map function, as in `mrsequential.go`.
+- The application Map and Reduce functions are loaded at run-time using the Go plugin package, from files whose names end in `.so`.
+- If you change anything in the `mr/` directory, you will probably have to re-build any MapReduce plugins you use, with something like `go build -buildmode=plugin ../mrapps/wc.go`. `make mr` builds the plugins for you. You can run an individual test using `make RUN="-run Wc" mr`, which passes `-run Wc` to go test, and selects any test from `mr/mr_test.go` matching Wc.
+- This lab relies on the workers sharing a file system. That's straightforward when all workers run on the same machine, but would require a global filesystem like GFS if the workers ran on different machines.
+- A reasonable naming convention for intermediate files is **mr-X-Y**, where X is the Map task number, and Y is the reduce task number.
+- The worker's map task code will need a way to store intermediate key/value pairs in files in a way that can be correctly read back during reduce tasks. One possibility is to use Go's `encoding/json` package. To write key/value pairs in JSON format to an open file:
+
+ ```go
+ enc := json.NewEncoder(file)
+ for _, kv := ... {
+ err := enc.Encode(&kv)
+ }
+ ```
+
+ and to read such a file back:
+
+ ```go
+ dec := json.NewDecoder(file)
+ for {
+ var kv KeyValue
+ if err := dec.Decode(&kv); err != nil {
+ break
+ }
+ kva = append(kva, kv)
+ }
+ ```
+
+- The map part of your worker can use the **ihash(key)** function (in worker.go) to pick the reduce task for a given key.
+- You can steal some code from `mrsequential.go` for reading Map input files, for sorting intermediate key/value pairs between the Map and Reduce, and for storing Reduce output in files.
+- The coordinator, as an RPC server, will be concurrent; don't forget to **lock shared data**.
+- Workers will sometimes need to wait, e.g. reduces can't start until the last map has finished. One possibility is for workers to periodically ask the coordinator for work, sleeping with `time.Sleep()` between each request. Another possibility is for the relevant RPC handler in the coordinator to have a loop that waits, either with `time.Sleep()` or `sync.Cond`. Go runs the handler for each RPC in its own thread, so the fact that one handler is waiting needn't prevent the coordinator from processing other RPCs.
+- The coordinator can't reliably distinguish between crashed workers, workers that are alive but have stalled for some reason, and workers that are executing but too slowly to be useful. The best you can do is have the coordinator wait for some amount of time, and then give up and re-issue the task to a different worker. For this lab, have the coordinator wait for **ten seconds**; after that the coordinator should assume the worker has died (of course, it might not have).
+- If you choose to implement Backup Tasks (Section 3.6), note that we test that your code doesn't schedule extraneous tasks when workers execute tasks without crashing. Backup tasks should only be scheduled after some relatively long period of time (e.g., 10s).
+- To test crash recovery, you can use the **mrapps/crash.go** application plugin. It randomly exits in the Map and Reduce functions.
+- To ensure that nobody observes partially written files in the presence of crashes, the MapReduce paper mentions the trick of using a temporary file and atomically renaming it once it is completely written. You can use `ioutil.TempFile` (or `os.CreateTemp` if you are running Go 1.17 or later) to create a temporary file and `os.Rename` to atomically rename it.
+- Go RPC sends only struct fields whose names start with **capital letters**. Sub-structures must also have capitalized field names.
+- When calling the RPC `call()` function, the reply struct should contain all default values. RPC calls should look like this:
+
+ ```go
+ reply := SomeType{}
+ call(..., &reply)
+ ```
+
+ without setting any fields of reply before the call. If you pass reply structures that have non-default fields, the RPC system may silently return incorrect values.
+
+## No-credit challenge exercises
+
+- Implement your own MapReduce application (see examples in `mrapps/*`), e.g., Distributed Grep (Section 2.3 of the MapReduce paper).
+- Get your MapReduce coordinator and workers to run on separate machines, as they would in practice. You will need to set up your RPCs to communicate over TCP/IP instead of Unix sockets (see the commented out line in `Coordinator.server()`), and read/write files using a shared file system. For example, you can ssh into multiple Athena cluster machines at MIT, which use AFS to share files; or you could rent a couple AWS instances and use S3 for storage.
+
+---
+*From: [6.5840 Lab 1: MapReduce](https://pdos.csail.mit.edu/6.824/labs/lab-mr.html)*
diff --git a/docs/6.5840: Distributed System/4. Lab 2: Key-Value Server-cn.md b/docs/6.5840: Distributed System/4. Lab 2: Key-Value Server-cn.md
new file mode 100644
index 0000000..277d709
--- /dev/null
+++ b/docs/6.5840: Distributed System/4. Lab 2: Key-Value Server-cn.md
@@ -0,0 +1,178 @@
+# 6.5840 Lab 2: Key/Value Server
+
+## 简介
+
+在本实验中你将构建一个单机 key/value 服务器,在网络故障下保证每次 Put 操作**至多执行一次**,并保证操作满足 **linearizable**(线性一致性)。你将用该 KV 服务器实现一把锁。后续实验会复制此类服务器以应对服务器崩溃。
+
+## KV 服务器
+
+每个客户端通过 **Clerk**(一组库例程)与 key/value 服务器交互,Clerk 向服务器发送 RPC。客户端可向服务器发送两种 RPC:**Put(key, value, version)** 和 **Get(key)**。服务器在内存中维护一个 map,为每个 key 记录 **(value, version)** 二元组。key 和 value 均为字符串。version 记录该 key 被写入的次数。
+
+- **Put(key, value, version)** 仅当该 Put 的 version 与服务器上该 key 的 version 一致时,才在 map 中安装或替换该 key 的值。若 version 一致,服务器还会将该 key 的 version 加一。若 version 不一致,服务器应返回 `rpc.ErrVersion`。客户端可通过 version 为 0 的 Put 创建新 key(服务器存储的 version 将变为 1)。若 Put 的 version 大于 0 且 key 不存在,服务器应返回 `rpc.ErrNoKey`。
+
+- **Get(key)** 获取该 key 的当前值及其 version。若 key 在服务器上不存在,服务器应返回 `rpc.ErrNoKey`。
+
+为每个 key 维护 version 有助于用 Put 实现锁,并在网络不可靠、客户端重传时保证 Put 的至多一次语义。
+
+完成本实验并通过全部测试后,从调用 `Clerk.Get` 和 `Clerk.Put` 的客户端角度看,你将得到一个 **linearizable** 的 key/value 服务。即:若客户端操作不并发,每个 Clerk.Get 和 Clerk.Put 将观察到由先前操作序列所蕴含的状态修改。对于并发操作,返回值和最终状态将等同于这些操作以某种顺序一次执行一个的结果。若两操作在时间上重叠则视为并发,例如客户端 X 调用 Clerk.Put()、客户端 Y 调用 Clerk.Put(),然后 X 的调用返回。一个操作必须观察到在该操作开始前已完成的全部操作的效果。更多背景见 [linearizability 常见问题](../papers/linearizability-faq-cn.txt)。
+
+Linearizability 对应用很方便,因为其行为与单台一次处理一个请求的服务器一致。例如,若某客户端从服务器得到一次更新请求的成功响应,之后其他客户端发起的读保证能看到该更新的效果。对单机服务器而言,提供 linearizability 相对容易。
+
+## 起步
+
+我们在 `src/kvsrv1` 中提供了骨架代码和测试。`kvsrv1/client.go` 实现了客户端用于与服务器管理 RPC 交互的 Clerk,提供 Put 和 Get 方法。`kvsrv1/server.go` 包含服务器代码,包括实现 RPC 请求服务端的 Put 和 Get 处理函数。你需要修改 `client.go` 和 `server.go`。RPC 请求、回复和错误值在 `kvsrv1/rpc` 包的 `kvsrv1/rpc/rpc.go` 中定义,建议阅读但不必修改 rpc.go。
+
+运行以下命令即可开始。别忘了 `git pull` 获取最新代码。
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+$ cd src
+$ make kvsrv1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1 && go test -v -race
+=== RUN TestReliablePut
+One client and reliable Put (reliable network)...
+ kvsrv_test.go:25: Put err ErrNoKey
+--- FAIL: TestReliablePut (0.31s)
+...
+$
+```
+
+## 可靠网络下的 key/value 服务器(简单)
+
+第一个任务是在无丢包时实现正确行为。你需要在 `client.go` 的 Clerk Put/Get 方法中加入发送 RPC 的代码,并在 `server.go` 中实现 Put 和 Get 的 RPC 处理函数。
+
+当通过测试套件中的 Reliable 测试时,该任务即完成:
+
+```bash
+$ cd src
+$ make RUN="-run Reliable" kvsrv1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1 && go test -v -race -run Reliable
+=== RUN TestReliablePut
+One client and reliable Put (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 5 #Ops 5
+--- PASS: TestReliablePut (0.12s)
+=== RUN TestPutConcurrentReliable
+Test: many clients racing to put values to the same key (reliable network)...
+ ... Passed -- time 6.3s #peers 1 #RPCs 11025 #Ops 22050
+--- PASS: TestPutConcurrentReliable (6.36s)
+=== RUN TestMemPutManyClientsReliable
+Test: memory use many put clients (reliable network)...
+ ... Passed -- time 29.0s #peers 1 #RPCs 50000 #Ops 50000
+--- PASS: TestMemPutManyClientsReliable (52.91s)
+PASS
+ok 6.5840/kvsrv1 60.732s
+$
+```
+
+每个 Passed 后的数字依次为:实际时间(秒)、常数 1、发送的 RPC 数(含客户端 RPC)、执行的 key/value 操作数(Clerk Get 和 Put 调用)。
+
+## 用 key/value clerk 实现锁(中等)
+
+许多分布式应用中,不同机器上的客户端通过 key/value 服务器协调。例如 ZooKeeper 和 Etcd 允许客户端用分布式锁协调,类似于 Go 程序中线程用锁(如 `sync.Mutex`)协调。Zookeeper 和 Etcd 用条件 Put 实现这种锁。
+
+你的任务是用 key/value 服务器存储锁所需的每把锁的状态,从而实现锁。可以有多把独立的锁,每把锁有各自的名称,作为 `MakeLock` 的参数。锁支持两个方法:**Acquire** 和 **Release**。规范是:同一时刻只有一个客户端能成功 acquire 某把锁;其他客户端须等第一个客户端用 Release 释放后才能 acquire。
+
+我们在 `src/kvsrv1/lock/` 中提供了骨架和测试。你需要修改 `src/kvsrv1/lock/lock.go`。你的 Acquire 和 Release 应通过调用 `lk.ck.Put()` 和 `lk.ck.Get()` 在 key/value 服务器中存储每把锁的状态。
+
+若客户端在持有锁时崩溃,锁将永远不会被释放。在比本实验更复杂的设计中,客户端会为锁附加 [lease](https://en.wikipedia.org/wiki/Lease_(computer_science)),lease 过期后锁服务器会代客户端释放锁。本实验中客户端不会崩溃,可忽略该问题。
+
+实现 Acquire 和 Release。当你的代码通过以下测试时,该练习即完成:
+
+```bash
+$ cd src
+$ make RUN="-run Reliable" lock1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1/lock; go test -v -race -run Reliable
+=== RUN TestReliableBasic
+Test: a single Acquire and Release (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 4 #Ops 4
+--- PASS: TestReliableBasic (0.13s)
+=== RUN TestReliableNested
+Test: one client, two locks (reliable network)...
+ ... Passed -- time 0.1s #peers 1 #RPCs 17 #Ops 17
+--- PASS: TestReliableNested (0.17s)
+=== RUN TestOneClientReliable
+Test: 1 lock clients (reliable network)...
+ ... Passed -- time 2.0s #peers 1 #RPCs 477 #Ops 477
+--- PASS: TestOneClientReliable (2.14s)
+=== RUN TestManyClientsReliable
+Test: 10 lock clients (reliable network)...
+ ... Passed -- time 2.2s #peers 1 #RPCs 5704 #Ops 5704
+--- PASS: TestManyClientsReliable (2.36s)
+PASS
+ok 6.5840/kvsrv1/lock 5.817s
+$
+```
+
+若尚未实现锁,前两个测试也会通过。
+
+该练习代码量不大,但比前一练习需要更多独立思考。
+
+- 每个锁客户端需要一个唯一标识;可调用 **kvtest.RandValue(8)** 生成随机字符串。
+
+## 存在丢包时的 key/value 服务器(中等)
+
+本练习的主要挑战是网络可能重排、延迟或丢弃 RPC 请求和/或回复。为从丢弃的请求/回复中恢复,Clerk 必须不断重试每个 RPC 直到收到服务器回复。
+
+- 若网络丢弃了 **RPC 请求**,客户端重发请求即可:服务器只会收到并执行一次重发的请求。
+
+- 但网络也可能丢弃 **RPC 回复**。客户端无法区分哪种情况,只能观察到没收到回复。若是回复被丢弃且客户端重发 RPC 请求,服务器会收到两份请求。对 Get 没问题,因为 Get 不修改服务器状态。用相同 version 重发 Put RPC 也是安全的,因为服务器按 version 条件执行 Put;若服务器已收到并执行过该 Put RPC,会对重传的同一 RPC 回复 `rpc.ErrVersion` 而不会再次执行。
+
+一个棘手情况是:Clerk 重试后,服务器用 `rpc.ErrVersion` 回复。此时 Clerk 无法确定自己的 Put 是否已被执行:可能是第一次 RPC 已被执行但服务器发出的成功回复被网络丢弃,所以服务器仅对重传的 RPC 回复了 `rpc.ErrVersion`;也可能是另一个 Clerk 在该 Clerk 的第一次 RPC 到达前更新了 key,所以服务器两次都没执行该 Clerk 的 RPC,并对两次都回复 `rpc.ErrVersion`。因此,若 Clerk 对**重传的** Put RPC 收到 `rpc.ErrVersion`,**Clerk.Put 必须向应用返回 `rpc.ErrMaybe`** 而不是 `rpc.ErrVersion`,因为请求可能已执行。应用负责处理这种情况。若服务器对**首次**(非重传)Put RPC 回复 `rpc.ErrVersion`,则 Clerk 应向应用返回 `rpc.ErrVersion`,因为该 RPC 确定未被服务器执行。
+
+若 Put 能实现恰好一次(即没有 `rpc.ErrMaybe` 错误)会对应用开发者更友好,但在不为每个 Clerk 在服务器维护状态的情况下难以保证。本实验最后一个练习中,你将用 Clerk 实现锁,以体会在至多一次 Clerk.Put 下如何编程。
+
+现在应修改 `kvsrv1/client.go`,在 RPC 请求或回复被丢弃时继续重试。客户端 `ck.clnt.Call()` 返回 **true** 表示收到了服务器的 RPC 回复;返回 **false** 表示未收到回复(更准确地说,Call() 在超时时间内等待回复,超时内未收到则返回 false)。你的 Clerk 应持续重发 RPC 直到收到回复。请牢记上面关于 `rpc.ErrMaybe` 的讨论。你的方案不应要求修改服务器。
+
+在 Clerk 中加入未收到回复时的重试逻辑。当你的代码通过 kvsrv1 的全部测试时,该任务即完成:
+
+```bash
+$ make kvsrv1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1 && go test -v -race
+=== RUN TestReliablePut
+One client and reliable Put (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 5 #Ops 5
+--- PASS: TestReliablePut (0.12s)
+=== RUN TestPutConcurrentReliable
+...
+=== RUN TestUnreliableNet
+One client (unreliable network)...
+ ... Passed -- time 4.0s #peers 1 #RPCs 268 #Ops 422
+--- PASS: TestUnreliableNet (4.13s)
+PASS
+ok 6.5840/kvsrv1 64.442s
+$
+```
+
+- 重试前客户端应稍等;可使用 Go 的 time 包并调用 **time.Sleep(100 * time.Millisecond)**。
+
+## 不可靠网络下用 key/value clerk 实现锁(简单)
+
+修改你的锁实现,使其在网络不可靠时能与修改后的 key/value 客户端正确配合。当你的代码通过 lock1 的全部测试时,该练习即完成:
+
+```bash
+$ make lock1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1/lock; go test -v -race
+=== RUN TestReliableBasic
+...
+=== RUN TestOneClientUnreliable
+Test: 1 lock clients (unreliable network)...
+ ... Passed -- time 2.1s #peers 1 #RPCs 66 #Ops 57
+--- PASS: TestOneClientUnreliable (2.18s)
+=== RUN TestManyClientsUnreliable
+Test: 10 lock clients (unreliable network)...
+ ... Passed -- time 4.1s #peers 1 #RPCs 778 #Ops 617
+--- PASS: TestManyClientsUnreliable (4.23s)
+PASS
+ok 6.5840/kvsrv1/lock 12.227s
+$
+```
+
+---
+*来源: [6.5840 Lab 2: Key/Value Server](https://pdos.csail.mit.edu/6.824/labs/lab-kvsrv1.html)*
diff --git a/docs/6.5840: Distributed System/4. Lab 2: Key-Value Server.md b/docs/6.5840: Distributed System/4. Lab 2: Key-Value Server.md
new file mode 100644
index 0000000..da5e880
--- /dev/null
+++ b/docs/6.5840: Distributed System/4. Lab 2: Key-Value Server.md
@@ -0,0 +1,178 @@
+# 6.5840 Lab 2: Key/Value Server
+
+## Introduction
+
+In this lab you will build a key/value server for a single machine that ensures that each Put operation is executed at-most-once despite network failures and that the operations are linearizable. You will use this KV server to implement a lock. Later labs will replicate a server like this one to handle server crashes.
+
+## KV server
+
+Each client interacts with the key/value server using a **Clerk**, a set of library routines which sends RPCs to the server. Clients can send two different RPCs to the server: **Put(key, value, version)** and **Get(key)**. The server maintains an in-memory map that records for each key a **(value, version)** tuple. Keys and values are strings. The version number records the number of times the key has been written.
+
+- **Put(key, value, version)** installs or replaces the value for a particular key in the map only if the Put's version number matches the server's version number for the key. If the version numbers match, the server also increments the version number of the key. If the version numbers don't match, the server should return `rpc.ErrVersion`. A client can create a new key by invoking Put with version number 0 (and the resulting version stored by the server will be 1). If the version number of the Put is larger than 0 and the key doesn't exist, the server should return `rpc.ErrNoKey`.
+
+- **Get(key)** fetches the current value for the key and its associated version. If the key doesn't exist at the server, the server should return `rpc.ErrNoKey`.
+
+Maintaining a version number for each key will be useful for implementing locks using Put and ensuring at-most-once semantics for Put's when the network is unreliable and the client retransmits.
+
+When you've finished this lab and passed all the tests, you'll have a **linearizable** key/value service from the point of view of clients calling `Clerk.Get` and `Clerk.Put`. That is, if client operations aren't concurrent, each client Clerk.Get and Clerk.Put will observe the modifications to the state implied by the preceding sequence of operations. For concurrent operations, the return values and final state will be the same as if the operations had executed one at a time in some order. Operations are concurrent if they overlap in time: for example, if client X calls Clerk.Put(), and client Y calls Clerk.Put(), and then client X's call returns. An operation must observe the effects of all operations that have completed before the operation starts. See the FAQ on [linearizability](../papers/linearizability-faq.txt) for more background.
+
+Linearizability is convenient for applications because it's the behavior you'd see from a single server that processes requests one at a time. For example, if one client gets a successful response from the server for an update request, subsequently launched reads from other clients are guaranteed to see the effects of that update. Providing linearizability is relatively easy for a single server.
+
+## Getting Started
+
+We supply you with skeleton code and tests in `src/kvsrv1`. `kvsrv1/client.go` implements a Clerk that clients use to manage RPC interactions with the server; the Clerk provides Put and Get methods. `kvsrv1/server.go` contains the server code, including the Put and Get handlers that implement the server side of RPC requests. You will need to modify `client.go` and `server.go`. The RPC requests, replies, and error values are defined in the `kvsrv1/rpc` package in the file `kvsrv1/rpc/rpc.go`, which you should look at, though you don't have to modify rpc.go.
+
+To get up and running, execute the following commands. Don't forget the `git pull` to get the latest software.
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+$ cd src
+$ make kvsrv1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1 && go test -v -race
+=== RUN TestReliablePut
+One client and reliable Put (reliable network)...
+ kvsrv_test.go:25: Put err ErrNoKey
+--- FAIL: TestReliablePut (0.31s)
+...
+$
+```
+
+## Key/value server with reliable network (easy)
+
+Your first task is to implement a solution that works when there are no dropped messages. You'll need to add RPC-sending code to the Clerk Put/Get methods in `client.go`, and implement Put and Get RPC handlers in `server.go`.
+
+You have completed this task when you pass the Reliable tests in the test suite:
+
+```bash
+$ cd src
+$ make RUN="-run Reliable" kvsrv1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1 && go test -v -race -run Reliable
+=== RUN TestReliablePut
+One client and reliable Put (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 5 #Ops 5
+--- PASS: TestReliablePut (0.12s)
+=== RUN TestPutConcurrentReliable
+Test: many clients racing to put values to the same key (reliable network)...
+ ... Passed -- time 6.3s #peers 1 #RPCs 11025 #Ops 22050
+--- PASS: TestPutConcurrentReliable (6.36s)
+=== RUN TestMemPutManyClientsReliable
+Test: memory use many put clients (reliable network)...
+ ... Passed -- time 29.0s #peers 1 #RPCs 50000 #Ops 50000
+--- PASS: TestMemPutManyClientsReliable (52.91s)
+PASS
+ok 6.5840/kvsrv1 60.732s
+$
+```
+
+The numbers after each Passed are real time in seconds, the constant 1, the number of RPCs sent (including client RPCs), and the number of key/value operations executed (Clerk Get and Put calls).
+
+## Implementing a lock using key/value clerk (moderate)
+
+In many distributed applications, clients running on different machines use a key/value server to coordinate their activities. For example, ZooKeeper and Etcd allow clients to coordinate using a distributed lock, in analogy with how threads in a Go program can coordinate with locks (i.e., `sync.Mutex`). Zookeeper and Etcd implement such a lock with conditional put.
+
+Your task is to implement locks, using your key/value server to store whatever per-lock state your design needs. There can be multiple independent locks, each with its own name, passed as an argument to `MakeLock`. A lock supports two methods: **Acquire** and **Release**. The specification is that only one client can successfully acquire a given lock at a time; other clients must wait until the first client has released the lock using Release.
+
+We supply you with skeleton code and tests in `src/kvsrv1/lock/`. You will need to modify `src/kvsrv1/lock/lock.go`. Your Acquire and Release should store each lock's state in your key/value server, by calling `lk.ck.Put()` and `lk.ck.Get()`.
+
+If a client crashes while holding a lock, the lock will never be released. In a design more sophisticated than this lab, the client would attach a [lease](https://en.wikipedia.org/wiki/Lease_(computer_science)) to a lock. When the lease expires, the lock server would release the lock on behalf of the client. In this lab clients don't crash and you can ignore this problem.
+
+Implement Acquire and Release. You have completed this exercise when your code passes these tests:
+
+```bash
+$ cd src
+$ make RUN="-run Reliable" lock1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1/lock; go test -v -race -run Reliable
+=== RUN TestReliableBasic
+Test: a single Acquire and Release (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 4 #Ops 4
+--- PASS: TestReliableBasic (0.13s)
+=== RUN TestReliableNested
+Test: one client, two locks (reliable network)...
+ ... Passed -- time 0.1s #peers 1 #RPCs 17 #Ops 17
+--- PASS: TestReliableNested (0.17s)
+=== RUN TestOneClientReliable
+Test: 1 lock clients (reliable network)...
+ ... Passed -- time 2.0s #peers 1 #RPCs 477 #Ops 477
+--- PASS: TestOneClientReliable (2.14s)
+=== RUN TestManyClientsReliable
+Test: 10 lock clients (reliable network)...
+ ... Passed -- time 2.2s #peers 1 #RPCs 5704 #Ops 5704
+--- PASS: TestManyClientsReliable (2.36s)
+PASS
+ok 6.5840/kvsrv1/lock 5.817s
+$
+```
+
+If you haven't implemented the lock yet, the first two tests will succeed.
+
+This exercise requires little code but a bit more independent thought than the previous exercise.
+
+- You will need a unique identifier for each lock client; call **kvtest.RandValue(8)** to generate a random string.
+
+## Key/value server with dropped messages (moderate)
+
+The main challenge in this exercise is that the network may re-order, delay, or discard RPC requests and/or replies. To recover from discarded requests/replies, the Clerk must keep re-trying each RPC until it receives a reply from the server.
+
+- If the network discards an **RPC request** message, then the client re-sending the request will solve the problem: the server will receive and execute just the re-sent request.
+
+- However, the network might instead discard an **RPC reply** message. The client does not know which message was discarded; the client only observes that it received no reply. If it was the reply that was discarded, and the client re-sends the RPC request, then the server will receive two copies of the request. That's OK for a Get, since Get doesn't modify the server state. It is safe to resend a Put RPC with the same version number, since the server executes Put conditionally on the version number; if the server received and executed a Put RPC, it will respond to a re-transmitted copy of that RPC with `rpc.ErrVersion` rather than executing the Put a second time.
+
+A tricky case is if the server replies with an `rpc.ErrVersion` in a response to an RPC that the Clerk retried. In this case, the Clerk cannot know if the Clerk's Put was executed by the server or not: the first RPC might have been executed by the server but the network may have discarded the successful response from the server, so that the server sent `rpc.ErrVersion` only for the retransmitted RPC. Or, it might be that another Clerk updated the key before the Clerk's first RPC arrived at the server, so that the server executed neither of the Clerk's RPCs and replied `rpc.ErrVersion` to both. Therefore, if a Clerk receives `rpc.ErrVersion` for a **retransmitted** Put RPC, **Clerk.Put must return `rpc.ErrMaybe` to the application** instead of `rpc.ErrVersion` since the request may have been executed. It is then up to the application to handle this case. If the server responds to an **initial** (not retransmitted) Put RPC with `rpc.ErrVersion`, then the Clerk should return `rpc.ErrVersion` to the application, since the RPC was definitely not executed by the server.
+
+It would be more convenient for application developers if Put's were exactly-once (i.e., no `rpc.ErrMaybe` errors) but that is difficult to guarantee without maintaining state at the server for each Clerk. In the last exercise of this lab, you will implement a lock using your Clerk to explore how to program with at-most-once Clerk.Put.
+
+Now you should modify your `kvsrv1/client.go` to continue in the face of dropped RPC requests and replies. A return value of **true** from the client's `ck.clnt.Call()` indicates that the client received an RPC reply from the server; a return value of **false** indicates that it did not receive a reply (more precisely, Call() waits for a reply message for a timeout interval, and returns false if no reply arrives within that time). Your Clerk should keep re-sending an RPC until it receives a reply. Keep in mind the discussion of `rpc.ErrMaybe` above. Your solution shouldn't require any changes to the server.
+
+Add code to Clerk to retry if it doesn't receive a reply. You have completed this task if your code passes all the tests for kvsrv1:
+
+```bash
+$ make kvsrv1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1 && go test -v -race
+=== RUN TestReliablePut
+One client and reliable Put (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 5 #Ops 5
+--- PASS: TestReliablePut (0.12s)
+=== RUN TestPutConcurrentReliable
+...
+=== RUN TestUnreliableNet
+One client (unreliable network)...
+ ... Passed -- time 4.0s #peers 1 #RPCs 268 #Ops 422
+--- PASS: TestUnreliableNet (4.13s)
+PASS
+ok 6.5840/kvsrv1 64.442s
+$
+```
+
+- Before the client retries, it should wait a little bit; you can use Go's time package and call **time.Sleep(100 * time.Millisecond)**.
+
+## Implementing a lock using key/value clerk and unreliable network (easy)
+
+Modify your lock implementation to work correctly with your modified key/value client when the network is not reliable. You have completed this exercise when your code passes all the lock1 tests:
+
+```bash
+$ make lock1
+go build -race -o main/kvsrv1d main/kvsrv1d.go
+cd kvsrv1/lock; go test -v -race
+=== RUN TestReliableBasic
+...
+=== RUN TestOneClientUnreliable
+Test: 1 lock clients (unreliable network)...
+ ... Passed -- time 2.1s #peers 1 #RPCs 66 #Ops 57
+--- PASS: TestOneClientUnreliable (2.18s)
+=== RUN TestManyClientsUnreliable
+Test: 10 lock clients (unreliable network)...
+ ... Passed -- time 4.1s #peers 1 #RPCs 778 #Ops 617
+--- PASS: TestManyClientsUnreliable (4.23s)
+PASS
+ok 6.5840/kvsrv1/lock 12.227s
+$
+```
+
+---
+*From: [6.5840 Lab 2: Key/Value Server](https://pdos.csail.mit.edu/6.824/labs/lab-kvsrv1.html)*
diff --git a/docs/6.5840: Distributed System/5. Lab 3: Raft-cn.md b/docs/6.5840: Distributed System/5. Lab 3: Raft-cn.md
new file mode 100644
index 0000000..72cdd78
--- /dev/null
+++ b/docs/6.5840: Distributed System/5. Lab 3: Raft-cn.md
@@ -0,0 +1,247 @@
+# 6.5840 Lab 3: Raft
+
+## 简介
+
+这是构建容错 key/value 存储系统系列实验中的第一个。本实验中你将实现 Raft,一种复制状态机协议。下一个实验你将在 Raft 之上构建 key/value 服务。之后你将对服务进行 "shard"(分片),在多个复制状态机上获得更高性能。
+
+复制服务通过在多台副本服务器上存储完整状态(即数据)副本来实现容错。复制使服务在部分服务器发生故障(崩溃或网络中断、不稳定)时仍能继续运行。难点在于故障可能导致各副本持有不同的数据副本。
+
+Raft 将客户端请求组织成称为 **log**(日志)的序列,并保证所有副本服务器看到相同的日志。每个副本按日志顺序执行客户端请求,并应用到其本地服务状态副本。由于所有存活副本看到相同的日志内容,它们以相同顺序执行相同请求,从而保持相同的服务状态。若某服务器失败后恢复,Raft 会负责使其日志跟上。只要至少**多数**(majority)服务器存活且能相互通信,Raft 就会持续运行。若不存在这样的多数,Raft 不会取得进展,但一旦多数能再次通信就会从中断处继续。
+
+本实验中你将把 Raft 实现为带有关联方法的 Go 对象类型,作为更大服务中的一个模块使用。一组 Raft 实例通过 RPC 相互通信以维护复制日志。你的 Raft 接口将支持无限长的、带编号的命令序列,也称为 **log entries**。条目用 *index* 编号。给定 index 的日志条目最终会被 **committed**。届时你的 Raft 应将该日志条目交给上层服务执行。
+
+你应遵循 [Raft 扩展论文](../papers/raft-extended-cn.md) 的设计,尤其注意 **Figure 2**。你将实现论文中的大部分内容,包括保存持久状态并在节点失败重启后读取。不需要实现集群成员变更(第 6 节)。
+
+本实验分**四个部分**提交。你必须在各自截止日前提交对应部分。
+
+---
+
+## 起步
+
+若已完成 Lab 1,你已有实验源码。若没有,可在 Lab 1 说明中查看通过 git 获取源码的方法。
+
+我们提供了骨架代码 `src/raft1/raft.go`,以及一组用于驱动实现并用于批改的测试,测试在 `src/raft1/raft_test.go`。
+
+批改时我们会在**不带** `-race` 标志下运行测试。但你自己**应用 `-race` 测试**。
+
+运行以下命令即可开始。别忘了 `git pull` 获取最新代码。
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+$ cd src
+$ make raft1
+go build -race -o main/raft1d main/raft1d.go
+cd raft1 && go test -v -race
+=== RUN TestInitialElection3A
+Test (3A): initial election (reliable network)...
+Fatal: expected one leader, got none
+ /Users/rtm/824-process-raft/src/raft1/test.go:151
+ /Users/rtm/824-process-raft/src/raft1/raft_test.go:36
+info: wrote visualization to /var/folders/x_/vk0xmxwn1sj91m89wsn5b1yh0000gr/T/porcupine-2242138501.html
+--- FAIL: TestInitialElection3A (5.51s)
+...
+$
+```
+
+---
+
+## 代码结构
+
+在 `raft1/raft.go` 中补充代码实现 Raft。该文件中有骨架代码以及发送、接收 RPC 的示例。
+
+你的实现必须支持下列接口,测试程序以及(最终)你的 key/value 服务器会使用。更多细节见 `raft.go` 和 `raftapi/raftapi.go` 中的注释。
+
+```go
+// create a new Raft server instance:
+rf := Make(peers, me, persister, applyCh)
+
+// start agreement on a new log entry:
+rf.Start(command interface{}) (index, term, isleader)
+
+// ask a Raft for its current term, and whether it thinks it is leader
+rf.GetState() (term, isLeader)
+
+// each time a new entry is committed to the log, each Raft peer
+// should send an ApplyMsg to the service (or tester).
+type ApplyMsg
+```
+
+服务通过调用 `Make(peers, me, …)` 创建 Raft 节点。**peers** 是 Raft 节点(含本节点)的网络标识数组,用于 RPC。**me** 是本节点在 peers 数组中的 index。**Start(command)** 请求 Raft 开始将命令追加到复制日志的流程。**Start()** 应立即返回,不等待日志追加完成。服务期望你的实现在每条新提交的日志条目时向 **Make()** 的 **applyCh** 参数发送一条 **ApplyMsg**。
+
+`raft.go` 中有发送 RPC(`sendRequestVote()`)和处理传入 RPC(`RequestVote()`)的示例代码。你的 Raft 节点应使用 labrpc Go 包(源码在 `src/labrpc`)交换 RPC。测试可以指示 labrpc 延迟、重排或丢弃 RPC 以模拟各种网络故障。可以临时修改 labrpc,但须确保你的 Raft 在原始 labrpc 下能工作,因为我们会用其测试和批改。Raft 实例之间只能通过 RPC 交互;例如不允许通过共享 Go 变量或文件通信。
+
+后续实验建立在本实验之上,因此留足时间写出可靠代码很重要。
+
+---
+
+## Part 3A: Leader Election
+
+实现 Raft 的 leader 选举与心跳(不含日志条目的 AppendEntries RPC)。Part 3A 的目标是选出一个 leader、在无故障时保持该 leader、以及当旧 leader 失败或与之相关的包丢失时由新 leader 接管。在 `src` 目录下运行 `make RUN="-run 3A" raft1` 测试 3A 代码。
+
+* 遵循论文 **Figure 2**。当前阶段关注发送和接收 RequestVote RPC、与选举相关的 Rules for Servers,以及 leader 选举相关的 State。
+* 在 `raft.go` 的 Raft 结构体中加入 Figure 2 中与 leader 选举相关的状态。
+* 填写 **RequestVoteArgs** 和 **RequestVoteReply** 结构体。修改 **Make()**,创建一个后台 goroutine,在一段时间未收到其他节点消息时定期发起 leader 选举、发送 RequestVote RPC。实现 **RequestVote()** RPC 处理函数,使服务器能相互投票。
+* 为实现心跳,定义 **AppendEntries** RPC 结构体(可能暂时不需要所有参数),并让 leader 定期发送。实现 **AppendEntries** RPC 处理函数。
+* 测试要求 leader 发送心跳 RPC **每秒不超过十次**。
+* 测试要求你的 Raft 在旧 leader 失败后**五秒内**选出新 leader(若多数节点仍能通信)。
+* 论文 5.2 节提到选举超时在 150 到 300 毫秒范围。该范围仅在 leader 发送心跳远高于每 150 毫秒一次(例如每 10 毫秒)时合理。因测试限制为每秒十次心跳,你须使用**大于**论文 150–300 毫秒的选举超时,但不宜过大,否则可能无法在五秒内选出 leader。
+* 可使用 Go 的 **rand**。
+* 需要编写定期或延迟执行动作的代码。最简单的方式是创建一个带循环的 goroutine 并调用 **time.Sleep()**;参见 **Make()** 中为此创建的 `ticker()` goroutine。**不要使用 Go 的 time.Timer 或 time.Ticker**,它们难以正确使用。
+* 若测试难以通过,请再次阅读论文 Figure 2;leader 选举的完整逻辑分布在图的多个部分。
+* 别忘了实现 **GetState()**。
+* Go RPC 只发送**首字母大写**的 struct 字段。子结构字段名也须大写(例如数组中日志记录的字段)。**labgob** 包会对此给出警告;不要忽略。
+* 本实验最具挑战的部分可能是调试。调试建议见 [Guidance](./2.%20Lab%20Guidance-cn.md) 页。
+* 若测试失败,测试程序会生成一个可视化时间线文件,标出事件、网络分区、崩溃的服务器和执行的检查。参见[可视化示例](https://pdos.csail.mit.edu/6.824/labs/raft-tester.html)。你也可以添加自己的标注,例如 `tester.Annotate("Server 0", "short description", "details")`。
+
+提交 Part 3A 前请确保通过 3A 测试,看到类似输出:
+
+```bash
+$ make RUN="-run 3A" raft1
+go build -race -o main/raft1d main/raft1d.go
+cd raft1 && go test -v -race -run 3A
+=== RUN TestInitialElection3A
+Test (3A): initial election (reliable network)...
+ ... Passed -- time 3.5s #peers 3 #RPCs 32 #Ops 0
+--- PASS: TestInitialElection3A (3.84s)
+=== RUN TestReElection3A
+Test (3A): election after network failure (reliable network)...
+ ... Passed -- time 6.2s #peers 3 #RPCs 68 #Ops 0
+--- PASS: TestReElection3A (6.54s)
+=== RUN TestManyElections3A
+Test (3A): multiple elections (reliable network)...
+ ... Passed -- time 9.8s #peers 7 #RPCs 684 #Ops 0
+--- PASS: TestManyElections3A (10.68s)
+PASS
+ok 6.5840/raft1 22.095s
+$
+```
+
+每行 "Passed" 包含五个数字:测试耗时(秒)、Raft 节点数、测试期间发送的 RPC 数、RPC 消息总字节数、Raft 报告已提交的日志条数。你的数字会与示例不同。可以忽略这些数字,但它们有助于 sanity-check 实现发送的 RPC 数量。对 Lab 3、4、5 全部测试,若总耗时超过 600 秒或任一测试超过 120 秒,批改脚本会判为不通过。
+
+批改时我们会在不带 `-race` 下运行测试。但请确保你的代码**在带 `-race` 时能稳定通过测试**。
+
+---
+
+## Part 3B: Log
+
+实现 leader 和 follower 追加新日志条目的逻辑,使 `make RUN="-run 3B" raft1` 通过全部测试。
+
+* 运行 `git pull` 获取最新实验代码。
+* Raft 论文中日志从 1 开始编号,但我们建议实现为**从 0 开始**,在 index=0 放一个 term 为 0 的哑元条目。这样第一次 AppendEntries RPC 可以包含 PrevLogIndex 为 0,且是日志中的有效 index。
+* 首要目标应是通过 **TestBasicAgree3B()**。先实现 **Start()**,然后按 Figure 2 编写通过 AppendEntries RPC 发送和接收新日志条目的代码。在每个节点上对每条新提交的条目向 **applyCh** 发送。
+* 需要实现**选举限制**(论文 5.4.1 节)。
+* 代码中可能有反复检查某事件的循环。不要让这些循环无暂停地连续执行,否则会拖慢实现导致测试失败。使用 Go 的**条件变量**,或在每次循环迭代中 **time.Sleep(10 * time.Millisecond)**。
+* 为后续实验着想,尽量把代码写清楚。
+* 若测试失败,查看 `raft_test.go` 并沿测试代码追踪,理解在测什么。
+
+后续实验的测试可能会因代码过慢而判为不通过。可用 `time` 命令查看实际时间和 CPU 时间。典型输出:
+
+```bash
+$ make RUN="-run 3B" raft1
+go build -race -o main/raft1d main/raft1d.go
+cd raft1 && go test -v -race -run 3B
+=== RUN TestBasicAgree3B
+Test (3B): basic agreement (reliable network)...
+ ... Passed -- time 1.6s #peers 3 #RPCs 18 #Ops 3
+--- PASS: TestBasicAgree3B (1.96s)
+=== RUN TestRPCBytes3B
+...
+=== RUN TestCount3B
+Test (3B): RPC counts aren't too high (reliable network)...
+ ... Passed -- time 2.7s #peers 3 #RPCs 32 #Ops 0
+--- PASS: TestCount3B (3.05s)
+PASS
+ok 6.5840/raft1 71.716s
+$
+```
+
+"ok 6.5840/raft 71.716s" 表示 Go 测得的 3B 测试实际(墙上)时间为 71.716 秒。若 3B 测试实际时间远超过几分钟,后续可能出问题。检查是否有长时间 sleep 或等待 RPC 超时、是否有不 sleep 或不等待条件/ channel 的循环、或是否发送了过多 RPC。
+
+---
+
+## Part 3C: Persistence
+
+基于 Raft 的服务器重启后应从断点恢复。这要求 Raft 维护在重启后仍存在的**持久状态**。论文 Figure 2 指明了哪些状态应持久化。
+
+真实实现会在每次状态变化时将 Raft 的持久状态写入磁盘,并在重启时从磁盘读取。你的实现不使用磁盘,而是从 **Persister** 对象(见 `tester1/persister.go`)保存和恢复持久状态。调用 **Raft.Make()** 的一方提供 Persister,其初始内容为 Raft 最近持久化的状态(若有)。Raft 应从该 Persister 初始化状态,并在每次状态变化时用它保存持久状态。使用 Persister 的 **ReadRaftState()** 和 **Save()** 方法。
+
+在 `raft.go` 中完成 **persist()** 和 **readPersist()**,添加保存和恢复持久状态的代码。需要将状态编码(或“序列化”)为字节数组才能传给 Persister。使用 **labgob** 编码器;参见 **persist()** 和 **readPersist()** 中的注释。labgob 类似 Go 的 gob,但若尝试编码小写字段名的结构体会打印错误。目前将 **nil** 作为第二个参数传给 **persister.Save()**。在实现修改持久状态的位置插入对 **persist()** 的调用。完成上述工作且其余实现正确时,应能通过全部 3C 测试。
+
+你可能需要**每次将 nextIndex 回退多于一个条目的优化**。参见 Raft 扩展论文第 7 页末、第 8 页初(灰线标记处)。论文对细节描述较模糊,需要自行补全。一种做法是让拒绝消息包含:
+
+* **XTerm**:冲突条目的 term(若有)
+* **XIndex**:该 term 第一条目的 index(若有)
+* **XLen**:日志长度
+
+则 leader 的逻辑可以是:
+
+* **Case 1**:leader 没有 XTerm → `nextIndex = XIndex`
+* **Case 2**:leader 有 XTerm → `nextIndex = (leader 中 XTerm 最后一条的 index) + 1`
+* **Case 3**:follower 日志过短 → `nextIndex = XLen`
+
+其他提示:
+
+* 运行 `git pull` 获取最新实验代码。
+* 3C 测试比 3A 或 3B 更苛刻,失败可能由 3A 或 3B 代码中的问题引起。
+
+你的代码应通过全部 3C 测试(如下所示),以及 3A 和 3B 测试。
+
+```bash
+$ make RUN="-run 3C" raft1
+...
+PASS
+ok 6.5840/raft1 180.983s
+$
+```
+
+提交前多跑几遍测试是个好习惯。
+
+---
+
+## Part 3D: Log Compaction
+
+目前重启的服务器会重放完整 Raft 日志以恢复状态。但对长期运行的服务而言,永远记住完整 Raft 日志不现实。你需要修改 Raft,使其与不定期持久化状态**快照(snapshot)**的服务协作,届时 Raft 丢弃快照之前的日志条目。结果是持久数据更少、重启更快。但可能出现 follower 落后太多,leader 已丢弃其赶上来所需的日志;此时 leader 必须发送快照以及从快照时刻起的日志。Raft 扩展论文 [**Section 7**](../papers/raft-extended-cn.md) 概述了该方案;你需要设计细节。
+
+你的 Raft 必须提供服务可调用的以下函数,传入其状态的序列化快照:
+
+```go
+Snapshot(index int, snapshot []byte)
+```
+
+在 Lab 3D 中,测试程序会定期调用 **Snapshot()**。在 Lab 4 中,你将编写会调用 **Snapshot()** 的 key/value 服务器;快照将包含完整的 key/value 表。服务层在每个节点(不仅是 leader)上调用 **Snapshot()**。
+
+**index** 参数表示快照所反映的日志中最高条目的 index。Raft 应丢弃该点之前的日志条目。需要修改 Raft 代码,使其在只保存日志**尾部**的情况下运行。
+
+需要实现论文中讨论的 **InstallSnapshot** RPC,使 Raft leader 能告知落后的 Raft 节点用快照替换其状态。可能需要理清 InstallSnapshot 与 Figure 2 中的状态和规则如何交互。
+
+当 follower 的 Raft 代码收到 **InstallSnapshot** RPC 时,可通过 **applyCh** 将快照以 **ApplyMsg** 形式发给服务。`raftapi/raftapi.go` 中 ApplyMsg 结构体定义已包含所需字段(也是测试期望的)。注意这些快照只能推进服务状态,不能使其回退。
+
+若服务器崩溃,必须从持久数据重启。你的 Raft 应**同时持久化 Raft 状态和对应快照**。使用 **persister.Save()** 的第二个参数保存快照。若无快照,第二个参数传 **nil**。
+
+服务器重启时,应用层读取持久化的快照并恢复其保存的应用状态。重启后,应用层期望 **applyCh** 上的第一条消息要么是 **SnapshotIndex** 高于初始恢复快照的快照,要么是 **CommandIndex** 紧接在初始恢复快照 index 之后的普通命令。
+
+实现 **Snapshot()** 和 **InstallSnapshot** RPC,以及 Raft 为支持它们所需的修改(例如在截断日志下运行)。当通过 3D 测试(及此前全部 Lab 3 测试)时,你的方案即完成。
+
+* `git pull` 确保使用最新代码。
+* 一个好的起点是修改代码使其能只保存从某 index X 开始的日志部分。初始可将 X 设为 0 并跑 3B/3C 测试。然后让 **Snapshot(index)** 丢弃 index 之前的日志,并将 X 设为 index。顺利的话应能通过第一个 3D 测试。
+* 第一个 3D 测试失败的常见原因是 follower 追上 leader 耗时过长。
+* 接下来:若 leader 没有使 follower 赶上所需的日志条目,则发送 **InstallSnapshot** RPC。
+* **在单次 InstallSnapshot RPC 中发送完整快照**。不要实现 Figure 13 中分片快照的 offset 机制。
+* Raft 必须以允许 Go 垃圾回收器释放并重用内存的方式丢弃旧日志条目;这要求**不存在对已丢弃日志条目的可达引用(指针)**。
+* Raft 节点重启时,传给 **Make()** 的 persister 会包含应用状态快照以及 Raft 保存的状态。若日志已被截断,Raft 每次调用 **persister.Save()** 时都必须包含非 nil 快照,因此 **Make()** 中调用 **persister.ReadSnapshot()** 并保存结果是好做法。
+* 在不带 `-race` 时,完整 Lab 3 测试(3A+3B+3C+3D)合理耗时约为**实际时间 6 分钟**、**CPU 时间 1 分钟**。带 `-race` 时约为**实际时间 10 分钟**、**CPU 时间 2 分钟**。
+
+你的代码应通过全部 3D 测试(如下所示),以及 3A、3B、3C 测试。
+
+```bash
+$ make RUN="-run 3D" raft1
+...
+PASS
+ok 6.5840/raft1 301.406s
+$
+```
+
+---
+*来源: [6.5840 Lab 3: Raft](https://pdos.csail.mit.edu/6.824/labs/lab-raft1.html)*
diff --git a/docs/6.5840: Distributed System/5. Lab 3: Raft.md b/docs/6.5840: Distributed System/5. Lab 3: Raft.md
new file mode 100644
index 0000000..2100b9d
--- /dev/null
+++ b/docs/6.5840: Distributed System/5. Lab 3: Raft.md
@@ -0,0 +1,247 @@
+# 6.5840 Lab 3: Raft
+
+## Introduction
+
+This is the first in a series of labs in which you'll build a fault-tolerant key/value storage system. In this lab you'll implement Raft, a replicated state machine protocol. In the next lab you'll build a key/value service on top of Raft. Then you will "shard" your service over multiple replicated state machines for higher performance.
+
+A replicated service achieves fault tolerance by storing complete copies of its state (i.e., data) on multiple replica servers. Replication allows the service to continue operating even if some of its servers experience failures (crashes or a broken or flaky network). The challenge is that failures may cause the replicas to hold differing copies of the data.
+
+Raft organizes client requests into a sequence, called the **log**, and ensures that all the replica servers see the same log. Each replica executes client requests in log order, applying them to its local copy of the service's state. Since all the live replicas see the same log contents, they all execute the same requests in the same order, and thus continue to have identical service state. If a server fails but later recovers, Raft takes care of bringing its log up to date. Raft will continue to operate as long as at least a **majority** of the servers are alive and can talk to each other. If there is no such majority, Raft will make no progress, but will pick up where it left off as soon as a majority can communicate again.
+
+In this lab you'll implement Raft as a Go object type with associated methods, meant to be used as a module in a larger service. A set of Raft instances talk to each other with RPC to maintain replicated logs. Your Raft interface will support an indefinite sequence of numbered commands, also called **log entries**. The entries are numbered with *index numbers*. The log entry with a given index will eventually be **committed**. At that point, your Raft should send the log entry to the larger service for it to execute.
+
+You should follow the design in the [extended Raft paper](../papers/raft-extended.md), with particular attention to **Figure 2**. You'll implement most of what's in the paper, including saving persistent state and reading it after a node fails and then restarts. You will not implement cluster membership changes (Section 6).
+
+This lab is due in **four parts**. You must submit each part on the corresponding due date.
+
+---
+
+## Getting Started
+
+If you have done Lab 1, you already have a copy of the lab source code. If not, you can find directions for obtaining the source via git in the Lab 1 instructions.
+
+We supply you with skeleton code `src/raft1/raft.go`. We also supply a set of tests, which you should use to drive your implementation efforts, and which we'll use to grade your submitted lab. The tests are in `src/raft1/raft_test.go`.
+
+When we grade your submissions, we will run the tests **without** the `-race` flag. However, you should **test with `-race`**.
+
+To get up and running, execute the following commands. Don't forget the `git pull` to get the latest software.
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+$ cd src
+$ make raft1
+go build -race -o main/raft1d main/raft1d.go
+cd raft1 && go test -v -race
+=== RUN TestInitialElection3A
+Test (3A): initial election (reliable network)...
+Fatal: expected one leader, got none
+ /Users/rtm/824-process-raft/src/raft1/test.go:151
+ /Users/rtm/824-process-raft/src/raft1/raft_test.go:36
+info: wrote visualization to /var/folders/x_/vk0xmxwn1sj91m89wsn5b1yh0000gr/T/porcupine-2242138501.html
+--- FAIL: TestInitialElection3A (5.51s)
+...
+$
+```
+
+---
+
+## The Code
+
+Implement Raft by adding code to `raft1/raft.go`. In that file you'll find skeleton code, plus examples of how to send and receive RPCs.
+
+Your implementation must support the following interface, which the tester and (eventually) your key/value server will use. You'll find more details in comments in `raft.go` and in `raftapi/raftapi.go`.
+
+```go
+// create a new Raft server instance:
+rf := Make(peers, me, persister, applyCh)
+
+// start agreement on a new log entry:
+rf.Start(command interface{}) (index, term, isleader)
+
+// ask a Raft for its current term, and whether it thinks it is leader
+rf.GetState() (term, isLeader)
+
+// each time a new entry is committed to the log, each Raft peer
+// should send an ApplyMsg to the service (or tester).
+type ApplyMsg
+```
+
+A service calls `Make(peers, me, …)` to create a Raft peer. The **peers** argument is an array of network identifiers of the Raft peers (including this one), for use with RPC. The **me** argument is the index of this peer in the peers array. **Start(command)** asks Raft to start the processing to append the command to the replicated log. **Start()** should return immediately, without waiting for the log appends to complete. The service expects your implementation to send an **ApplyMsg** for each newly committed log entry to the **applyCh** channel argument to **Make()**.
+
+`raft.go` contains example code that sends an RPC (`sendRequestVote()`) and that handles an incoming RPC (`RequestVote()`). Your Raft peers should exchange RPCs using the labrpc Go package (source in `src/labrpc`). The tester can tell labrpc to delay RPCs, re-order them, and discard them to simulate various network failures. While you can temporarily modify labrpc, make sure your Raft works with the original labrpc, since that's what we'll use to test and grade your lab. Your Raft instances must interact only through RPC; for example, they are not allowed to communicate using shared Go variables or files.
+
+Subsequent labs build on this lab, so it is important to give yourself enough time to write solid code.
+
+---
+
+## Part 3A: Leader Election
+
+Implement Raft leader election and heartbeats (AppendEntries RPCs with no log entries). The goal for Part 3A is for a single leader to be elected, for the leader to remain the leader if there are no failures, and for a new leader to take over if the old leader fails or if packets to/from the old leader are lost. Run `make RUN="-run 3A" raft1` in the `src` directory to test your 3A code.
+
+* Follow the paper's **Figure 2**. At this point you care about sending and receiving RequestVote RPCs, the Rules for Servers that relate to elections, and the State related to leader election.
+* Add the Figure 2 state for leader election to the Raft struct in `raft.go`.
+* Fill in the **RequestVoteArgs** and **RequestVoteReply** structs. Modify **Make()** to create a background goroutine that will kick off leader election periodically by sending out RequestVote RPCs when it hasn't heard from another peer for a while. Implement the **RequestVote()** RPC handler so that servers will vote for one another.
+* To implement heartbeats, define an **AppendEntries** RPC struct (though you may not need all the arguments yet), and have the leader send them out periodically. Write an **AppendEntries** RPC handler method.
+* The tester requires that the leader send heartbeat RPCs **no more than ten times per second**.
+* The tester requires your Raft to **elect a new leader within five seconds** of the failure of the old leader (if a majority of peers can still communicate).
+* The paper's Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds (e.g., once per 10 milliseconds). Because the tester limits you tens of heartbeats per second, you will have to use an election timeout **larger** than the paper's 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.
+* You may find Go's **rand** useful.
+* You'll need to write code that takes actions periodically or after delays in time. The easiest way to do this is to create a goroutine with a loop that calls **time.Sleep()**; see the `ticker()` goroutine that **Make()** creates for this purpose. **Don't use Go's time.Timer or time.Ticker**, which are difficult to use correctly.
+* If your code has trouble passing the tests, read the paper's Figure 2 again; the full logic for leader election is spread over multiple parts of the figure.
+* Don't forget to implement **GetState()**.
+* Go RPC sends only struct fields whose names start with capital letters. Sub-structures must also have capitalized field names (e.g. fields of log records in an array). The **labgob** package will warn you about this; don't ignore the warnings.
+* The most challenging part of this lab may be the debugging. Refer to the [Guidance](./2.%20Lab%20Guidance.md) page for debugging tips.
+* If you fail a test, the tester produces a file that visualizes a timeline with events marked along it, including network partitions, crashed servers, and checks performed. Here's an [example of the visualization](https://pdos.csail.mit.edu/6.824/labs/raft-tester.html). Further, you can add your own annotations by writing, for example, `tester.Annotate("Server 0", "short description", "details")`.
+
+Be sure you pass the 3A tests before submitting Part 3A, so that you see something like this:
+
+```bash
+$ make RUN="-run 3A" raft1
+go build -race -o main/raft1d main/raft1d.go
+cd raft1 && go test -v -race -run 3A
+=== RUN TestInitialElection3A
+Test (3A): initial election (reliable network)...
+ ... Passed -- time 3.5s #peers 3 #RPCs 32 #Ops 0
+--- PASS: TestInitialElection3A (3.84s)
+=== RUN TestReElection3A
+Test (3A): election after network failure (reliable network)...
+ ... Passed -- time 6.2s #peers 3 #RPCs 68 #Ops 0
+--- PASS: TestReElection3A (6.54s)
+=== RUN TestManyElections3A
+Test (3A): multiple elections (reliable network)...
+ ... Passed -- time 9.8s #peers 7 #RPCs 684 #Ops 0
+--- PASS: TestManyElections3A (10.68s)
+PASS
+ok 6.5840/raft1 22.095s
+$
+```
+
+Each "Passed" line contains five numbers; these are the time that the test took in seconds, the number of Raft peers, the number of RPCs sent during the test, the total number of bytes in the RPC messages, and the number of log entries that Raft reports were committed. Your numbers will differ from those shown here. You can ignore the numbers if you like, but they may help you sanity-check the number of RPCs that your implementation sends. For all of labs 3, 4, and 5, the grading script will fail your solution if it takes more than 600 seconds for all of the tests, or if any individual test takes more than 120 seconds.
+
+When we grade your submissions, we will run the tests without the `-race` flag. However, you should make sure that your code **consistently passes the tests with the -race flag**.
+
+---
+
+## Part 3B: Log
+
+Implement the leader and follower code to append new log entries, so that `make RUN="-run 3B" raft1` passes all tests.
+
+* Run `git pull` to get the latest lab software.
+* The Raft paper views the log as 1-indexed, but we suggest that you implement it as **0-indexed**, starting with a dummy entry at index=0 that has term 0. That allows the very first AppendEntries RPC to contain 0 as PrevLogIndex, and be a valid index into the log.
+* Your first goal should be to pass **TestBasicAgree3B()**. Start by implementing **Start()**, then write the code to send and receive new log entries via AppendEntries RPCs, following Figure 2. Send each newly committed entry on **applyCh** on each peer.
+* You will need to implement the **election restriction** (section 5.4.1 in the paper).
+* Your code may have loops that repeatedly check for certain events. Don't have these loops execute continuously without pausing, since that will slow your implementation enough that it fails tests. Use Go's **condition variables**, or insert a **time.Sleep(10 * time.Millisecond)** in each loop iteration.
+* Do yourself a favor for future labs and write (or re-write) code that's clean and clear.
+* If you fail a test, look at `raft_test.go` and trace the test code from there to understand what's being tested.
+
+The tests for upcoming labs may fail your code if it runs too slowly. You can check how much real time and CPU time your solution uses with the `time` command. Here's typical output:
+
+```bash
+$ make RUN="-run 3B" raft1
+go build -race -o main/raft1d main/raft1d.go
+cd raft1 && go test -v -race -run 3B
+=== RUN TestBasicAgree3B
+Test (3B): basic agreement (reliable network)...
+ ... Passed -- time 1.6s #peers 3 #RPCs 18 #Ops 3
+--- PASS: TestBasicAgree3B (1.96s)
+=== RUN TestRPCBytes3B
+...
+=== RUN TestCount3B
+Test (3B): RPC counts aren't too high (reliable network)...
+ ... Passed -- time 2.7s #peers 3 #RPCs 32 #Ops 0
+--- PASS: TestCount3B (3.05s)
+PASS
+ok 6.5840/raft1 71.716s
+$
+```
+
+The "ok 6.5840/raft 71.716s" means that Go measured the time taken for the 3B tests to be 71.716 seconds of real (wall-clock) time. If your solution uses much more than a few minutes of real time for the 3B tests, you may run into trouble later on. Look for time spent sleeping or waiting for RPC timeouts, loops that run without sleeping or waiting for conditions or channel messages, or large numbers of RPCs sent.
+
+---
+
+## Part 3C: Persistence
+
+If a Raft-based server reboots it should resume service where it left off. This requires that Raft keep **persistent state** that survives a reboot. The paper's Figure 2 mentions which state should be persistent.
+
+A real implementation would write Raft's persistent state to disk each time it changed, and would read the state from disk when restarting after a reboot. Your implementation won't use the disk; instead, it will save and restore persistent state from a **Persister** object (see `tester1/persister.go`). Whoever calls **Raft.Make()** supplies a Persister that initially holds Raft's most recently persisted state (if any). Raft should initialize its state from that Persister, and should use it to save its persistent state each time the state changes. Use the Persister's **ReadRaftState()** and **Save()** methods.
+
+Complete the functions **persist()** and **readPersist()** in `raft.go` by adding code to save and restore persistent state. You will need to encode (or "serialize") the state as an array of bytes in order to pass it to the Persister. Use the **labgob** encoder; see the comments in **persist()** and **readPersist()**. labgob is like Go's gob encoder but prints error messages if you try to encode structures with lower-case field names. For now, pass **nil** as the second argument to **persister.Save()**. Insert calls to **persist()** at the points where your implementation changes persistent state. Once you've done this, and if the rest of your implementation is correct, you should pass all of the 3C tests.
+
+You will probably need the **optimization that backs up nextIndex by more than one entry at a time**. Look at the extended Raft paper starting at the bottom of page 7 and top of page 8 (marked by a gray line). The paper is vague about the details; you will need to fill in the gaps. One possibility is to have a rejection message include:
+
+* **XTerm**: term in the conflicting entry (if any)
+* **XIndex**: index of first entry with that term (if any)
+* **XLen**: log length
+
+Then the leader's logic can be something like:
+
+* **Case 1**: leader doesn't have XTerm → `nextIndex = XIndex`
+* **Case 2**: leader has XTerm → `nextIndex = (index of leader's last entry for XTerm) + 1`
+* **Case 3**: follower's log is too short → `nextIndex = XLen`
+
+A few other hints:
+
+* Run `git pull` to get the latest lab software.
+* The 3C tests are more demanding than those for 3A or 3B, and failures may be caused by problems in your code for 3A or 3B.
+
+Your code should pass all the 3C tests (as shown below), as well as the 3A and 3B tests.
+
+```bash
+$ make RUN="-run 3C" raft1
+...
+PASS
+ok 6.5840/raft1 180.983s
+$
+```
+
+It is a good idea to run the tests multiple times before submitting.
+
+---
+
+## Part 3D: Log Compaction
+
+As things stand now, a rebooting server replays the complete Raft log in order to restore its state. However, it's not practical for a long-running service to remember the complete Raft log forever. Instead, you'll modify Raft to cooperate with services that persistently store a **"snapshot"** of their state from time to time, at which point Raft discards log entries that precede the snapshot. The result is a smaller amount of persistent data and faster restart. However, it's now possible for a follower to fall so far behind that the leader has discarded the log entries it needs to catch up; the leader must then send a snapshot plus the log starting at the time of the snapshot. **Section 7** of the [extended Raft paper](../papers/raft-extended.md) outlines the scheme; you will have to design the details.
+
+Your Raft must provide the following function that the service can call with a serialized snapshot of its state:
+
+```go
+Snapshot(index int, snapshot []byte)
+```
+
+In Lab 3D, the tester calls **Snapshot()** periodically. In Lab 4, you will write a key/value server that calls **Snapshot()**; the snapshot will contain the complete table of key/value pairs. The service layer calls **Snapshot()** on every peer (not just on the leader).
+
+The **index** argument indicates the highest log entry that's reflected in the snapshot. Raft should discard its log entries before that point. You'll need to revise your Raft code to operate while storing only the **tail** of the log.
+
+You'll need to implement the **InstallSnapshot** RPC discussed in the paper that allows a Raft leader to tell a lagging Raft peer to replace its state with a snapshot. You will likely need to think through how InstallSnapshot should interact with the state and rules in Figure 2.
+
+When a follower's Raft code receives an **InstallSnapshot** RPC, it can use the **applyCh** to send the snapshot to the service in an **ApplyMsg**. The ApplyMsg struct definition in `raftapi/raftapi.go` already contains the fields you will need (and which the tester expects). Take care that these snapshots only advance the service's state, and don't cause it to move backwards.
+
+If a server crashes, it must restart from persisted data. Your Raft should **persist both Raft state and the corresponding snapshot**. Use the second argument to **persister.Save()** to save the snapshot. If there's no snapshot, pass **nil** as the second argument.
+
+When a server restarts, the application layer reads the persisted snapshot and restores its saved application state. After a restart, the application layer expects the first message on **applyCh** to either contain a snapshot with a **SnapshotIndex** higher than that of the initial restored snapshot, or an ordinary command with **CommandIndex** immediately following the index of the initial restored snapshot.
+
+Implement **Snapshot()** and the **InstallSnapshot** RPC, as well as the changes to Raft to support these (e.g, operation with a trimmed log). Your solution is complete when it passes the 3D tests (and all the previous Lab 3 tests).
+
+* `git pull` to make sure you have the latest software.
+* A good place to start is to modify your code to so that it is able to store just the part of the log starting at some index X. Initially you can set X to zero and run the 3B/3C tests. Then make **Snapshot(index)** discard the log before index, and set X equal to index. If all goes well you should now pass the first 3D test.
+* A common reason for failing the first 3D test is that followers take too long to catch up to the leader.
+* Next: have the leader send an **InstallSnapshot** RPC if it doesn't have the log entries required to bring a follower up to date.
+* Send the **entire snapshot in a single InstallSnapshot RPC**. Don't implement Figure 13's offset mechanism for splitting up the snapshot.
+* Raft must discard old log entries in a way that allows the Go garbage collector to free and re-use the memory; this requires that there be **no reachable references (pointers)** to the discarded log entries.
+* When a Raft peer is re-started, the persister passed to **Make()** will contain a snapshot of application state as well as Raft's saved state. Raft must include a non-nil snapshot with every call to **persister.Save()** (if the log has been trimmed), which means that it's a good idea for **Make()** to call **persister.ReadSnapshot()** and save the result.
+* A reasonable amount of time to consume for the full set of Lab 3 tests (3A+3B+3C+3D) without `-race` is **6 minutes** of real time and **one minute** of CPU time. When running with `-race`, it is about **10 minutes** of real time and **two minutes** of CPU time.
+
+Your code should pass all the 3D tests (as shown below), as well as the 3A, 3B, and 3C tests.
+
+```bash
+$ make RUN="-run 3D" raft1
+...
+PASS
+ok 6.5840/raft1 301.406s
+$
+```
+
+---
+*From: [6.5840 Lab 3: Raft](https://pdos.csail.mit.edu/6.824/labs/lab-raft1.html)*
diff --git a/docs/6.5840: Distributed System/6. Lab 4: Fault-tolerant Key-Value Service-cn.md b/docs/6.5840: Distributed System/6. Lab 4: Fault-tolerant Key-Value Service-cn.md
new file mode 100644
index 0000000..d099440
--- /dev/null
+++ b/docs/6.5840: Distributed System/6. Lab 4: Fault-tolerant Key-Value Service-cn.md
@@ -0,0 +1,224 @@
+# 6.5840 Lab 4: Fault-tolerant Key/Value Service
+
+## 简介
+
+在本实验中你将使用 Lab 3 的 Raft 库构建一个容错 key/value 存储服务。对客户端而言,该服务与 Lab 2 的服务器类似。但服务不是单台服务器,而是由一组使用 Raft 保持数据库一致的服务器组成。只要**多数**(majority)服务器存活且能通信,你的 key/value 服务就应继续处理客户端请求,即使存在其他故障或网络分区。完成 Lab 4 后,你将实现 Raft 交互图中所示的全部部分(Clerk、Service 和 Raft)。
+
+客户端通过 **Clerk** 与你的 key/value 服务交互,与 Lab 2 相同。Clerk 实现的 **Put** 和 **Get** 方法与 Lab 2 语义一致:Put 为**至多一次**,Put/Get 必须形成 **linearizable** 历史。
+
+对单机而言提供 linearizability 相对容易。在复制服务中更难,因为所有服务器必须对并发请求选择相同的执行顺序、必须避免用未更新的状态回复客户端、且必须在故障后以保留所有已确认客户端更新的方式恢复状态。
+
+本实验分**三个部分**。在 **Part A** 中,你将用你的 Raft 实现一个与具体请求无关的复制状态机包 **rsm**。在 **Part B** 中,你将用 rsm 实现一个复制的 key/value 服务,但不使用快照。在 **Part C** 中,你将使用 Lab 3D 的快照实现,使 Raft 能丢弃旧日志条目。请分别在各自截止日前提交各部分。
+
+建议复习 [Raft 扩展论文](../papers/raft-extended-cn.md),尤其是 **Section 7**(不含 8)。更广视角可参阅 Chubby、Paxos Made Live、Spanner、Zookeeper、Harp、Viewstamped Replication 以及 [Bolosky et al](https://pdos.csail.mit.edu/6.824/papers/bolosky-usenix2010.pdf)。
+
+**尽早开始。**
+
+---
+
+## 起步
+
+我们在 `src/kvraft1` 中提供了骨架代码和测试。骨架使用 `src/kvraft1/rsm` 包复制服务器。服务器必须实现 rsm 中定义的 **StateMachine** 接口才能通过 rsm 复制自身。你的主要工作是在 rsm 中实现与具体服务器无关的复制逻辑。此外需要修改 `kvraft1/client.go` 和 `kvraft1/server.go` 实现服务器相关部分。这种拆分便于在下一实验复用 rsm。可以复用部分 Lab 2 代码(例如复制或导入 "src/kvsrv1" 包中的服务器代码),但非必须。
+
+运行以下命令即可开始。别忘了 `git pull` 获取最新代码。
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+```
+
+---
+
+## Part A: Replicated State Machine (RSM)
+
+```bash
+$ cd src/kvraft1/rsm
+$ go test -v
+=== RUN TestBasic
+Test RSM basic (reliable network)...
+..
+ config.go:147: one: took too long
+```
+
+在使用 Raft 复制的常见客户端/服务架构中,服务与 Raft 有两种交互:服务 leader 通过调用 **raft.Start()** 提交客户端操作,所有服务副本通过 Raft 的 **applyCh** 接收已提交的操作并执行。在 leader 上,这两类活动会交织:某些服务器 goroutine 在处理客户端请求、已调用 **raft.Start()**,各自在等待其操作提交并得到执行结果;而 **applyCh** 上出现的已提交操作需要由服务执行,且结果需交给曾调用 **raft.Start()** 的 goroutine 以便返回给客户端。
+
+**rsm** 包封装上述交互。它位于服务(如 key/value 数据库)与 Raft 之间。你需要在 **rsm/rsm.go** 中实现:
+
+1. 一个**“reader” goroutine**,读取 applyCh
+2. 一个 **rsm.Submit()** 函数,为客户端操作调用 **raft.Start()**,然后等待 reader goroutine 把该操作的执行结果交回
+
+使用 rsm 的服务对 rsm 的 reader goroutine 呈现为提供 **DoOp()** 方法的 **StateMachine** 对象。Reader goroutine 应将每条已提交操作交给 **DoOp()**;**DoOp()** 的返回值应交给对应的 **rsm.Submit()** 调用并返回。**DoOp()** 的参数和返回值类型为 **any**;实际类型应分别与服务传给 **rsm.Submit()** 的参数和返回值类型一致。
+
+服务应将每个客户端操作传给 **rsm.Submit()**。为便于 reader goroutine 将 applyCh 消息与等待中的 **rsm.Submit()** 调用对应,**Submit()** 应将每个客户端操作与一个**唯一标识**一起包装进 **Op** 结构。**Submit()** 然后等待该操作提交并执行完毕,返回执行结果(**DoOp()** 的返回值)。若 **raft.Start()** 表明当前节点不是 Raft leader,**Submit()** 应返回 **rpc.ErrWrongLeader** 错误。**Submit()** 须检测并处理这种情况:在调用 **raft.Start()** 后 leadership 发生变化,导致该操作丢失(从未提交)。
+
+在 Part A 中,rsm 测试程序充当服务,提交被解释为对单个整数状态做自增的操作。Part B 中你将把 rsm 用作实现 **StateMachine**(及 **DoOp()**)并调用 **rsm.Submit()** 的 key/value 服务的一部分。
+
+顺利时,一次客户端请求的事件序列为:
+
+1. 客户端向服务 leader 发送请求。
+2. 服务 leader 用该请求调用 **rsm.Submit()**。
+3. **rsm.Submit()** 用该请求调用 **raft.Start()**,然后等待。
+4. Raft 提交该请求并向所有节点的 applyCh 发送。
+5. 每个节点上的 rsm reader goroutine 从 applyCh 读取该请求并交给服务的 **DoOp()**。
+6. 在 leader 上,rsm reader goroutine 将 **DoOp()** 的返回值交给最初提交该请求的 **Submit()** goroutine,**Submit()** 返回该值。
+
+你的服务器之间不应直接通信;它们只应通过 Raft 交互。
+
+**实现 rsm.go**:**Submit()** 方法以及 reader goroutine。当通过 rsm 的 4A 测试时,该任务即完成:
+
+```bash
+$ cd src/kvraft1/rsm
+$ go test -v -run 4A
+=== RUN TestBasic4A
+Test RSM basic (reliable network)...
+ ... Passed -- 1.2 3 48 0
+--- PASS: TestBasic4A (1.21s)
+=== RUN TestLeaderFailure4A
+ ... Passed -- 9223372036.9 3 31 0
+--- PASS: TestLeaderFailure4A (1.50s)
+PASS
+ok 6.5840/kvraft1/rsm 2.887s
+```
+
+* 不应需要给 Raft 的 ApplyMsg 或 AppendEntries 等 Raft RPC 增加字段,但允许这样做。
+* 你的方案须处理:rsm leader 已为 **Submit()** 提交的请求调用了 **Start()**,但在该请求提交到日志前失去了 leadership。一种做法是 rsm 通过发现 Raft 的 term 已变或 **Start()** 返回的 index 处出现了不同请求,检测到已失去 leadership,并从 **Submit()** 返回 **rpc.ErrWrongLeader**。若旧 leader 独自处于分区中,它无法得知新 leader;但同一分区内的客户端也无法联系新 leader,因此服务器无限等待直到分区恢复是可以接受的。
+* 测试在关闭节点时会调用你的 Raft 的 **rf.Kill()**。Raft 应**关闭 applyCh**,以便 rsm 得知关闭并退出所有循环。
+
+---
+
+## Part B: 无快照的 Key/value 服务
+
+```bash
+$ cd src/kvraft1
+$ go test -v -run TestBasic4B
+=== RUN TestBasic4B
+Test: one client (4B basic) (reliable network)...
+ kvtest.go:62: Wrong error
+$
+```
+
+现在用 rsm 包复制 key/value 服务器。每台服务器("**kvserver**")对应一个 rsm/Raft 节点。Clerk 向与 Raft leader 对应的 kvserver 发送 **Put()** 和 **Get()** RPC。kvserver 代码将 Put/Get 操作提交给 rsm,rsm 通过 Raft 复制并在每个节点调用你服务器的 **DoOp**,将操作应用到该节点的 key/value 数据库;目标是使各服务器维护一致的 key/value 数据库副本。
+
+Clerk 有时不知道哪台 kvserver 是 Raft leader。若 Clerk 向错误的 kvserver 发 RPC 或无法到达该 kvserver,Clerk 应**重试**,向其他 kvserver 发送。若 key/value 服务将操作提交到其 Raft 日志(从而应用到 key/value 状态机),leader 通过回复该 RPC 将结果报告给 Clerk。若操作未提交(例如 leader 被替换),服务器报告错误,Clerk 向其他服务器重试。
+
+你的 kvserver 之间不应直接通信;它们只应通过 Raft 交互。
+
+第一个任务是实现**在无丢包、无服务器失败时**正确的方案。
+
+可以将 Lab 2 的客户端代码(`kvsrv1/client.go`)复制到 `kvraft1/client.go`。需要增加决定每次 RPC 发往哪台 kvserver 的逻辑。
+
+还需在 **server.go** 中实现 **Put()** 和 **Get()** 的 RPC 处理函数。这些处理函数应通过 **rsm.Submit()** 将请求提交给 Raft。rsm 包从 **applyCh** 读取命令时,会调用 **DoOp** 方法,你将在 **server.go** 中实现。
+
+当你能**稳定**通过测试套件中第一个测试(`go test -v -run TestBasic4B`)时,该任务即完成。
+
+* 若 kvserver **不处于多数**,则**不应完成 Get() RPC**(以免提供过期数据)。一种简单做法是像每个 **Put()** 一样,通过 **Submit()** 把每个 **Get()** 也写入 Raft 日志。不必实现论文 Section 8 中只读操作的优化。
+* 最好从一开始就加锁,因为避免死锁有时会影响整体代码设计。用 **go test -race** 检查代码无数据竞争。
+
+接下来应修改方案以**在网络和服务器故障下继续正确工作**。你会遇到的一个问题是 Clerk 可能需多次发送 RPC 才能找到能正常回复的 kvserver。若 leader 在将条目提交到 Raft 日志后立即失败,Clerk 可能收不到回复,从而向另一台 leader 重发请求。对同一 version 的每次 **Clerk.Put()** 调用应**只执行一次**。
+
+**加入故障处理代码。** 你的 Clerk 可采用与 lab 2 类似的重试策略,包括在重试的 Put RPC 的回复丢失时返回 **ErrMaybe**。当你的代码能稳定通过全部 4B 测试(`go test -v -run 4B`)时,即完成。
+
+* 回忆:rsm leader 可能失去 leadership 并从 **Submit()** 返回 **rpc.ErrWrongLeader**。此时应让 Clerk 向其他服务器重发请求直到找到新 leader。
+* 可能需要修改 Clerk,使其**记住上一轮 RPC 中哪台服务器是 leader**,并优先将下一轮 RPC 发往该服务器。这样可避免每次 RPC 都重新找 leader,有助于在限定时间内通过部分测试。
+
+你的代码此时应能通过 Lab 4B 测试,例如:
+
+```bash
+$ cd kvraft1
+$ go test -run 4B
+Test: one client (4B basic) ...
+ ... Passed -- 3.2 5 1041 183
+Test: one client (4B speed) ...
+ ... Passed -- 15.9 3 3169 0
+Test: many clients (4B many clients) ...
+ ... Passed -- 3.9 5 3247 871
+Test: unreliable net, many clients (4B unreliable net, many clients) ...
+ ... Passed -- 5.3 5 1035 167
+Test: unreliable net, one client (4B progress in majority) ...
+ ... Passed -- 2.9 5 155 3
+Test: no progress in minority (4B) ...
+ ... Passed -- 1.6 5 102 3
+Test: completion after heal (4B) ...
+ ... Passed -- 1.3 5 67 4
+Test: partitions, one client (4B partitions, one client) ...
+ ... Passed -- 6.2 5 958 155
+Test: partitions, many clients (4B partitions, many clients (4B)) ...
+ ... Passed -- 6.8 5 3096 855
+Test: restarts, one client (4B restarts, one client 4B ) ...
+ ... Passed -- 6.7 5 311 13
+Test: restarts, many clients (4B restarts, many clients) ...
+ ... Passed -- 7.5 5 1223 95
+Test: unreliable net, restarts, many clients (4B unreliable net, restarts, many clients ) ...
+ ... Passed -- 8.4 5 804 33
+Test: restarts, partitions, many clients (4B restarts, partitions, many clients) ...
+ ... Passed -- 10.1 5 1308 105
+Test: unreliable net, restarts, partitions, many clients (4B unreliable net, restarts, partitions, many clients) ...
+ ... Passed -- 11.9 5 1040 33
+Test: unreliable net, restarts, partitions, random keys, many clients (4B unreliable net, restarts, partitions, random keys, many clients) ...
+ ... Passed -- 12.1 7 2801 93
+PASS
+ok 6.5840/kvraft1 103.797s
+```
+
+每个 Passed 后的数字依次为:**实际时间(秒)**、**节点数**、**发送的 RPC 数**(含客户端 RPC)、**执行的 key/value 操作数**(Clerk Get/Put 调用)。
+
+---
+
+## Part C: 带快照的 Key/value 服务
+
+目前你的 key/value 服务器没有调用 Raft 库的 **Snapshot()** 方法,因此重启的服务器必须重放完整持久化 Raft 日志才能恢复状态。现在将修改 kvserver 和 rsm,与 Raft 协作以节省日志空间并缩短重启时间,使用 Lab 3D 的 Raft **Snapshot()**。
+
+测试程序将 **maxraftstate** 传给你的 **StartKVServer()**,你再传给 rsm。**maxraftstate** 表示持久化 Raft 状态的**最大允许大小**(字节),含日志但不含快照。应将 **maxraftstate** 与 **rf.PersistBytes()** 比较。每当 rsm 检测到 Raft 状态大小接近该阈值时,应通过调用 Raft 的 **Snapshot** 保存快照。rsm 可通过调用 **StateMachine** 接口的 **Snapshot** 方法获取 kvserver 的快照来创建该快照。若 **maxraftstate** 为 **-1**,则不必做快照。maxraftstate 限制适用于你的 Raft 作为第一个参数传给 **persister.Save()** 的 GOB 编码字节。
+
+persister 对象的源码在 **tester1/persister.go**。
+
+**修改你的 rsm**,使其在检测到持久化 Raft 状态过大时向 Raft 提交快照。rsm 服务器重启时,应用 **persister.ReadSnapshot()** 读取快照,若快照长度大于零则传给 StateMachine 的 **Restore()** 方法。当通过 rsm 的 **TestSnapshot4C** 时,该任务即完成。
+
+```bash
+$ cd kvraft1/rsm
+$ go test -run TestSnapshot4C
+=== RUN TestSnapshot4C
+ ... Passed -- 9223372036.9 3 230 0
+--- PASS: TestSnapshot4C (3.88s)
+PASS
+ok 6.5840/kvraft1/rsm 3.882s
+```
+
+* 考虑 rsm **何时**应对状态做快照,以及快照中除服务器状态外还应**包含什么**。Raft 用 **Save()** 将每个快照与对应 Raft 状态一起存入 persister。可用 **ReadSnapshot()** 读取最新存储的快照。
+* 快照中存储的结构体**所有字段名首字母大写**。
+
+**实现 kvraft1/server.go 中的 Snapshot() 和 Restore() 方法**,供 rsm 调用。**修改 rsm 以处理 applyCh 上包含快照的消息。**
+
+* 该任务可能暴露出 Raft 和 rsm 库中的 bug。若修改了 Raft 实现,请确保其仍能通过全部 Lab 3 测试。
+* Lab 4 测试的合理耗时为**实际时间 400 秒**、**CPU 时间 700 秒**。
+
+你的代码应通过 4C 测试(如下例),以及 4A+B 测试(且 Raft 须继续通过 Lab 3 测试)。
+
+```bash
+$ go test -run 4C
+Test: snapshots, one client (4C SnapshotsRPC) ...
+Test: InstallSnapshot RPC (4C) ...
+ ... Passed -- 4.5 3 241 64
+Test: snapshots, one client (4C snapshot size is reasonable) ...
+ ... Passed -- 11.4 3 2526 800
+Test: snapshots, one client (4C speed) ...
+ ... Passed -- 14.2 3 3149 0
+Test: restarts, snapshots, one client (4C restarts, snapshots, one client) ...
+ ... Passed -- 6.8 5 305 13
+Test: restarts, snapshots, many clients (4C restarts, snapshots, many clients ) ...
+ ... Passed -- 9.0 5 5583 795
+Test: unreliable net, snapshots, many clients (4C unreliable net, snapshots, many clients) ...
+ ... Passed -- 4.7 5 977 155
+Test: unreliable net, restarts, snapshots, many clients (4C unreliable net, restarts, snapshots, many clients) ...
+ ... Passed -- 8.6 5 847 33
+Test: unreliable net, restarts, partitions, snapshots, many clients (4C unreliable net, restarts, partitions, snapshots, many clients) ...
+ ... Passed -- 11.5 5 841 33
+Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (4C unreliable net, restarts, partitions, snapshots, random keys, many clients) ...
+ ... Passed -- 12.8 7 2903 93
+PASS
+ok 6.5840/kvraft1 83.543s
+```
+
+---
+*来源: [6.5840 Lab 4: Fault-tolerant Key/Value Service](https://pdos.csail.mit.edu/6.824/labs/lab-kvraft1.html)*
diff --git a/docs/6.5840: Distributed System/6. Lab 4: Fault-tolerant Key-Value Service.md b/docs/6.5840: Distributed System/6. Lab 4: Fault-tolerant Key-Value Service.md
new file mode 100644
index 0000000..4223e93
--- /dev/null
+++ b/docs/6.5840: Distributed System/6. Lab 4: Fault-tolerant Key-Value Service.md
@@ -0,0 +1,224 @@
+# 6.5840 Lab 4: Fault-tolerant Key/Value Service
+
+## Introduction
+
+In this lab you will build a fault-tolerant key/value storage service using your Raft library from Lab 3. To clients, the service looks similar to the server of Lab 2. However, instead of a single server, the service consists of a set of servers that use Raft to help them maintain identical databases. Your key/value service should continue to process client requests as long as a **majority** of the servers are alive and can communicate, in spite of other failures or network partitions. After Lab 4, you will have implemented all parts (Clerk, Service, and Raft) shown in the diagram of Raft interactions.
+
+Clients will interact with your key/value service through a **Clerk**, as in Lab 2. A Clerk implements the **Put** and **Get** methods with the same semantics as Lab 2: Puts are **at-most-once** and the Puts/Gets must form a **linearizable** history.
+
+Providing linearizability is relatively easy for a single server. It is harder if the service is replicated, since all servers must choose the same execution order for concurrent requests, must avoid replying to clients using state that isn't up to date, and must recover their state after a failure in a way that preserves all acknowledged client updates.
+
+This lab has **three parts**. In **part A**, you will implement a replicated-state machine package, **rsm**, using your raft implementation; rsm is agnostic of the requests that it replicates. In **part B**, you will implement a replicated key/value service using rsm, but without using snapshots. In **part C**, you will use your snapshot implementation from Lab 3D, which will allow Raft to discard old log entries. Please submit each part by the respective deadline.
+
+You should review the [extended Raft paper](../papers/raft-extended.md), in particular **Section 7** (but not 8). For a wider perspective, have a look at Chubby, Paxos Made Live, Spanner, Zookeeper, Harp, Viewstamped Replication, and [Bolosky et al](https://pdos.csail.mit.edu/6.824/papers/bolosky-usenix2010.pdf).
+
+**Start early.**
+
+---
+
+## Getting Started
+
+We supply you with skeleton code and tests in `src/kvraft1`. The skeleton code uses the skeleton package `src/kvraft1/rsm` to replicate a server. A server must implement the **StateMachine** interface defined in rsm to replicate itself using rsm. Most of your work will be implementing rsm to provide server-agnostic replication. You will also need to modify `kvraft1/client.go` and `kvraft1/server.go` to implement the server-specific parts. This split allows you to re-use rsm in the next lab. You may be able to re-use some of your Lab 2 code (e.g., re-using the server code by copying or importing the "src/kvsrv1" package) but it is not a requirement.
+
+To get up and running, execute the following commands. Don't forget the `git pull` to get the latest software.
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+```
+
+---
+
+## Part A: Replicated State Machine (RSM)
+
+```bash
+$ cd src/kvraft1/rsm
+$ go test -v
+=== RUN TestBasic
+Test RSM basic (reliable network)...
+..
+ config.go:147: one: took too long
+```
+
+In the common situation of a client/server service using Raft for replication, the service interacts with Raft in two ways: the service leader submits client operations by calling **raft.Start()**, and all service replicas receive committed operations via Raft's **applyCh**, which they execute. On the leader, these two activities interact. At any given time, some server goroutines are handling client requests, have called **raft.Start()**, and each is waiting for its operation to commit and to find out what the result of executing the operation is. And as committed operations appear on the **applyCh**, each needs to be executed by the service, and the results need to be handed to the goroutine that called **raft.Start()** so that it can return the result to the client.
+
+The **rsm** package encapsulates the above interaction. It sits as a layer between the service (e.g. a key/value database) and Raft. In **rsm/rsm.go** you will need to implement:
+
+1. A **"reader" goroutine** that reads the applyCh
+2. A **rsm.Submit()** function that calls **raft.Start()** for a client operation and then waits for the reader goroutine to hand it the result of executing that operation
+
+The service that is using rsm appears to the rsm reader goroutine as a **StateMachine** object providing a **DoOp()** method. The reader goroutine should hand each committed operation to **DoOp()**; **DoOp()**'s return value should be given to the corresponding **rsm.Submit()** call for it to return. **DoOp()**'s argument and return value have type **any**; the actual values should have the same types as the argument and return values that the service passes to **rsm.Submit()**, respectively.
+
+The service should pass each client operation to **rsm.Submit()**. To help the reader goroutine match applyCh messages with waiting calls to **rsm.Submit()**, **Submit()** should wrap each client operation in an **Op** structure along with a **unique identifier**. **Submit()** should then wait until the operation has committed and been executed, and return the result of execution (the value returned by **DoOp()**). If **raft.Start()** indicates that the current peer is not the Raft leader, **Submit()** should return an **rpc.ErrWrongLeader** error. **Submit()** should detect and handle the situation in which leadership changed just after it called **raft.Start()**, causing the operation to be lost (never committed).
+
+For Part A, the rsm tester acts as the service, submitting operations that it interprets as increments on a state consisting of a single integer. In Part B you'll use rsm as part of a key/value service that implements **StateMachine** (and **DoOp()**), and calls **rsm.Submit()**.
+
+If all goes well, the sequence of events for a client request is:
+
+1. The client sends a request to the service leader.
+2. The service leader calls **rsm.Submit()** with the request.
+3. **rsm.Submit()** calls **raft.Start()** with the request, and then waits.
+4. Raft commits the request and sends it on all peers' applyChs.
+5. The rsm reader goroutine on each peer reads the request from the applyCh and passes it to the service's **DoOp()**.
+6. On the leader, the rsm reader goroutine hands the **DoOp()** return value to the **Submit()** goroutine that originally submitted the request, and **Submit()** returns that value.
+
+Your servers should not directly communicate; they should only interact with each other through Raft.
+
+**Implement rsm.go:** the **Submit()** method and a reader goroutine. You have completed this task if you pass the rsm 4A tests:
+
+```bash
+$ cd src/kvraft1/rsm
+$ go test -v -run 4A
+=== RUN TestBasic4A
+Test RSM basic (reliable network)...
+ ... Passed -- 1.2 3 48 0
+--- PASS: TestBasic4A (1.21s)
+=== RUN TestLeaderFailure4A
+ ... Passed -- 9223372036.9 3 31 0
+--- PASS: TestLeaderFailure4A (1.50s)
+PASS
+ok 6.5840/kvraft1/rsm 2.887s
+```
+
+* You should not need to add any fields to the Raft ApplyMsg, or to Raft RPCs such as AppendEntries, but you are allowed to do so.
+* Your solution needs to handle an rsm leader that has called **Start()** for a request submitted with **Submit()** but loses its leadership before the request is committed to the log. One way to do this is for the rsm to detect that it has lost leadership, by noticing that Raft's term has changed or a different request has appeared at the index returned by **Start()**, and return **rpc.ErrWrongLeader** from **Submit()**. If the ex-leader is partitioned by itself, it won't know about new leaders; but any client in the same partition won't be able to talk to a new leader either, so it's OK in this case for the server to wait indefinitely until the partition heals.
+* The tester calls your Raft's **rf.Kill()** when it is shutting down a peer. Raft should **close the applyCh** so that your rsm learns about the shutdown, and can exit out of all loops.
+
+---
+
+## Part B: Key/value Service without Snapshots
+
+```bash
+$ cd src/kvraft1
+$ go test -v -run TestBasic4B
+=== RUN TestBasic4B
+Test: one client (4B basic) (reliable network)...
+ kvtest.go:62: Wrong error
+$
+```
+
+Now you will use the rsm package to replicate a key/value server. Each of the servers ("**kvservers**") will have an associated rsm/Raft peer. Clerks send **Put()** and **Get()** RPCs to the kvserver whose associated Raft is the leader. The kvserver code submits the Put/Get operation to rsm, which replicates it using Raft and invokes your server's **DoOp** at each peer, which should apply the operations to the peer's key/value database; the intent is for the servers to maintain identical replicas of the key/value database.
+
+A Clerk sometimes doesn't know which kvserver is the Raft leader. If the Clerk sends an RPC to the wrong kvserver, or if it cannot reach the kvserver, the Clerk should **re-try** by sending to a different kvserver. If the key/value service commits the operation to its Raft log (and hence applies the operation to the key/value state machine), the leader reports the result to the Clerk by responding to its RPC. If the operation failed to commit (for example, if the leader was replaced), the server reports an error, and the Clerk retries with a different server.
+
+Your kvservers should not directly communicate; they should only interact with each other through Raft.
+
+Your first task is to implement a solution that **works when there are no dropped messages, and no failed servers**.
+
+Feel free to copy your client code from Lab 2 (`kvsrv1/client.go`) into `kvraft1/client.go`. You will need to add logic for deciding which kvserver to send each RPC to.
+
+You'll also need to implement **Put()** and **Get()** RPC handlers in **server.go**. These handlers should submit the request to Raft using **rsm.Submit()**. As the rsm package reads commands from **applyCh**, it should invoke the **DoOp** method, which you will have to implement in **server.go**.
+
+You have completed this task when you **reliably** pass the first test in the test suite, with `go test -v -run TestBasic4B`.
+
+* A kvserver should **not complete a Get() RPC if it is not part of a majority** (so that it does not serve stale data). A simple solution is to enter every **Get()** (as well as each **Put()**) in the Raft log using **Submit()**. You don't have to implement the optimization for read-only operations that is described in Section 8.
+* It's best to add locking from the start because the need to avoid deadlocks sometimes affects overall code design. Check that your code is race-free using **go test -race**.
+
+Now you should modify your solution to **continue in the face of network and server failures**. One problem you'll face is that a Clerk may have to send an RPC multiple times until it finds a kvserver that replies positively. If a leader fails just after committing an entry to the Raft log, the Clerk may not receive a reply, and thus may re-send the request to another leader. Each call to **Clerk.Put()** should result in **just a single execution** for a particular version number.
+
+**Add code to handle failures.** Your Clerk can use a similar retry plan as in lab 2, including returning **ErrMaybe** if a response to a retried Put RPC is lost. You are done when your code reliably passes all the 4B tests, with `go test -v -run 4B`.
+
+* Recall that the rsm leader may lose its leadership and return **rpc.ErrWrongLeader** from **Submit()**. In this case you should arrange for the Clerk to re-send the request to other servers until it finds the new leader.
+* You will probably have to modify your Clerk to **remember which server turned out to be the leader** for the last RPC, and send the next RPC to that server first. This will avoid wasting time searching for the leader on every RPC, which may help you pass some of the tests quickly enough.
+
+Your code should now pass the Lab 4B tests, like this:
+
+```bash
+$ cd kvraft1
+$ go test -run 4B
+Test: one client (4B basic) ...
+ ... Passed -- 3.2 5 1041 183
+Test: one client (4B speed) ...
+ ... Passed -- 15.9 3 3169 0
+Test: many clients (4B many clients) ...
+ ... Passed -- 3.9 5 3247 871
+Test: unreliable net, many clients (4B unreliable net, many clients) ...
+ ... Passed -- 5.3 5 1035 167
+Test: unreliable net, one client (4B progress in majority) ...
+ ... Passed -- 2.9 5 155 3
+Test: no progress in minority (4B) ...
+ ... Passed -- 1.6 5 102 3
+Test: completion after heal (4B) ...
+ ... Passed -- 1.3 5 67 4
+Test: partitions, one client (4B partitions, one client) ...
+ ... Passed -- 6.2 5 958 155
+Test: partitions, many clients (4B partitions, many clients (4B)) ...
+ ... Passed -- 6.8 5 3096 855
+Test: restarts, one client (4B restarts, one client 4B ) ...
+ ... Passed -- 6.7 5 311 13
+Test: restarts, many clients (4B restarts, many clients) ...
+ ... Passed -- 7.5 5 1223 95
+Test: unreliable net, restarts, many clients (4B unreliable net, restarts, many clients ) ...
+ ... Passed -- 8.4 5 804 33
+Test: restarts, partitions, many clients (4B restarts, partitions, many clients) ...
+ ... Passed -- 10.1 5 1308 105
+Test: unreliable net, restarts, partitions, many clients (4B unreliable net, restarts, partitions, many clients) ...
+ ... Passed -- 11.9 5 1040 33
+Test: unreliable net, restarts, partitions, random keys, many clients (4B unreliable net, restarts, partitions, random keys, many clients) ...
+ ... Passed -- 12.1 7 2801 93
+PASS
+ok 6.5840/kvraft1 103.797s
+```
+
+The numbers after each Passed are: **real time in seconds**, **number of peers**, **number of RPCs sent** (including client RPCs), and **number of key/value operations executed** (Clerk Get/Put calls).
+
+---
+
+## Part C: Key/value Service with Snapshots
+
+As things stand now, your key/value server doesn't call your Raft library's **Snapshot()** method, so a rebooting server has to replay the complete persisted Raft log in order to restore its state. Now you'll modify kvserver and rsm to cooperate with Raft to save log space and reduce restart time, using Raft's **Snapshot()** from Lab 3D.
+
+The tester passes **maxraftstate** to your **StartKVServer()**, which passes it to rsm. **maxraftstate** indicates the **maximum allowed size** of your persistent Raft state in bytes (including the log, but not including snapshots). You should compare **maxraftstate** to **rf.PersistBytes()**. Whenever your rsm detects that the Raft state size is approaching this threshold, it should save a snapshot by calling Raft's **Snapshot**. rsm can create this snapshot by calling the **Snapshot** method of the **StateMachine** interface to obtain a snapshot of the kvserver. If **maxraftstate** is **-1**, you do not have to snapshot. The maxraftstate limit applies to the GOB-encoded bytes your Raft passes as the first argument to **persister.Save()**.
+
+You can find the source for the persister object in **tester1/persister.go**.
+
+**Modify your rsm** so that it detects when the persisted Raft state grows too large, and then hands a snapshot to Raft. When a rsm server restarts, it should read the snapshot with **persister.ReadSnapshot()** and, if the snapshot's length is greater than zero, pass the snapshot to the StateMachine's **Restore()** method. You complete this task if you pass **TestSnapshot4C** in rsm.
+
+```bash
+$ cd kvraft1/rsm
+$ go test -run TestSnapshot4C
+=== RUN TestSnapshot4C
+ ... Passed -- 9223372036.9 3 230 0
+--- PASS: TestSnapshot4C (3.88s)
+PASS
+ok 6.5840/kvraft1/rsm 3.882s
+```
+
+* Think about **when** rsm should snapshot its state and **what** should be included in the snapshot beyond just the server state. Raft stores each snapshot in the persister object using **Save()**, along with corresponding Raft state. You can read the latest stored snapshot using **ReadSnapshot()**.
+* **Capitalize all fields** of structures stored in the snapshot.
+
+**Implement the kvraft1/server.go Snapshot() and Restore() methods**, which rsm calls. **Modify rsm to handle applyCh messages that contain snapshots.**
+
+* You may have bugs in your Raft and rsm library that this task exposes. If you make changes to your Raft implementation make sure it continues to pass all of the Lab 3 tests.
+* A reasonable amount of time to take for the Lab 4 tests is **400 seconds** of real time and **700 seconds** of CPU time.
+
+Your code should pass the 4C tests (as in the example here) as well as the 4A+B tests (and your Raft must continue to pass the Lab 3 tests).
+
+```bash
+$ go test -run 4C
+Test: snapshots, one client (4C SnapshotsRPC) ...
+Test: InstallSnapshot RPC (4C) ...
+ ... Passed -- 4.5 3 241 64
+Test: snapshots, one client (4C snapshot size is reasonable) ...
+ ... Passed -- 11.4 3 2526 800
+Test: snapshots, one client (4C speed) ...
+ ... Passed -- 14.2 3 3149 0
+Test: restarts, snapshots, one client (4C restarts, snapshots, one client) ...
+ ... Passed -- 6.8 5 305 13
+Test: restarts, snapshots, many clients (4C restarts, snapshots, many clients ) ...
+ ... Passed -- 9.0 5 5583 795
+Test: unreliable net, snapshots, many clients (4C unreliable net, snapshots, many clients) ...
+ ... Passed -- 4.7 5 977 155
+Test: unreliable net, restarts, snapshots, many clients (4C unreliable net, restarts, snapshots, many clients) ...
+ ... Passed -- 8.6 5 847 33
+Test: unreliable net, restarts, partitions, snapshots, many clients (4C unreliable net, restarts, partitions, snapshots, many clients) ...
+ ... Passed -- 11.5 5 841 33
+Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (4C unreliable net, restarts, partitions, snapshots, random keys, many clients) ...
+ ... Passed -- 12.8 7 2903 93
+PASS
+ok 6.5840/kvraft1 83.543s
+```
+
+---
+*From: [6.5840 Lab 4: Fault-tolerant Key/Value Service](https://pdos.csail.mit.edu/6.824/labs/lab-kvraft1.html)*
diff --git a/docs/6.5840: Distributed System/7. Lab 5: Sharded Key-Value Service-cn.md b/docs/6.5840: Distributed System/7. Lab 5: Sharded Key-Value Service-cn.md
new file mode 100644
index 0000000..0423d9d
--- /dev/null
+++ b/docs/6.5840: Distributed System/7. Lab 5: Sharded Key-Value Service-cn.md
@@ -0,0 +1,258 @@
+# 6.5840 Lab 5: Sharded Key/Value Service
+
+## 简介
+
+你可以选择做基于自己想法的期末项目,或做本实验。
+
+本实验中你将构建一个 key/value 存储系统,在一组由 Raft 复制的 key/value 服务器组(**shardgrps**)上对 key 进行 **"shard"**(分片/分区)。一个 **shard** 是 key/value 对的一个子集;例如所有以 "a" 开头的 key 可以是一个 shard,以 "b" 开头的为另一个,等等。分片的目的是**性能**。每个 shardgrp 只处理少数 shard 的 put 和 get,各 shardgrp 并行工作;因此系统总吞吐(单位时间内的 put/get 数)随 shardgrp 数量增加。
+
+分片 key/value 服务的组件见实验示意图。**Shardgrps**(蓝色方块)存储带 key 的 shard:shardgrp 1 存 key "a" 的 shard,shardgrp 2 存 key "b" 的 shard。客户端通过 **clerk**(绿色圆)与服务交互,clerk 实现 **Get** 和 **Put** 方法。为找到 Put/Get 所传 key 对应的 shardgrp,clerk 从 **kvsrv**(黑色方块,即你在 **Lab 2** 实现的)获取 **configuration**。Configuration 描述从 shard 到 shardgrp 的映射(例如 shard 1 由 shardgrp 3 服务)。
+
+管理员(即测试程序)使用另一个客户端 **controller**(紫色圆)向集群添加/移除 shardgrp 并更新应由哪个 shardgrp 服务哪个 shard。Controller 有一个主要方法:**ChangeConfigTo**,以新 configuration 为参数,将系统从当前 configuration 切换到新 configuration;这涉及将 shard 迁移到新加入的 shardgrp、以及从即将离开的 shardgrp 迁出。为此 controller 1) 向 shardgrp 发 RPC(**FreezeShard**、**InstallShard**、**DeleteShard**),2) 更新存储在 kvsrv 中的 configuration。
+
+引入 controller 是因为分片存储系统必须能**在 shardgrp 之间迁移 shard**:用于负载均衡,或当 shardgrp 加入、离开时(新容量、维修、下线)。
+
+本实验的主要挑战是在 1) shard 到 shardgrp 的分配发生变化,以及 2) controller 在 **ChangeConfigTo** 期间失败或处于分区时恢复的情况下,保证 Get/Put 操作的 **linearizability**。
+
+1. **若 ChangeConfigTo 在重配置过程中失败**,部分 shard 可能已开始但未完成从一 shardgrp 迁到另一 shardgrp,从而不可访问。测试会启动新的 controller;你的任务是确保新的能完成旧 controller 未完成的重配置。
+2. **ChangeConfigTo 会在 shardgrp 之间迁移 shard**。你必须保证**任意时刻每个 shard 最多只有一个 shardgrp 在服务请求**,这样使用旧 shardgrp 与新 shardgrp 的客户端不会破坏 linearizability。
+
+本实验用 "configuration" 指 **shard 到 shardgrp 的分配**。这与 Raft 集群成员变更**不是**一回事;不需要实现 Raft 集群成员变更。
+
+一个 shardgrp 服务器只属于一个 shardgrp。给定 shardgrp 内的服务器集合不会改变。
+
+客户端与服务器之间的交互**只能通过 RPC**(不得使用共享 Go 变量或文件)。
+
+* **Part A**:实现可用的 **shardctrler**(在 kvsrv 中存储/读取 configuration)、**shardgrp**(用 Raft rsm 复制)和 **shardgrp clerk**。shardctrler 通过 shardgrp clerk 迁移 shard。
+* **Part B**:修改 shardctrler,在 configuration 变更期间处理故障与分区。
+* **Part C**:允许多个 controller 并发且互不干扰。
+* **Part D**:以任意方式扩展你的方案(可选)。
+
+本实验的设计与 Flat Datacenter Storage、BigTable、Spanner、FAWN、Apache HBase、Rosebud、Spinnaker 等思路一致(细节不同)。
+
+Lab 5 将使用你在 **Lab 2** 的 **kvsrv**,以及 **Lab 4** 的 **rsm 和 Raft**。Lab 5 与 Lab 4 必须使用相同的 rsm 和 Raft 实现。
+
+迟交时长仅可用于 **Part A**;**不能**用于 Part B–D。
+
+---
+
+## 起步
+
+执行 `git pull` 获取最新实验代码。
+
+我们在 **src/shardkv1** 中提供了测试和骨架代码:
+
+* **shardctrler** 包:`shardctrler.go`,包含 controller 变更 configuration 的 **ChangeConfigTo** 和获取 configuration 的 **Query**
+* **shardgrp** 包:shardgrp clerk 与 server
+* **shardcfg** 包:计算 shard configuration
+* **client.go**:shardkv clerk
+
+运行以下命令即可开始:
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+$ cd src/shardkv1
+$ go test -v
+=== RUN TestInitQuery5A
+Test (5A): Init and Query ... (reliable network)...
+ shardkv_test.go:46: Static wrong null 0
+...
+```
+
+---
+
+## Part A: 迁移 Shard(困难)
+
+第一个任务是:在无故障时实现 shardgrp 以及 **InitConfig**、**Query**、**ChangeConfigTo**。Configuration 的代码在 **shardkv1/shardcfg**。每个 **shardcfg.ShardConfig** 有唯一编号 **Num**、从 shard 编号到 group 编号的映射、以及从 group 编号到复制该 group 的服务器列表的映射。通常 shard 数多于 group 数,以便以较细粒度调整负载。
+
+### 1. InitConfig 与 Query(尚无 shardgrp)
+
+在 **shardctrler/shardctrler.go** 中实现:
+
+* **Query**:返回当前 configuration;从 kvsrv 读取(由 InitConfig 存储)。
+* **InitConfig**:接收第一个 configuration(测试程序提供的 **shardcfg.ShardConfig**)并存入 Lab 2 的 **kvsrv** 实例。
+
+用 **ShardCtrler.IKVClerk** 的 Get/Put 与 kvsrv 通信,用 **ShardConfig.String()** 序列化后 Put,用 **shardcfg.FromString()** 反序列化。通过第一个测试时即完成:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run TestInitQuery5A
+Test (5A): Init and Query ... (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 3 #Ops 0
+PASS
+ok 6.5840/shardkv1 0.197s
+```
+
+### 2. Shardgrp 与 shardkv clerk(Static 测试)
+
+通过从 Lab 4 kvraft 方案复制,在 **shardkv1/shardgrp/server.go** 实现 **shardgrp** 的初始版本,在 **shardkv1/shardgrp/client.go** 实现 **shardgrp clerk**。在 **shardkv1/client.go** 实现 **shardkv clerk**:用 **Query** 找到 key 对应的 shardgrp,再与该 shardgrp 通信。通过 **Static** 测试时即完成。
+
+* 创建时,第一个 shardgrp(**shardcfg.Gid1**)应将自己初始化为**拥有所有 shard**。
+* **shardkv1/client.go** 的 Put 在回复可能丢失时必须返回 **ErrMaybe**;内部(shardgrp)的 Put 可用错误表示这一点。
+* 要向 shardgrp put/get 一个 key,shardkv clerk 应通过 **shardgrp.MakeClerk** 创建 shardgrp clerk,传入 configuration 中的服务器以及 shardkv clerk 的 **ck.clnt**。用 **ShardConfig.GidServers()** 获取 shard 的 group。
+* 用 **shardcfg.Key2Shard()** 得到 key 的 shard 编号。测试程序将 **ShardCtrler** 传给 **shardkv1/client.go** 的 **MakeClerk**;用 **Query** 获取当前 configuration。
+* 可从 kvraft 的 **client.go** 和 **server.go** 复制 Put/Get 及相关代码。
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run Static
+Test (5A): one shard group ... (reliable network)...
+ ... Passed -- time 5.4s #peers 1 #RPCs 793 #Ops 180
+PASS
+ok 6.5840/shardkv1 5.632s
+```
+
+### 3. ChangeConfigTo 与 shard 迁移(JoinBasic、DeleteBasic)
+
+通过实现 **ChangeConfigTo** 支持**在 group 之间迁移 shard**:从旧 configuration 切换到新 configuration。新 configuration 可能加入新 shardgrp 或移除现有 shardgrp。Controller 必须迁移 shard **数据**,使每个 shardgrp 存储的 shard 与新 configuration 一致。
+
+**迁移一个 shard 的建议流程:**
+
+1. 在源 shardgrp **Freeze** 该 shard(该 shardgrp 拒绝对该迁移中 shard 的 key 的 Put)。
+2. **Install**(复制)该 shard 到目标 shardgrp。
+3. 在源端 **Delete** 已 freeze 的 shard。
+4. **Post** 新 configuration,使客户端能找到迁移后的 shard。
+
+这样避免 shardgrp 之间直接交互,并允许继续服务未参与变更的 shard。
+
+**顺序**:每个 configuration 有唯一 **Num**(见 **shardcfg/shardcfg.go**)。Part A 中测试程序顺序调用 ChangeConfigTo;新 config 的 **Num** 比前一个大 1。为拒绝过时 RPC,**FreezeShard**、**InstallShard**、**DeleteShard** 应包含 **Num**(见 **shardgrp/shardrpc/shardrpc.go**),且 shardgrp 须记住每个 shard 见过的**最大 Num**。
+
+在 **shardctrler/shardctrler.go** 中实现 **ChangeConfigTo**,并扩展 shardgrp 支持 **freeze**、**install**、**delete**。在 **shardgrp/client.go** 和 **shardgrp/server.go** 中实现 **FreezeShard**、**InstallShard**、**DeleteShard**,使用 **shardgrp/shardrpc** 中的 RPC,并根据 Num 拒绝过时 RPC。修改 **shardkv1/client.go** 中的 shardkv clerk 以处理 **ErrWrongGroup**(当 shardgrp 不负责该 shard 时返回)。先通过 **JoinBasic** 和 **DeleteBasic**(加入 group;离开可稍后)。
+
+* 像 Put 和 Get 一样,通过你的 **rsm** 包执行 **FreezeShard**、**InstallShard**、**DeleteShard**。
+* 若 RPC 回复中包含属于服务器状态的 **map**,可能产生数据竞争;**在回复中附带该 map 的副本**。
+* 可以在 RPC 请求/回复中发送整个 map,使 shard 迁移代码更简单。
+* 若 Put/Get 的 key 的 shard 未分配给该 shardgrp,shardgrp 应返回 **ErrWrongGroup**;**shardkv1/client.go** 应重新读取 configuration 并重试。
+
+### 4. 离开的 Shardgrps(TestJoinLeaveBasic5A)
+
+扩展 **ChangeConfigTo** 以处理**离开**的 shardgrp(在当前 config 中但不在新 config 中)。通过 **TestJoinLeaveBasic5A**。
+
+### 5. 全部 Part A 测试
+
+你的方案必须**在 configuration 变更进行时继续服务未受影响的 shard**。通过全部 Part A 测试:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run 5A
+Test (5A): Init and Query ... (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 3 #Ops 0
+Test (5A): one shard group ... (reliable network)...
+ ... Passed -- time 5.1s #peers 1 #RPCs 792 #Ops 180
+Test (5A): a group joins... (reliable network)...
+ ... Passed -- time 12.9s #peers 1 #RPCs 6300 #Ops 180
+...
+Test (5A): many concurrent clerks unreliable... (unreliable network)...
+ ... Passed -- time 25.3s #peers 1 #RPCs 7553 #Ops 1896
+PASS
+ok 6.5840/shardkv1 243.115s
+```
+
+---
+
+## Part B: 处理失败的 Controller(简单)
+
+Controller 生命周期短,在迁移 shard 时可能**失败或失去连接**。任务是在启动新 controller 时**恢复**:新 controller 必须**完成**前一个未完成的重配置。测试程序在启动 controller 时调用 **InitController**;你可以在其中实现恢复。
+
+**做法**:在 controller 的 kvsrv 中维护**两个 configuration**:**current** 和 **next**。Controller 开始重配置时存储 next configuration。完成时把 next 变为 current。在 **InitController** 中,若存在存储的 **next** configuration 且其 Num 大于 current,则**完成 shard 迁移**以重配置到该 next config。
+
+从前一个失败 controller 继续的 controller 可能**重复** FreezeShard、InstallShard、Delete RPC;shardgrp 可用 **Num** 检测重复并拒绝。
+
+在 shardctrler 中实现上述逻辑。通过 Part B 测试时即完成:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run 5B
+Test (5B): Join/leave while a shardgrp is down... (reliable network)...
+ ... Passed -- time 9.2s #peers 1 #RPCs 899 #Ops 120
+Test (5B): recover controller ... (reliable network)...
+ ... Passed -- time 26.4s #peers 1 #RPCs 3724 #Ops 360
+PASS
+ok 6.5840/shardkv1 35.805s
+```
+
+* 在 **shardctrler/shardctrler.go** 的 **InitController** 中实现恢复。
+
+---
+
+## Part C: 并发 Configuration 变更(中等)
+
+修改 controller 以允许**多个 controller 并发**。当某个失败或处于分区时,测试会启动新的,新 controller 必须完成任何进行中的工作(同 Part B)。因此多个 controller 可能并发运行,向 shardgrp 和 kvsrv 发 RPC。
+
+**挑战**:确保 controller **互不干扰**。Part A 中你已用 **Num** 对 shardgrp RPC 做 fencing,过时 RPC 会被拒绝;多个 controller 的重复工作是安全的。剩余问题是**只有一个 controller** 应更新 **next** configuration,这样两个 controller(例如分区中的与新的)不会为同一 Num 写入不同 config。测试会并发运行多个 controller;每个读取当前 config、为 join/leave 更新、然后调用 ChangeConfigTo——因此多个 controller 可能用**同一 Num 的不同 config** 调用 ChangeConfigTo。可使用 **version 与带 version 的 Put**,使只有一个 controller 能成功提交该 Num 的 next config,其他直接返回不做任何事。
+
+修改 controller,使**对给定 configuration Num 只有一个 controller 能提交 next configuration**。通过并发测试:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run TestConcurrentReliable5C
+Test (5C): Concurrent ctrlers ... (reliable network)...
+ ... Passed -- time 8.2s #peers 1 #RPCs 1753 #Ops 120
+PASS
+ok 6.5840/shardkv1 8.364s
+
+$ go test -run TestAcquireLockConcurrentUnreliable5C
+Test (5C): Concurrent ctrlers ... (unreliable network)...
+ ... Passed -- time 23.8s #peers 1 #RPCs 1850 #Ops 120
+PASS
+ok 6.5840/shardkv1 24.008s
+```
+
+* 参见 **test.go** 中的 **concurCtrler** 了解测试如何并发运行 controller。
+
+**恢复 + 新 controller**:新 controller 仍应执行 Part B 的恢复。若旧 controller 在 ChangeConfigTo 期间处于分区,确保旧的不干扰新的。若所有 controller 更新都用 Num 正确 fencing(Part B),可能不需要额外代码。通过 **Partition** 测试:
+
+```bash
+$ go test -run Partition
+Test (5C): partition controller in join... (reliable network)...
+ ... Passed -- time 7.8s #peers 1 #RPCs 876 #Ops 120
+...
+Test (5C): controllers with leased leadership ... (unreliable network)...
+ ... Passed -- time 60.5s #peers 1 #RPCs 11422 #Ops 2336
+PASS
+ok 6.5840/shardkv1 217.779s
+```
+
+重新运行全部测试,确保最近的 controller 修改没有破坏前面的部分。
+
+**Gradescope** 会运行 Lab 3A–D、Lab 4A–C 和 5C 测试。提交前:
+
+```bash
+$ go test ./raft1
+$ go test ./kvraft1
+$ go test ./shardkv1
+```
+
+---
+
+## Part D: 扩展你的方案
+
+在这最后一部分你可以**以任意方式扩展**你的方案。你必须**为自己的扩展编写测试**。
+
+实现下列想法之一或你自己的想法。在 **extension.md** 中写**一段话**描述你的扩展,并将 **extension.md** 上传到 Gradescope。对较难、开放式的扩展,可与另一名同学组队。
+
+**想法(前几个较易,后面更开放):**
+
+* **(难)** 修改 shardkv 以支持**事务**(跨 shard 的多个 Put 和 Get 原子执行)。实现两阶段提交与两阶段锁。编写测试。
+* **(难)** 在 kvraft 中支持**事务**(多个 Put/Get 原子)。这样带 version 的 Put 不再必要。参见 [etcd's transactions](https://etcd.io/docs/v3.4/learning/api/)。编写测试。
+* **(难)** 让 kvraft **leader 不经 rsm 直接处理 Get**(Raft 论文 Section 8 末尾的优化,含 **leases**),并保持 linearizability。通过现有 kvraft 测试。增加测试:优化后的 Get 更快(如更少 RPC)、以及 term 切换更慢(新 leader 等待 lease 过期)。
+* **(中等)** 为 kvsrv 增加 **Range** 函数(从 low 到 high 的 key)。偷懒做法:遍历 key/value map;更好做法:支持范围查询的数据结构(如 B-tree)。包含一个在偷懒实现下失败、在更好实现下通过的测试。
+* **(中等)** 将 kvsrv 改为 **恰好一次** Put/Get 语义(如 Lab 2 丢包风格)。在 kvraft 中也实现恰好一次。可移植 2024 的测试。
+* **(简单)** 修改测试程序,使 controller 使用 **kvraft** 而非 kvsrv(例如在 test.go 的 MakeTestMaxRaft 中用 kvraft.StartKVServer 替换 kvsrv.StartKVServer)。编写测试:在一个 kvraft 节点宕机时 controller 仍能查询/更新 configuration。测试代码在 **src/kvtest1**、**src/shardkv1**、**src/tester1**。
+
+---
+
+## 提交步骤
+
+提交前最后运行一遍全部测试:
+
+```bash
+$ go test ./raft1
+$ go test ./kvraft1
+$ go test ./shardkv1
+```
+
+---
+*来源: [6.5840 Lab 5: Sharded Key/Value Service](https://pdos.csail.mit.edu/6.824/labs/lab-shard1.html)*
diff --git a/docs/6.5840: Distributed System/7. Lab 5: Sharded Key-Value Service.md b/docs/6.5840: Distributed System/7. Lab 5: Sharded Key-Value Service.md
new file mode 100644
index 0000000..bc2b16a
--- /dev/null
+++ b/docs/6.5840: Distributed System/7. Lab 5: Sharded Key-Value Service.md
@@ -0,0 +1,258 @@
+# 6.5840 Lab 5: Sharded Key/Value Service
+
+## Introduction
+
+You can either do a final project based on your own ideas, or this lab.
+
+In this lab you'll build a key/value storage system that **"shards,"** or partitions, the keys over a set of Raft-replicated key/value server groups (**shardgrps**). A **shard** is a subset of the key/value pairs; for example, all the keys starting with "a" might be one shard, all the keys starting with "b" another, etc. The reason for sharding is **performance**. Each shardgrp handles puts and gets for just a few of the shards, and the shardgrps operate in parallel; thus total system throughput (puts and gets per unit time) increases in proportion to the number of shardgrps.
+
+The sharded key/value service has the components shown in the lab diagram. **Shardgrps** (blue squares) store shards with keys: shardgrp 1 holds a shard storing key "a", and shardgrp 2 holds a shard storing key "b". Clients interact with the service through a **clerk** (green circle), which implements **Get** and **Put** methods. To find the shardgrp for a key passed to Put/Get, the clerk gets the **configuration** from the **kvsrv** (black square), which you implemented in **Lab 2**. The configuration describes the mapping from shards to shardgrps (e.g., shard 1 is served by shardgrp 3).
+
+An administrator (i.e., the tester) uses another client, the **controller** (purple circle), to add/remove shardgrps from the cluster and update which shardgrp should serve a shard. The controller has one main method: **ChangeConfigTo**, which takes as argument a new configuration and changes the system from the current configuration to the new configuration; this involves moving shards to new shardgrps that are joining and moving shards away from shardgrps that are leaving. To do so the controller 1) makes RPCs (**FreezeShard**, **InstallShard**, and **DeleteShard**) to shardgrps, and 2) updates the configuration stored in kvsrv.
+
+The reason for the controller is that a sharded storage system must be able to **shift shards among shardgrps**: for load balancing, or when shardgrps join and leave (new capacity, repair, retirement).
+
+The main challenges in this lab will be ensuring **linearizability** of Get/Put operations while handling 1) changes in the assignment of shards to shardgrps, and 2) recovering from a controller that fails or is partitioned during **ChangeConfigTo**.
+
+1. **If ChangeConfigTo fails while reconfiguring**, some shards may be inaccessible if they have started but not completed moving from one shardgrp to another. The tester starts a new controller; your job is to ensure that the new one completes the reconfiguration that the previous controller started.
+2. **ChangeConfigTo moves shards** from one shardgrp to another. You must ensure that **at most one shardgrp is serving requests for each shard at any one time**, so that clients using old vs new shardgrp don't break linearizability.
+
+This lab uses "configuration" to refer to the **assignment of shards to shardgrps**. This is **not** the same as Raft cluster membership changes; you don't have to implement Raft cluster membership changes.
+
+A shardgrp server is a member of only a single shardgrp. The set of servers in a given shardgrp will never change.
+
+**Only RPC** may be used for interaction among clients and servers (no shared Go variables or files).
+
+* **Part A**: Implement a working **shardctrler** (store/retrieve configurations in kvsrv), the **shardgrp** (replicated with Raft rsm), and a **shardgrp clerk**. The shardctrler talks to shardgrp clerks to move shards.
+* **Part B**: Modify shardctrler to handle failures and partitions during config changes.
+* **Part C**: Allow concurrent controllers without interfering with each other.
+* **Part D**: Extend your solution in any way you like (optional).
+
+This lab's design is in the same general spirit as Flat Datacenter Storage, BigTable, Spanner, FAWN, Apache HBase, Rosebud, Spinnaker, and others (details differ).
+
+Lab 5 will use your **kvsrv from Lab 2**, and your **rsm and Raft from Lab 4**. Lab 5 and Lab 4 must use the same rsm and Raft implementations.
+
+You may use late hours for **Part A** only; you may **not** use late hours for Parts B–D.
+
+---
+
+## Getting Started
+
+Do a `git pull` to get the latest lab software.
+
+We supply you with tests and skeleton code in **src/shardkv1**:
+
+* **shardctrler** package: `shardctrler.go` with methods for the controller to change a configuration (**ChangeConfigTo**) and to get a configuration (**Query**)
+* **shardgrp** package: shardgrp clerk and server
+* **shardcfg** package: for computing shard configurations
+* **client.go**: shardkv clerk
+
+To get up and running:
+
+```bash
+$ cd ~/6.5840
+$ git pull
+...
+$ cd src/shardkv1
+$ go test -v
+=== RUN TestInitQuery5A
+Test (5A): Init and Query ... (reliable network)...
+ shardkv_test.go:46: Static wrong null 0
+...
+```
+
+---
+
+## Part A: Moving Shards (hard)
+
+Your first job is to implement shardgrps and the **InitConfig**, **Query**, and **ChangeConfigTo** methods when there are no failures. The code for describing a configuration is in **shardkv1/shardcfg**. Each **shardcfg.ShardConfig** has a unique identifying number **Num**, a mapping from shard number to group number, and a mapping from group number to the list of servers replicating that group. There will usually be more shards than groups so that load can be shifted at a fairly fine granularity.
+
+### 1. InitConfig and Query (no shardgrps yet)
+
+Implement in **shardctrler/shardctrler.go**:
+
+* **Query**: returns the current configuration; read it from kvsrv (stored there by InitConfig).
+* **InitConfig**: receives the first configuration (a **shardcfg.ShardConfig** from the tester) and stores it in an instance of Lab 2's **kvsrv**.
+
+Use **ShardCtrler.IKVClerk** Get/Put to talk to kvsrv, **ShardConfig.String()** to serialize for Put, and **shardcfg.FromString()** to deserialize. You're done when you pass the first test:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run TestInitQuery5A
+Test (5A): Init and Query ... (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 3 #Ops 0
+PASS
+ok 6.5840/shardkv1 0.197s
+```
+
+### 2. Shardgrp and shardkv clerk (Static test)
+
+Implement an initial version of **shardgrp** in **shardkv1/shardgrp/server.go** and a **shardgrp clerk** in **shardkv1/shardgrp/client.go** by copying from your Lab 4 kvraft solution. Implement the **shardkv clerk** in **shardkv1/client.go** that uses **Query** to find the shardgrp for a key, then talks to that shardgrp. You're done when you pass the **Static** test.
+
+* Upon creation, the first shardgrp (**shardcfg.Gid1**) should initialize itself to **own all shards**.
+* **shardkv1/client.go**'s Put must return **ErrMaybe** when the reply was maybe lost; the inner (shardgrp) Put can signal this with an error.
+* To put/get a key from a shardgrp, the shardkv clerk should create a shardgrp clerk via **shardgrp.MakeClerk**, passing the servers from the configuration and the shardkv clerk's **ck.clnt**. Use **ShardConfig.GidServers()** to get the group for a shard.
+* Use **shardcfg.Key2Shard()** to find the shard number for a key. The tester passes a **ShardCtrler** to **MakeClerk** in **shardkv1/client.go**; use **Query** to get the current configuration.
+* You can copy Put/Get and related code from kvraft **client.go** and **server.go**.
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run Static
+Test (5A): one shard group ... (reliable network)...
+ ... Passed -- time 5.4s #peers 1 #RPCs 793 #Ops 180
+PASS
+ok 6.5840/shardkv1 5.632s
+```
+
+### 3. ChangeConfigTo and shard movement (JoinBasic, DeleteBasic)
+
+Support **movement of shards among groups** by implementing **ChangeConfigTo**: it changes from an old configuration to a new one. The new configuration may add new shardgrps or remove existing ones. The controller must move shard **data** so that each shardgrp's stored shards match the new configuration.
+
+**Suggested approach for moving a shard:**
+
+1. **Freeze** the shard at the source shardgrp (that shardgrp rejects Puts for keys in the moving shard).
+2. **Install** (copy) the shard to the destination shardgrp.
+3. **Delete** the frozen shard at the source.
+4. **Post** the new configuration so clients can find the moved shard.
+
+This avoids direct shardgrp-to-shardgrp interaction and allows serving shards not involved in the change.
+
+**Ordering:** Each configuration has a unique **Num** (see **shardcfg/shardcfg.go**). In Part A the tester calls ChangeConfigTo sequentially; the new config has **Num** one larger than the previous. To reject stale RPCs, **FreezeShard**, **InstallShard**, and **DeleteShard** should include **Num** (see **shardgrp/shardrpc/shardrpc.go**), and shardgrps must remember the **largest Num** they have seen for each shard.
+
+Implement **ChangeConfigTo** in **shardctrler/shardctrler.go** and extend shardgrp to support **freeze**, **install**, and **delete**. Implement **FreezeShard**, **InstallShard**, **DeleteShard** in **shardgrp/client.go** and **shardgrp/server.go** using the RPCs in **shardgrp/shardrpc**, and reject old RPCs based on Num. Modify the shardkv clerk in **shardkv1/client.go** to handle **ErrWrongGroup** (returned when the shardgrp is not responsible for the shard). Pass **JoinBasic** and **DeleteBasic** first (joining groups; leaving can come next).
+
+* Run **FreezeShard**, **InstallShard**, **DeleteShard** through your **rsm** package, like Put and Get.
+* If an RPC reply includes a **map** that is part of server state, you may get races; **include a copy** of the map in the reply.
+* You can send an entire map in an RPC request/reply to keep shard transfer code simple.
+* A shardgrp should return **ErrWrongGroup** for a Put/Get whose key's shard is not assigned to it; **shardkv1/client.go** should reread the configuration and retry.
+
+### 4. Shardgrps that leave (TestJoinLeaveBasic5A)
+
+Extend **ChangeConfigTo** to handle shardgrps that **leave** (in current config but not in the new one). Pass **TestJoinLeaveBasic5A**.
+
+### 5. All Part A tests
+
+Your solution must **continue serving shards that are not affected** by an ongoing configuration change. Pass all Part A tests:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run 5A
+Test (5A): Init and Query ... (reliable network)...
+ ... Passed -- time 0.0s #peers 1 #RPCs 3 #Ops 0
+Test (5A): one shard group ... (reliable network)...
+ ... Passed -- time 5.1s #peers 1 #RPCs 792 #Ops 180
+Test (5A): a group joins... (reliable network)...
+ ... Passed -- time 12.9s #peers 1 #RPCs 6300 #Ops 180
+...
+Test (5A): many concurrent clerks unreliable... (unreliable network)...
+ ... Passed -- time 25.3s #peers 1 #RPCs 7553 #Ops 1896
+PASS
+ok 6.5840/shardkv1 243.115s
+```
+
+---
+
+## Part B: Handling a Failed Controller (easy)
+
+The controller is short-lived and may **fail or lose connectivity** while moving shards. The task is to **recover** when a new controller is started: the new controller must **finish the reconfiguration** that the previous one started. The tester calls **InitController** when starting a controller; you can implement recovery there.
+
+**Approach:** Keep **two configurations** in the controller's kvsrv: **current** and **next**. When a controller starts a reconfiguration, it stores the next configuration. When it completes, it makes next the current. In **InitController**, check if there is a stored **next** configuration with a higher Num than current; if so, **complete the shard moves** to reconfigure to that next config.
+
+A controller that continues from a failed one may **repeat** FreezeShard, InstallShard, Delete RPCs; shardgrps can use **Num** to detect duplicates and reject them.
+
+Implement this in the shardctrler. You're done when you pass the Part B tests:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run 5B
+Test (5B): Join/leave while a shardgrp is down... (reliable network)...
+ ... Passed -- time 9.2s #peers 1 #RPCs 899 #Ops 120
+Test (5B): recover controller ... (reliable network)...
+ ... Passed -- time 26.4s #peers 1 #RPCs 3724 #Ops 360
+PASS
+ok 6.5840/shardkv1 35.805s
+```
+
+* Implement recovery in **InitController** in **shardctrler/shardctrler.go**.
+
+---
+
+## Part C: Concurrent Configuration Changes (moderate)
+
+Modify the controller to allow **concurrent controllers**. When one crashes or is partitioned, the tester starts a new one, which must finish any in-progress work (as in Part B). So several controllers may run concurrently and send RPCs to shardgrps and to the kvsrv.
+
+**Challenge:** Ensure controllers **don't step on each other**. In Part A you already fenced shardgrp RPCs with **Num** so old RPCs are rejected; duplicate work from multiple controllers is safe. The remaining issue is that **only one controller** should update the **next** configuration, so two controllers (e.g. partitioned and new) don't write different configs for the same Num. The tester runs several controllers concurrently; each reads the current config, updates it for a join/leave, then calls ChangeConfigTo—so multiple controllers may call ChangeConfigTo with **different configs with the same Num**. You can use **version numbers and versioned Puts** so that only one controller successfully posts the next config and others return without doing anything.
+
+Modify the controller so that **only one controller can post a next configuration for a given configuration Num**. Pass the concurrent tests:
+
+```bash
+$ cd ~/6.5840/src/shardkv1
+$ go test -run TestConcurrentReliable5C
+Test (5C): Concurrent ctrlers ... (reliable network)...
+ ... Passed -- time 8.2s #peers 1 #RPCs 1753 #Ops 120
+PASS
+ok 6.5840/shardkv1 8.364s
+
+$ go test -run TestAcquireLockConcurrentUnreliable5C
+Test (5C): Concurrent ctrlers ... (unreliable network)...
+ ... Passed -- time 23.8s #peers 1 #RPCs 1850 #Ops 120
+PASS
+ok 6.5840/shardkv1 24.008s
+```
+
+* See **concurCtrler** in **test.go** for how the tester runs controllers concurrently.
+
+**Recovery + new controller:** A new controller should still perform Part B recovery. If the old controller was partitioned during ChangeConfigTo, ensure the old one doesn't interfere with the new one. If all controller updates are properly fenced with Num (from Part B), you may not need extra code. Pass the **Partition** tests:
+
+```bash
+$ go test -run Partition
+Test (5C): partition controller in join... (reliable network)...
+ ... Passed -- time 7.8s #peers 1 #RPCs 876 #Ops 120
+...
+Test (5C): controllers with leased leadership ... (unreliable network)...
+ ... Passed -- time 60.5s #peers 1 #RPCs 11422 #Ops 2336
+PASS
+ok 6.5840/shardkv1 217.779s
+```
+
+Rerun all tests to ensure recent controller changes didn't break earlier parts.
+
+**Gradescope** will run Lab 3A–D, Lab 4A–C, and 5C tests. Before submitting:
+
+```bash
+$ go test ./raft1
+$ go test ./kvraft1
+$ go test ./shardkv1
+```
+
+---
+
+## Part D: Extend Your Solution
+
+In this final part you may **extend your solution** in any way you like. You must **write your own tests** for your extensions.
+
+Implement one of the ideas below or your own. Write a **paragraph in extension.md** describing your extension and upload **extension.md** to Gradescope. For harder, open-ended extensions, you may partner with another student.
+
+**Ideas (first few easier, later more open-ended):**
+
+* **(hard)** Modify shardkv to support **transactions** (several Puts and Gets atomically across shards). Implement two-phase commit and two-phase locking. Write tests.
+* **(hard)** Support **transactions in kvraft** (several Put/Get atomically). Then versioned Puts are unnecessary. See [etcd's transactions](https://etcd.io/docs/v3.4/learning/api/). Write tests.
+* **(hard)** Let the kvraft **leader serve Gets without going through rsm** (optimization at end of Section 8 of the Raft paper, including **leases**), preserving linearizability. Pass existing kvraft tests. Add a test that optimized Gets are faster (e.g. fewer RPCs) and a test that term switches are slower (new leader waits for lease expiry).
+* **(moderate)** Add a **Range** function to kvsrv (keys from low to high). Lazy: iterate the key/value map; better: data structure for range search (e.g. B-tree). Include a test that fails the lazy solution but passes the better one.
+* **(moderate)** Change kvsrv to **exactly-once** Put/Get semantics (e.g. Lab 2 dropped-messages style). Implement exactly-once in kvraft as well. You may port tests from 2024.
+* **(easy)** Change the tester to use **kvraft** instead of kvsrv for the controller (e.g. replace kvsrv.StartKVServer in MakeTestMaxRaft in test.go with kvraft.StartKVServer). Write a test that the controller can query/update configuration while one kvraft peer is down. Tester code lives in **src/kvtest1**, **src/shardkv1**, **src/tester1**.
+
+---
+
+## Handin Procedure
+
+Before submitting, run all tests one final time:
+
+```bash
+$ go test ./raft1
+$ go test ./kvraft1
+$ go test ./shardkv1
+```
+
+---
+*From: [6.5840 Lab 5: Sharded Key/Value Service](https://pdos.csail.mit.edu/6.824/labs/lab-shard1.html)*
diff --git a/docs/papers/linearizability-faq-cn.txt b/docs/papers/linearizability-faq-cn.txt
new file mode 100644
index 0000000..c96258b
--- /dev/null
+++ b/docs/papers/linearizability-faq-cn.txt
@@ -0,0 +1,162 @@
+Q: Linearizability 解决什么问题?
+
+A: 要解决的是对一致性模型的需求:即在面对多客户端并发请求、请求丢失与重传、通信延迟、服务器复制、服务器故障与恢复、以及服务器分片时,对网络服务在客户端可见行为上的正确性定义。一致性模型帮助程序员设计应用(客户端),使其表现出预期行为,也帮助服务设计者判断具体设计决策是否合适。
+
+下面是一个 linearizability 能帮助回答的问题示例。假设有一个复制存储服务(如 GFS)。客户端 C1 对某 key 发送一次 write RPC 并收到 "success" 回复;之后客户端 C2 对同一 key 发送 read RPC 并收到一个值;没有其他客户端修改该 key;C2 是否保证能看到 C1 的写入?该问题的答案对存储服务设计很重要,因为它影响副本是否能服务读、服务器崩溃时更新是否必须保留、缓存是否必须严格保持最新等。
+
+Linearizability 的答案是:是的,C2 必须看到 C1 的写入。因此,linearizable 的存储系统往往涉及复杂且昂贵的复制、崩溃恢复、缓存等管理。
+
+Q: Linearizability 的定义是什么?
+
+A: Linearizability 建立在“历史”(histories)上:即客户端操作的轨迹,并标注每个客户端操作开始(被客户端发起)的时间以及客户端认为该操作完成的时间。Linearizability 告诉你某条历史是否合法。若某服务能产生的每条历史都是 linearizable 的,我们就说该服务是 linearizable 的。
+
+历史中有一个事件表示客户端开始某操作,另一个事件表示客户端认为该操作已完成。因此历史把客户端之间的并发和网络延迟显式化。通常开始和结束事件对应与服务器交换的请求和响应消息。
+
+若你能为每个操作指定一个“线性化点”(linearization point)(一个时间),使得每个操作的点都落在其开始与结束事件之间,且历史的响应值与按这些点的顺序一次执行一个操作得到的结果相同,则该历史是 linearizable 的。若不存在满足这两条要求的线性化点分配,则该历史不是 linearizable 的。
+
+Q: 为什么 linearizability 是理想的一致性模型?
+
+A: 因为它相对“强”,即禁止许多可能给应用程序员带来问题的“异常”行为。一致性保证越强的服务,越容易让程序员据此设计。
+
+例如,假设应用的一部分计算出一个值、写入存储系统,然后在存储系统中设置一个标志表示计算好的值已就绪:
+
+ v = compute...
+ put("value", v)
+ put("done", true)
+
+在另一台机器上,程序检查 "done" 以判断值是否可用,若可用则使用:
+
+ if get("done") == true:
+ v = get("value")
+ print v
+
+若实现 put() 和 get() 的存储系统是 linearizable 的,上述程序会按预期工作。
+
+在许多较弱的一致性模型下,上述程序不会如人所愿。例如,提供“最终一致性”(eventual consistency)的存储系统可能重排两次 put(导致 "done" 为 true 而 "value" 尚不可用),或对某次 get() 返回陈旧(旧)值。
+
+Q: 在试图证明某条历史是 linearizable 时,如何决定每个操作的线性化点放在哪里?
+
+A: 思路是:为了说明某次执行是 linearizable 的,你(人)需要找到放置那些小橙线(线性化点)的位置。也就是说,要说明一条历史是 linearizable 的,需要找到一组线性化点(进而一个操作顺序)的分配,使其满足以下要求:
+
+ * 所有函数调用在从调用到响应之间的某个时刻都有一个线性化点。
+
+ * 所有函数在其线性化点处看起来是瞬时发生的,行为符合顺序定义。
+
+因此,有些线性化点的放置是无效的,因为它们落在请求时间范围之外;另一些无效是因为违反了顺序定义(对 key/value 存储而言,违反即某次读没有观察到最近一次写入的值,其中“最近”指线性化点顺序)。
+
+对复杂历史可能需尝试多种线性化点分配才能找到一种证明该历史是 linearizable 的。若全部尝试后仍无一种成立,则该历史不是 linearizable 的。
+
+Q: 为什么不以客户端发送命令的时间作为线性化点?即让系统按客户端发送的顺序执行操作?
+
+A: 很难构建保证这种行为的系统——开始时间是客户端代码发出请求的时间,但服务可能因网络延迟很久后才收到请求。也就是说,请求到达服务的顺序可能与开始时间的顺序大不相同。服务原则上可以延迟执行每个到达的请求,以防更早发出的请求稍后到达,但网络延迟无界,很难知道等待多久。而且这会增加每个请求的延迟,可能很多。话虽如此,我们后面会看的 Spanner 使用了相关技术。
+
+像 linearizability 这样的正确性规范需要在“足够宽松以便高效实现”和“足够严格以便为应用程序提供有用保证”之间取得平衡。“看起来按调用顺序执行操作”过于严格难以高效实现,而 linearizability 的“看起来在调用与响应之间的某个时刻执行”是可实现的,尽管对应用程序员不如前者直观。
+
+Q: 服务如何实现 linearizability?
+
+A: 若服务以单台服务器实现,且无复制、无缓存、无内部并行,则服务按请求到达顺序一次执行一个客户端请求就几乎足够。一个复杂之处来自因认为网络丢包而重发请求的客户端:对有副作用的请求,服务必须确保每个客户端请求只执行一次。复制、容错和缓存会带来更多设计复杂度。
+
+Linearizability 的一个好处是:服务在并发(时间上重叠)操作的执行顺序上有自由度。具体而言,若客户端 C1 和 C2 的操作并发,服务器可以先执行 C2 的操作即使 C1 先于 C2 开始。反之,若 C1 在 C2 开始前就结束了,linearizability 要求服务表现得像先执行了 C1 再执行 C2(即 C2 的操作必须观察到 C1 操作的效果,若有)。
+
+Q: 还有哪些一致性模型?
+
+A: 可查阅
+
+ eventual consistency
+ causal consistency
+ fork consistency
+ serializability
+ sequential consistency
+ timeline consistency
+
+数据库、CPU 内存/缓存系统和文件系统等领域还有其它模型。
+
+一般而言,不同模型在“对应用程序员是否直观”和“能获得多少性能”上不同。例如,eventual consistency 允许很多异常结果(例如即使写已完成,后续读也可能看不到),但在分布式/复制场景下可以实现比 linearizability 更高的性能。
+
+Q: 为何用 linearizability 作为一致性模型,而不是其他如 eventual consistency?
+
+A: 人们确实常构建提供比 linearizability 更弱一致性的存储系统,例如 eventual 和 causal consistency。
+
+Linearizability 对应用编写者有一些好处:
+
+ * 读总是能观察到最新数据。
+ * 若无并发写,所有读者看到相同数据。
+ * 在多数 linearizable 系统上可以加入类似 test-and-set 的小事务(因为多数 linearizable 设计最终会对每个数据项一次执行一个操作)。
+
+像 eventual 和 causal consistency 这样的较弱方案能获得更高性能,因为它们不要求所有数据副本立即更新。这种更高性能往往是决定因素。对某些应用弱一致性没有问题,例如只存从不更新的数据(如图片或视频)。
+
+但弱一致性会给应用编写者带来一些复杂度:
+
+ * 读可能观察到过时(stale)数据。
+ * 读可能观察到乱序的写。
+ * 若你先写再读,可能看不到自己的写,而是看到陈旧数据。
+ * 对同一项的并发更新不是一次执行一个,因此难以实现 test-and-set 或原子自增之类的小事务。
+
+Q: Linearizability 似乎并不特别“强”,因为即使同时执行两条命令也可能读到不同数据;有没有更强的概念?
+
+A: 确实,linearizability 让人联想到在程序里用线程却不用锁。这样也能正确编程,但需要小心。
+
+更强的一致性概念之一是事务(transactions),见于很多数据库,会 effectively 锁住所用数据。对读写多个数据项的程序,事务比 linearizability 更易编程。“Serializability”是提供事务的一种一致性模型的名称。
+
+但事务系统比 linearizable 系统明显更复杂、更慢、更难做容错。
+
+Q: 若存在并发 put(),并发 get() 可能看到不同值,这是否有问题?
+
+A: 在存储系统语境下通常没问题。例如,若我们讨论的是我的头像照片,而两个人在我更新照片的同时请求查看,他们看到不同照片(旧或新)是合理的。
+
+另一种看法是:这与程序员在多核计算机上已熟悉的行为相同:对正在被写入的内存位置,来自不同核的并发 load 不保证都看到同一值。
+
+Q: 现实中有哪些 linearizable 存储系统的例子?以及弱一致性保证的存储系统?
+
+A: Google 的 Spanner 和 Amazon 的 S3 是提供 linearizability 的存储系统。
+
+Google 的 GFS、Amazon 的 Dynamo 和 Cassandra 提供较弱一致性;它们大概最好归为 eventually consistent。
+
+Q: 人们如何确保分布式系统正确?
+
+A: 常用做法是充分测试,例如使用 Porcupine 等 linearizability checker。
+
+形式化方法也很常见;可参考以下示例:
+
+https://arxiv.org/pdf/2210.13661.pdf
+
+https://assets.amazon.science/67/f9/92733d574c11ba1a11bd08bfb8ae/how-amazon-web-services-uses-formal-methods.pdf
+
+https://dl.acm.org/doi/abs/10.1145/3477132.3483540
+
+https://www.ccs.neu.edu/~stavros/papers/2022-cpp-published.pdf
+
+https://www.cs.purdue.edu/homes/pfonseca/papers/eurosys2017-dsbugs.pdf
+
+https://www.andrew.cmu.edu/user/bparno/papers/ironfleet.pdf
+
+Q: 形式化证明一个服务正确有多难?
+
+A: 对复杂程序证明重要定理很难——比普通编程难得多。
+
+可以通过本课程的实验体会一下:
+
+ https://6826.csail.mit.edu/2020/
+
+Q: 团队如何判断产品已经测试得足够充分可以交付给客户?
+
+A: 在公司把钱花光破产之前开始交付产品并获取收入是明智的。人们会在此之前尽可能多测试,并通常尝试说服少数早期客户使用产品(并帮助暴露 bug),同时接受可能不正确的风险。当产品功能足够满足多数客户且没有已知重大 bug 时,或许就可以交付了。
+
+除此之外,明智的客户也会对自己依赖的软件做测试。没有严肃的组织会指望任何软件完全没有 bug。
+
+Q: Linearizability checker 如何工作?
+
+A: 简单的 linearizability checker 会尝试所有可能的顺序(或线性化点的选择),看是否存在符合 linearizability 定义规则的合法顺序。因为这对大历史会太慢,聪明的 checker 会避免检查显然不可能的顺序(例如若提议的线性化点在操作开始时间之前)、在可能时将历史分解为可分别检查的子历史、并用启发式优先尝试更可能的顺序。
+
+以下论文描述了相关技术;据我所知 Knossos 基于第一篇,Porcupine 加入了第二篇的思路:
+
+ http://www.cs.ox.ac.uk/people/gavin.lowe/LinearizabiltyTesting/paper.pdf
+ https://arxiv.org/pdf/1504.00204.pdf
+
+Q: 有没有用 Porcupine 或类似测试框架测试过的真实系统例子?
+
+A: 这类测试很常见——例如可参见 https://jepsen.io/analyses;Jepsen 是测试过多种存储系统正确性(以及在适用时的 linearizability)的机构。
+
+针对 Porcupine,例如:
+
+ https://www.vldb.org/pvldb/vol15/p2201-zare.pdf
diff --git a/docs/papers/linearizability-faq.txt b/docs/papers/linearizability-faq.txt
new file mode 100644
index 0000000..7a4d9db
--- /dev/null
+++ b/docs/papers/linearizability-faq.txt
@@ -0,0 +1,162 @@
+Q: What problem does linearizability solve?
+
+A: The problem being solved is fulfilling the need for a consistency model: a definition of correct client-visible behavior of a network service in the face of concurrent requests from multiple clients, lost and re-transmitted requests, communication delays, server replication, server failure and recovery, and server sharding. A consistency model helps programmers design applications (clients) so that they provide the behavior the programmers intend. And it helps service designers decide whether specific design decisions are OK or not.
+
+Here's an example of the kind of question linearizability can help answer. Suppose we have a replicated storage service (like GFS). Client C1 sends a write RPC for a certain key and receives a "success" reply; after that, client C2 sends a read RPC for the same key and receives a value back; no other clients modify that key; is C2 guaranteed to see C1's write? The answer to this question is important for the design of the storage service, since it affects whether replicas can serve reads, whether updates must be preserved if servers crash, whether caches must be kept strictly up to date, &c.
+
+Linearizability's answer is yes, C2 must see C1's write. And as a result, a linearizable storage system often involves complex and expensive management of replication, crash recovery, caching, &c.
+
+Q: What's the definition of linearizability?
+
+A: Linearizability is defined on "histories": traces of client operations, annotated by the time at which each client operation starts (is launched by a client), and the time at which the client sees that the operation has finished. Linearizability tells you if an individual history is legal. We say that a service is linearizable if every history it can generate is linearizable.
+
+There is one event in the history for a client starting an operation, and another for the client deciding the operation has finished. Thus the history makes concurrency among clients, and network delays, explicit. Typically the start and finish events correspond to a request and a response message exchanged with the server.
+
+A history is linearizable if you can assign a "linearization point" (a time) to each operation, where each operation's point lies between the times of its start and finish events, and the history's response values are the same as you'd get if you executed the operations one at a time in point order. If no assignment of linearization points satisfies these two requirements, the history is not linearizable.
+
+Q: Why is linearizability a desirable consistency model?
+
+A: Because it is relatively strong, in the sense of forbidding many "anomalous" behaviours that might cause problems for application programmers. Services with stronger consistency guarantees tend to be easier for programmers to design for than weaker ones.
+
+For example, suppose one part of an application computes a value, writes it to the storage system, and then sets a flag in the storage system indicating that the computed value is ready:
+
+ v = compute...
+ put("value", v)
+ put("done", true)
+
+On a different computer a program checks "done" to see if the value is available, and uses it if it is:
+
+ if get("done") == true:
+ v = get("value")
+ print v
+
+If the storage system that implements put() and get() is linearizable, the above programs will work as expected.
+
+With many weaker consistency models, the above programs will not work as one might hope. For example, a storage system providing "eventual consistency" might re-order the two puts (so that "done" is true even though "value" is not available), or might yield a stale (old) value for either of the get()s.
+
+Q: When trying to demonstrate that a history is linearizable, how does one decide where to place the linearization point for each operation?
+
+A: The idea is that, in order to show that an execution is linearizable, you (the human) need to find places to put the little orange lines (linearization points). That is, in order to show that a history is linearizable, you need to find an assignment of linearization points (and thus an order of operations) that conforms to these requirements:
+
+ * All function calls have a linearization point at some instant between their invocation and their response.
+
+ * All functions appear to occur instantly at their linearization point, behaving as specified by the sequential definition.
+
+So, some placements of linearization points are invalid because they lie outside of the time span of a request; others are invalid because they violate the sequential definition (for a key/value store, a violation means that a read does not observe the most recently written value, where "recent" refers to linearization points).
+
+For a complex history you may need to try many assignments of linearization points in order to find one that demonstrates that the history is linearizable. If you try them all, and none works, then the history is not linearizable.
+
+Q: Why not use the time at which the client sent the command as the linearization point? I.e. have the system execute operations in the order that clients sent them?
+
+A: It's hard to build a system that guarantees that behavior -- the start time is the time at which the client code issued the request, but the service might not receive the request until much later due to network delays. That is, requests may arrive at the service in an order that's quite different from the order of start times. The service could in principle delay execution of every arriving request in case a request with an earlier issue time arrives later, but it's hard to know how long to wait since networks can impose unbounded delays. And it would increase delays for every request, perhaps by a lot. That said, Spanner, which we'll look at later, uses a related technique.
+
+A correctness specification like linearizability needs to walk a fine line between being lax enough to implement efficiently, but strict enough to provide useful guarantees to application programs. "Appears to execute operations in invocation order" is too strict to implement efficiently, whereas linearizability's "appears to execute somewhere between invocation and response" is implementable though not as straightforward for application programmers.
+
+Q: How do services implement linearizability?
+
+A: If the service is implemented as a single server, with no replication or caching or internal parallelism, it's nearly enough for the service to execute client requests one a time as they arrive. One complication comes from clients that re-send requests because they think the network has lost messages: for requests with side-effects, the service must take care to execute any given client request only once. Replication, fault tolerance, and caching involve further design complexity.
+
+An nice consequence of linearizability is that the service has freedom in the order in which it executes concurrent (overlapping-in-time) operations. In particular, if operations from client C1 and C2 are concurrent, the server could execute C2's operation first even if C1 started before C2. On the other hand, if C1 finished before C2 started, linearizability requires the service to act as if it executed C1's operation before C2's (i.e. C2's operation is required to observe the effects of C1's operation, if any).
+
+Q: What are other consistency models?
+
+A: Look for
+
+ eventual consistency
+ causal consistency
+ fork consistency
+ serializability
+ sequential consistency
+ timeline consistency
+
+And there are others from the worlds of databases, CPU memory/cache systems, and file systems.
+
+In general, different models differ in how intuitive they are for application programmers, and how much performance you can get with them. For example, eventual consistency allows many anomalous results (e.g. even if a write has completed, subsequent reads might not see it), but in a distributed/replicated setting can be implemented with higher performance than linearizability.
+
+Q: Why is linearizability used as a consistency model versus other ones, such as eventual consistency?
+
+A: People do often build storage systems that provide consistency weaker than linearizability, such as eventual and causal consistency.
+
+Linearizability has some nice properties for application writers:
+
+ * reads always observe fresh data.
+ * if there are no concurrent writes, all readers see the same data.
+ * on most linearizable systems you can add mini-transactions like test-and-set (because most linearizable designs end up executing operations on each data item one-at-a-time).
+
+Weaker schemes like eventual and causal consistency can allow higher performance, since they don't require all copies of data to be updated right away. This higher performance is often the deciding factor. For some applications weak consistency causes no problems, for example if one is storing data items that are never updated, such as images or video.
+
+However, weak consistency introduces some complexity for application writers:
+
+ * reads can observe out-of-date (stale) data.
+ * reads can observe writes out of order.
+ * if you write, and then read, you may not see your write, but instead see stale data.
+ * concurrent updates to the same items aren't executed one-at-a-time, so it's hard to to implement mini-transactions like test-and-set or atomic increment.
+
+Q: Linearizability doesn't seem particularly "strong", since you can be reading different data even when you execute two commands at the same time; are there stronger notions?
+
+A: True, linearizability is reminiscent of using threads in a program without using locks. It's possible to program correctly this way but it requires care.
+
+An example of a stronger notion of consistency is transactions, as found in many databases, which effectively lock any data used. For programs that read and write multiple data items, transactions make programming easier than linearizability. "Serializability" is the name of one consistency model that provides transactions.
+
+However, transaction systems are significantly more complex, slower, and harder to make fault-tolerant than linearizable systems.
+
+Q: Is it a problem that concurrent get()s might see different values if there's also a concurrent put()?
+
+A: It's often not a problem in the context of storage systems. For example, if the value we're talking about is my profile photograph, and two different people ask to see it at the same time that I'm updating the photo, then it's reasonable for them to see different photos (either the old or new one).
+
+Another way of looking at this is that it's the same behavior that programmers already are familiar with on multi-core computers: concurrent loads from different cores of a memory location that's simultaneously being written are not guaranteed to all see the same value.
+
+Q: What are some examples of real-world linearizable storage systems? And of storage systems with weaker consistency guarantees?
+
+A: Google's Spanner and Amazon's S3 are storage systems that provide linearizability.
+
+Google's GFS, Amazon's Dynamo, and Cassandra provide weaker consistency; they are probably best classified as eventually consistent.
+
+Q: What do people do to ensure their distributed systems are correct?
+
+A: Thorough testing is a common plan, perhaps using a linearizability checker such as Porcupine.
+
+Use of formal methods is also common; have a look here for some examples:
+
+https://arxiv.org/pdf/2210.13661.pdf
+
+https://assets.amazon.science/67/f9/92733d574c11ba1a11bd08bfb8ae/how-amazon-web-services-uses-formal-methods.pdf
+
+https://dl.acm.org/doi/abs/10.1145/3477132.3483540
+
+https://www.ccs.neu.edu/~stavros/papers/2022-cpp-published.pdf
+
+https://www.cs.purdue.edu/homes/pfonseca/papers/eurosys2017-dsbugs.pdf
+
+https://www.andrew.cmu.edu/user/bparno/papers/ironfleet.pdf
+
+Q: How hard is it to formally prove a service to be correct?
+
+A: It turns out that proving significant theorems about complex programs is difficult -- much more difficult than ordinary programming.
+
+You can get a feel for this by trying the labs for this course:
+
+ https://6826.csail.mit.edu/2020/
+
+Q: How does a team decide that they have tested a product thoroughly enough to ship to customers?
+
+A: It's a good idea to start shipping product, and getting revenue, before your company runs out of money and goes bankrupt. People test as much as they can before that point, and usually try to persuade a few early customers to use the product (and help reveal bugs) with the understanding that it might not work correctly. Maybe you are ready to ship when the product is functional enough to satisfy many customers and has no known major bugs.
+
+Independent of this, a wise customer will also test software that they depend on. No serious organization expects any software to be bug-free.
+
+Q: How do linearizability checkers work?
+
+A: A simple linearizability checker would try every possible order (or choice of linearization points) to see if one is valid according to the rules in the definition of linearizability. Because that would be too slow on big histories, clever checkers avoid looking at clearly impossible orders (e.g. if a proposed linearization point is before the operation's start time), decompose the history into sub-histories that can be checked separately when that's possible, and use heuristics to try more likely orders first.
+
+These papers describe the techniques; I believe Knossos is based on the first paper, and Porcupine adds ideas from the second paper:
+
+ http://www.cs.ox.ac.uk/people/gavin.lowe/LinearizabiltyTesting/paper.pdf
+ https://arxiv.org/pdf/1504.00204.pdf
+
+Q: Are there examples of real-world systems tested with Porcupine or similar testing frameworks?
+
+A: Such testing is common -- for example, have a look at https://jepsen.io/analyses; Jepsen is an organization that has tested the correctness (and linearizability, where appropriate) of many storage systems.
+
+For Porcupine specifically, here's an example:
+
+ https://www.vldb.org/pvldb/vol15/p2201-zare.pdf
diff --git a/docs/papers/mapreduce-cn.md b/docs/papers/mapreduce-cn.md
new file mode 100644
index 0000000..885ee2a
--- /dev/null
+++ b/docs/papers/mapreduce-cn.md
@@ -0,0 +1,453 @@
+# MapReduce:大规模集群上的简化数据处理
+
+**Jeffrey Dean and Sanjay Ghemawat** jeff@google.com, sanjay@google.com
+Google, Inc.
+
+*OSDI '04: 6th Symposium on Operating Systems Design and Implementation — USENIX Association*
+
+---
+
+## 摘要
+
+MapReduce 是一种用于处理与生成大规模数据集的编程模型及其相关实现。用户指定一个 map 函数,用于处理 key/value 对并生成一组中间 key/value 对;以及一个 reduce 函数,用于合并与同一中间 key 关联的所有中间 value。如本文所示,许多现实任务都可以用该模型表达。
+
+以这种函数式风格编写的程序会被自动并行化,并在由大量商用机构成的大规模集群上执行。运行时系统负责:对输入数据分区、在多台机器上调度程序执行、处理机器故障以及管理所需的机器间通信。这样,没有并行与分布式系统经验的程序员也能轻松利用大规模分布式系统的资源。
+
+我们的 MapReduce 实现运行在由大量商用机构成的大规模集群上,并具有很好的可扩展性:典型的 MapReduce 计算会在数千台机器上处理数 TB 级数据。程序员认为该系统易于使用:已有数百个 MapReduce 程序被实现,每天在 Google 的集群上执行的 MapReduce 作业超过一千个。
+
+---
+
+## 1 引言
+
+在过去五年中,本文作者与 Google 的许多其他人实现了数百种专用计算,用于处理大量原始数据(如爬取的文档、Web 请求日志等),并生成各类派生数据(如倒排 index、Web 文档图结构的多种表示、按 host 爬取页面数汇总、某日最常见查询集合等)。这类计算在概念上大多很直接,但输入数据通常很大,计算不得不分布在数百或数千台机器上才能在合理时间内完成。如何并行化计算、如何分布数据、如何应对故障等问题交织在一起,用大量处理这些问题的复杂代码掩盖了原本简单的计算逻辑。
+
+针对这种复杂性,我们设计了一种新的抽象:既能表达我们想要执行的简单计算,又把并行化、容错、数据分布与负载均衡等繁琐细节隐藏在库中。该抽象受到 Lisp 及许多其他函数式语言中 map 与 reduce 原语的启发。我们意识到,我们的大多数计算都对输入中的每条逻辑「record」施加一次 map 操作,得到一组中间 key/value 对,再对共享同一 key 的所有 value 施加一次 reduce 操作,以恰当方式合并派生数据。采用由用户指定 map 与 reduce 操作的函数式模型,使我们能轻松并行化大规模计算,并以重新执行作为容错的主要机制。
+
+本工作的主要贡献是:一个简单而强大的接口,能够自动并行化与分布大规模计算;以及该接口的一种实现,在由大量商用 PC 构成的大规模集群上达到高性能。
+
+- 第 2 节描述基本编程模型并给出若干示例。
+- 第 3 节描述针对我们基于集群的计算环境定制的 MapReduce 接口实现。
+- 第 4 节描述我们觉得有用的若干编程模型改进。
+- 第 5 节给出我们在多种任务上的性能测量结果。
+- 第 6 节探讨 MapReduce 在 Google 内的使用,包括以其为基础重写生产 index 系统的经验。
+- 第 7 节讨论相关工作与未来工作。
+
+---
+
+## 2 编程模型
+
+计算以一组输入 key/value 对为输入,产生一组输出 key/value 对。MapReduce 库的用户将计算表示为两个函数:**Map** 和 **Reduce**。
+
+由用户编写的 **Map** 接受一个输入对,产生一组中间 key/value 对。MapReduce 库把所有与同一中间 key *I* 关联的中间 value 归为一组,并将它们传给 Reduce 函数。
+
+同样由用户编写的 **Reduce** 函数接受一个中间 key *I* 以及该 key 的一组 value。它将这组 value 合并成可能更小的一组 value。通常每次 Reduce 调用只产生零个或一个输出 value。中间 value 通过 iterator 提供给用户的 reduce 函数,从而可以处理因过大而无法放入内存的 value 列表。
+
+### 2.1 示例
+
+考虑在大规模文档集合中统计每个词出现次数的问题。用户会编写与下面伪代码类似的代码:
+
+```java
+map(String key, String value):
+ // key: document name
+ // value: document contents
+ for each word w in value:
+ EmitIntermediate(w, "1");
+
+reduce(String key, Iterator values):
+ // key: a word
+ // values: a list of counts
+ int result = 0;
+ for each v in values:
+ result += ParseInt(v);
+ Emit(AsString(result));
+```
+
+map 函数对每个词输出其出现次数(在本例中简单地为 '1')。reduce 函数将同一词的所有计数相加。
+
+此外,用户还需编写代码,在 mapreduce 的 specification 对象中填入输入、输出文件名以及可选的调优参数,然后调用 MapReduce 函数并传入该 specification 对象。用户代码与 MapReduce 库(以 C++ 实现)链接在一起。附录 A 给出该示例的完整程序文本。
+
+### 2.2 类型
+
+尽管上述伪代码以 string 的输入输出书写,从概念上用户提供的 map 与 reduce 函数具有如下类型:
+
+- **map**: (k1, v1) → list(k2, v2)
+- **reduce**: (k2, list(v2)) → list(v2)
+
+即输入 key、value 与输出 key、value 来自不同的域,而中间 key、value 与输出 key、value 来自同一域。
+
+我们的 C++ 实现在用户定义函数之间以 string 传递数据,由用户代码负责在 string 与适当类型之间转换。
+
+### 2.3 更多示例
+
+下面是一些可以轻松表达为 MapReduce 计算的有趣程序的简单示例。
+
+| 示例 | 描述 |
+|------|------|
+| **Distributed Grep** | map 函数在行匹配给定 pattern 时输出该行;reduce 函数是恒等函数,仅将提供的中间数据复制到输出。 |
+| **Count of URL Access Frequency** | map 函数处理 Web 页面请求日志,输出 〈URL, 1〉;reduce 函数对同一 URL 的所有 value 求和,并输出 〈URL, total count〉 对。 |
+| **Reverse Web-Link Graph** | map 函数对在名为 source 的页面中发现的每个指向 target URL 的链接输出 〈target, source〉 对;reduce 函数将给定 target URL 对应的所有 source URL 拼接成列表,并输出 〈target, list(source)〉。 |
+| **Term-Vector per Host** | term vector 将文档或文档集合中出现的最重要词概括为 〈word, frequency〉 对的列表。map 函数对每份输入文档(hostname 从文档 URL 中提取)输出一个 〈hostname, term vector〉 对。reduce 函数接收给定 host 下每文档的 term vector,将它们相加、丢弃低频词,然后输出最终的 〈hostname, term vector〉 对。 |
+| **Inverted Index** | map 函数解析每份文档并输出一系列 〈word, document ID〉 对;reduce 函数接受给定词的所有对,对相应 document ID 排序并输出 〈word, list(document ID)〉。所有输出对的集合即构成简单的 inverted index。很容易扩展该计算以记录词位置。 |
+| **Distributed Sort** | map 函数从每条 record 中提取 key,并输出 〈key, record〉 对;reduce 函数原样输出所有对。该计算依赖于第 4.1 节的分区设施与第 4.2 节的顺序性质。 |
+
+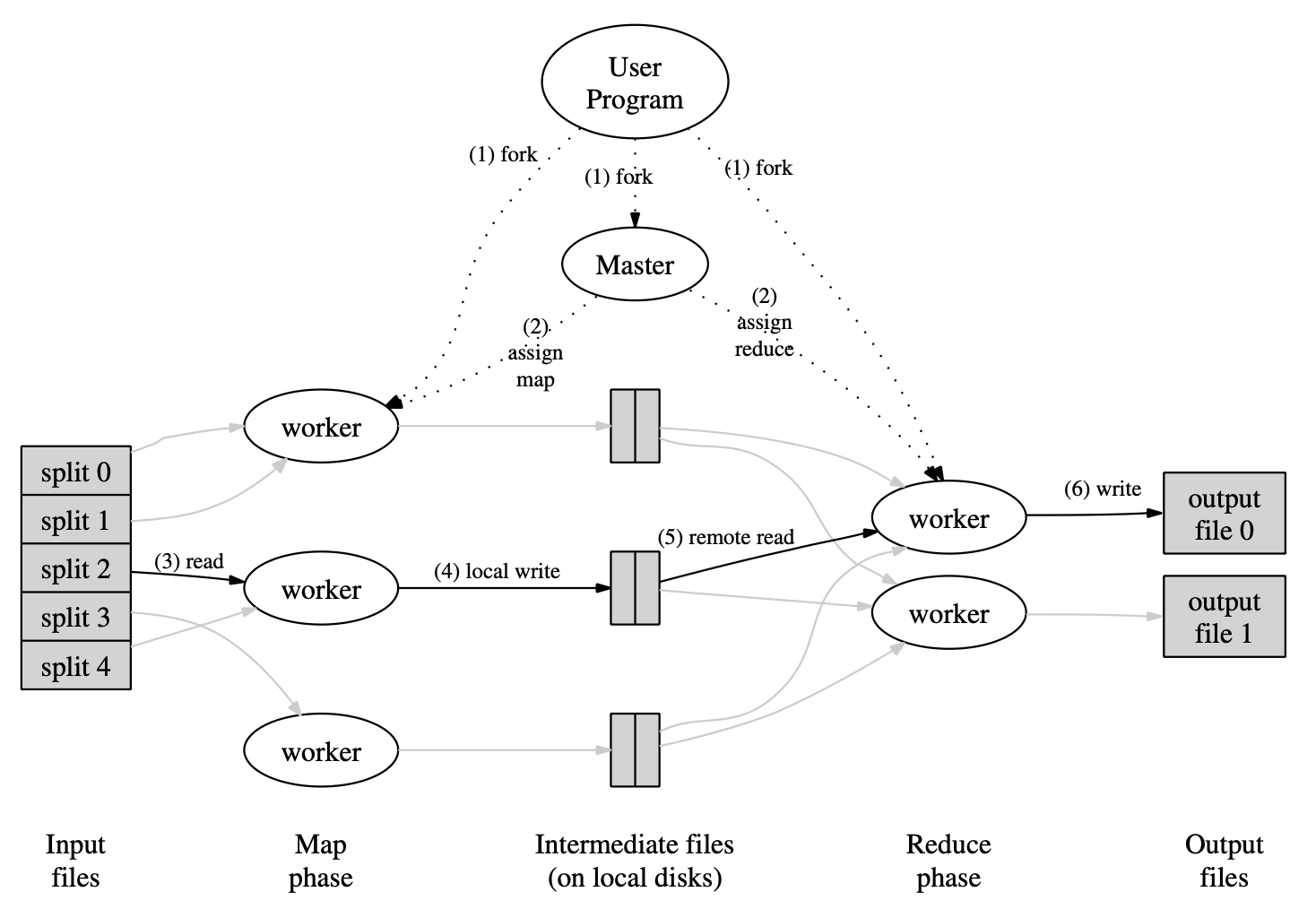
+
+**图 1:执行概览**
+
+---
+
+## 3 实现
+
+MapReduce 接口可以有多种不同实现,合适的选择取决于运行环境。例如,一种实现可能适用于小型共享内存机器,另一种适用于大型 NUMA 多处理器,再一种适用于更大规模的联网机器集群。
+
+本节描述的实现面向 Google 广泛使用的计算环境:由交换机以太网 [4] 连接的大规模商用 PC 集群。在我们的环境中:
+
+1. 机器通常是双路 x86 处理器、运行 Linux,每台机器 2–4 GB 内存。
+2. 使用商用网络硬件——机器层面通常是 100 Mb/s 或 1 Gb/s,但整体二分带宽平均要低不少。
+3. 集群由数百或数千台机器组成,因此机器故障很常见。
+4. 存储由直接挂载到单机的廉价 IDE 磁盘提供;使用内部开发的分布式文件系统 [8] 管理这些磁盘上的数据,通过复制在不可靠硬件上提供可用性与可靠性。
+5. 用户向调度系统提交作业;每个作业由一组 task 组成,由调度器映射到集群内一组可用机器。
+
+### 3.1 执行概览
+
+通过将输入数据自动划分为 *M* 个 split,Map 调用被分布到多台机器上;这些 input split 可由不同机器并行处理。Reduce 调用则通过对中间 key 空间用分区函数(如 hash(key) mod R)划分为 *R* 块来分布。分区数 R 与分区函数由用户指定。
+
+当用户程序调用 MapReduce 函数时,将发生以下动作序列(图 1 中的编号与下列序号对应):
+
+1. **划分输入**:用户程序中的 MapReduce 库先将输入文件切分为 M 块,每块通常 16 MB 到 64 MB(可由用户通过可选参数控制),然后在集群上启动程序的多个副本。
+2. **Master 与 worker**:其中一份程序副本是特殊的——即 master,其余为由 master 分配工作的 worker。共有 M 个 map task 和 R 个 reduce task 需要分配。Master 挑选空闲 worker,为每个分配一个 map task 或一个 reduce task。
+3. **Map worker**:被分配到 map task 的 worker 读取对应 input split 的内容,从输入数据中解析出 key/value 对,并把每一对传给用户定义的 Map 函数。Map 函数产生的中间 key/value 对先缓存在内存中。
+4. **定期刷写**:缓存的配对会定期写入本地磁盘,并依分区函数划分为 R 个区域。这些缓存在本地磁盘上的位置会回传给 master,由 master 负责将这些位置转发给 reduce worker。
+5. **Reduce worker 读取**:当 reduce worker 被 master 通知这些位置后,它通过远程过程调用从 map worker 的本地磁盘读取缓冲数据。当 reduce worker 读完全部中间数据后,按中间 key 排序,使相同 key 的所有出现聚在一起。排序是必要的,因为通常多个不同 key 会映射到同一 reduce task。若中间数据量过大无法放入内存,则使用外部排序。
+6. **Reduce**:reduce worker 遍历排序后的中间数据,对遇到的每个唯一中间 key,将 key 与对应的中间 value 集合传给用户的 Reduce 函数。Reduce 函数的输出被追加到该 reduce 分区的最终输出文件中。
+7. **完成**:当所有 map task 和 reduce task 都完成后,master 唤醒用户程序;此时用户程序中的 MapReduce 调用返回到用户代码。
+
+成功完成后,mapreduce 执行的输出位于 R 个输出文件中(每个 reduce task 一个,文件名由用户指定)。通常用户不需要将这 R 个输出文件合并为一个——它们常被作为另一次 MapReduce 调用的输入,或供能处理多文件分区的其他分布式应用使用。
+
+### 3.2 Master 数据结构
+
+Master 维护若干数据结构。对每个 map task 和 reduce task,它保存其状态(idle、in-progress 或 completed)以及 worker 机器标识(对非 idle 的 task)。
+
+Master 是 map task 产生的中间文件区域位置传播到 reduce task 的通道。因此,对每个已完成的 map task,master 保存该 map task 产生的 R 个中间文件区域的位置与大小。随着 map task 完成,会收到对这些位置与大小信息的更新,并增量推送给正在进行 reduce task 的 worker。
+
+### 3.3 容错
+
+由于 MapReduce 库被设计为在数百或数千台机器上处理海量数据,库必须能妥善应对机器故障。
+
+#### Worker 故障
+
+Master 定期 ping 每个 worker。若在约定时间内未收到某 worker 的响应,master 将该 worker 标记为失败。该 worker 已完成的任何 map task 会被重置为初始 idle 状态,从而可被调度到其他 worker。同样,在该故障 worker 上正在执行的任何 map 或 reduce task 也会被重置为 idle 并可供重新调度。
+
+已完成的 map task 在故障时会重新执行,因为其输出保存在故障机器的本地磁盘上而无法访问。已完成的 reduce task 不需要重新执行,因为其输出保存在全局文件系统中。
+
+当某 map task 先由 worker A 执行、后因 A 故障又由 worker B 执行时,所有正在执行 reduce task 的 worker 会收到重新执行的通知;尚未从 worker A 读取数据的 reduce task 将从 worker B 读取数据。
+
+MapReduce 能应对大规模 worker 故障。例如,在一次 MapReduce 运行期间,对运行中集群的网络维护导致每次约 80 台机器在数分钟内不可达;MapReduce 的 master 只需重新执行这些不可达 worker 已完成的工作,并继续推进,最终完成该次 MapReduce 操作。
+
+#### Master 故障
+
+可以很容易地让 master 对上述 master 数据结构做定期 checkpoint。若 master 进程退出,可从最近一次 checkpoint 状态启动新副本。但由于只有一个 master,其故障概率较低,我们当前实现中若 master 故障则中止该次 MapReduce 计算;客户端可检测该情况并按需重试 MapReduce 操作。
+
+#### 故障下的语义
+
+当用户提供的 map 与 reduce 算子对其输入是确定性函数时,我们的分布式实现产生的输出与整个程序在无故障顺序执行下将产生的输出相同。
+
+我们依赖 map 与 reduce task 输出的原子提交来保证这一点。每个进行中的 task 将其输出写入私有临时文件:reduce task 产生一个此类文件,map task 产生 R 个(每个 reduce task 一个)。map task 完成时,worker 向 master 发送消息,其中包含这 R 个临时文件的名称。若 master 收到的是关于一个已完成 map task 的完成消息,则忽略;否则将该 R 个文件名记入 master 数据结构。
+
+reduce task 完成时,reduce worker 将其临时输出文件原子地重命名为最终输出文件。若同一 reduce task 在多台机器上执行,会对同一最终输出文件执行多次 rename;我们依赖底层文件系统提供的原子 rename 操作,保证最终文件系统状态中只包含该 reduce task 一次执行产生的数据。
+
+我们绝大多数 map 与 reduce 算子都是确定性的,此时语义与顺序执行等价,便于程序员推理程序行为。当 map 和/或 reduce 算子非确定性时,我们提供较弱但仍合理的语义(详见论文)。
+
+### 3.4 局部性
+
+在我们的计算环境中,网络带宽是相对稀缺的资源。我们利用输入数据(由 GFS [8] 管理)存储在组成集群的机器本地磁盘上这一事实来节省网络带宽。GFS 将每个文件划分为 64 MB 的 block,并在不同机器上保存每个 block 的若干副本(通常 3 份)。MapReduce 的 master 会考虑输入文件的位置信息,尽量在包含对应输入数据副本的机器上调度 map task;若做不到,则尽量在靠近该 task 输入数据副本的机器上调度(例如与存有数据的机器在同一台网络交换机上的 worker)。在集群中相当比例的 worker 上运行大型 MapReduce 操作时,大部分输入数据从本地读取,不占用网络带宽。
+
+### 3.5 任务粒度
+
+如上所述,我们将 map 阶段细分为 M 份、reduce 阶段细分为 R 份。理想情况下 M 和 R 应远大于 worker 机器数。让每个 worker 执行多种 task 有利于动态负载均衡,也能在 worker 故障时加快恢复:该 worker 已完成的众多 map task 可分散到其他所有 worker 上重新执行。
+
+在我们的实现中,M 和 R 的大小有实际限制,因为 master 需要做 O(M + R) 次调度决策并如上所述在内存中维护 O(M × R) 的状态。(但内存占用的常数因子很小:O(M × R) 部分约为每个 map task/reduce task 对一字节。)
+
+此外,R 常受用户约束,因为每个 reduce task 的输出最终进入单独的输出文件。实践中我们倾向于将 M 选为每个 task 约 16 MB 到 64 MB 输入数据(使上述局部性优化最有效),并将 R 设为预期使用的 worker 数量的较小倍数。我们常以 M = 200,000、R = 5,000、使用 2,000 台 worker 机器执行 MapReduce 计算。
+
+### 3.6 备份任务
+
+导致 MapReduce 操作总时间延长的一个常见原因是「掉队者」:某台机器完成计算中最后几个 map 或 reduce task 之一时异常缓慢。掉队者可能由多种原因造成(如坏盘、资源竞争、bug)。
+
+我们有一种通用机制来缓解掉队者问题。当 MapReduce 操作接近完成时,master 会为剩余进行中的 task 调度备份执行。只要主执行或备份执行之一完成,该 task 即标记为已完成。我们已将该机制调优为通常仅使操作使用的计算资源增加几个百分点。实践表明,这能显著缩短完成大型 MapReduce 操作的时间。例如,第 5.3 节描述的 sort 程序在关闭备份 task 机制时,完成时间要长 44%。
+
+---
+
+## 4 改进
+
+尽管仅编写 Map 和 Reduce 函数提供的基本功能对大多数需求已足够,我们发现若干扩展很有用。本节描述这些扩展。
+
+### 4.1 分区函数
+
+MapReduce 的用户指定期望的 reduce task/输出文件数量 R。数据通过基于中间 key 的分区函数分布到这些 task。我们提供默认分区函数,采用哈希(如 "hash(key) mod R"),往往得到较均衡的分区。但在某些情况下,按 key 的其它函数分区更有用。例如,使用 "hash(Hostname(urlkey)) mod R" 作为分区函数可使同一 host 的所有 URL 落入同一输出文件。
+
+### 4.2 顺序保证
+
+我们保证在给定分区内,中间 key/value 对按 key 递增顺序被处理。这一顺序保证便于按分区生成有序输出文件,在输出文件格式需要支持按 key 的高效随机访问、或输出的使用者希望数据已排序时很有用。
+
+### 4.3 Combiner 函数
+
+有时每个 map task 产生的中间 key 存在大量重复,且用户指定的 Reduce 函数可交换、可结合。我们允许用户指定可选的 **Combiner** 函数,在数据通过网络发送前对其进行部分合并。Combiner 函数在每台执行 map task 的机器上运行。通常用同一段代码同时实现 combiner 与 reduce 函数。部分合并能显著加速某类 MapReduce 操作。附录 A 包含使用 combiner 的示例。
+
+### 4.4 输入与输出类型
+
+MapReduce 库支持以多种格式读取输入(例如 "text" 模式将每行视为一个 key/value 对)。用户可通过实现简单的 reader 接口来支持新的输入类型。类似地,我们支持多种输出类型以产生不同格式的数据。
+
+### 4.5 副作用
+
+有时 MapReduce 用户希望从 map 和/或 reduce 算子产生辅助文件作为额外输出。我们依赖应用作者使这类副作用具有原子性与幂等性;通常做法是写入临时文件,在完全生成后原子地重命名该文件。
+
+### 4.6 跳过坏记录
+
+有时用户代码中的 bug 会使 Map 或 Reduce 函数在特定 record 上确定性地崩溃。我们提供一种可选执行模式:MapReduce 库检测导致确定性崩溃的 record,并跳过这些 record 以继续推进。每个 worker 进程安装 signal handler 捕获段错误与总线错误;在调用用户代码前保存参数的序列号;发生 signal 时向 master 发送「最后一息」UDP 包;当 master 对某条 record 看到超过一次失败时,会在下次重新执行时标记跳过该 record。
+
+### 4.7 本地执行
+
+为便于调试、性能剖析与小规模测试,我们实现了 MapReduce 库的另一种版本,在单机上顺序执行一次 MapReduce 操作的全部工作。用户可将计算限制在特定的 map task 上。用户使用特殊 flag 启动程序后,即可方便地使用任何调试或测试工具(如 gdb)。
+
+### 4.8 状态信息
+
+Master 运行内部 HTTP 服务并导出一组供人查看的状态页。状态页展示计算进度,如已完成与进行中的 task 数、输入/中间/输出字节数、处理速率等。页面还包含各 task 生成的标准错误与标准输出文件的链接。
+
+### 4.9 计数器
+
+MapReduce 库提供计数器功能以统计各类事件。用户代码创建具名 counter 对象,并在 Map 和/或 Reduce 函数中适当增加计数。示例:
+
+```cpp
+Counter* uppercase;
+uppercase = GetCounter("uppercase");
+map(String name, String contents):
+ for each word w in contents:
+ if (IsCapitalized(w)):
+ uppercase->Increment();
+ EmitIntermediate(w, "1");
+```
+
+各 worker 机器上的 counter 值会定期传播到 master(搭载在 ping 响应上)。Master 汇总成功完成的 map 与 reduce task 的 counter 值,在 MapReduce 操作完成时返回给用户代码。部分 counter 值由 MapReduce 库自动维护,如已处理的输入 key/value 对数量与产生的输出 key/value 对数量。
+
+---
+
+## 5 性能
+
+本节我们在大型机器集群上对两种计算测量 MapReduce 的性能:一种在约 1 TB 数据中搜索特定 pattern;另一种对约 1 TB 数据进行排序。
+
+### 5.1 集群配置
+
+所有程序在约 1800 台机器组成的集群上运行。每台机器为双路 2GHz Intel Xeon、开启 Hyper-Threading、4GB 内存、两块 160GB IDE 盘、千兆以太网。机器组成两层树形交换网络,根处聚合带宽约 100–200 Gbps。所有机器在同一托管设施内,任意两台机器间往返时延小于 1 毫秒。4GB 内存中约 1–1.5GB 被集群上其他任务占用。程序在周末下午运行,此时 CPU、磁盘与网络大多空闲。
+
+### 5.2 Grep
+
+grep 程序扫描 10^10 条 100 字节的 record,搜索一个相对罕见的三字符 pattern(该 pattern 在 92,337 条 record 中出现)。输入被切分为约 64MB 的块(M = 15000),整个输出放在一个文件中(R = 1)。
+
+
+
+**图 2:随时间的数据传输速率**
+
+### 5.3 Sort
+
+sort 程序对 10^10 条 100 字节的 record(约 1 TB 数据)排序,该程序仿照 TeraSort benchmark [10]。排序程序用户代码不足 50 行:三行 Map 函数从文本行中提取 10 字节的排序 key,并输出 key 与原始文本行作为中间 key/value 对;我们使用内置的 Identity 函数作为 Reduce 算子。输入数据切分为 64MB 块(M = 15000),排序输出划分为 4000 个文件(R = 4000)。
+
+
+
+**图 3:sort 程序不同执行随时间的数据传输速率**
+
+### 5.4 备份任务的效果
+
+关闭备份任务时,执行会出现很长的尾部,期间几乎没有任何写活动。960 秒后,除 5 个外的所有 reduce task 都已完成,但最后几个掉队者直到 300 秒后才完成。整个计算耗时 1283 秒,比启用时增加 44%。
+
+### 5.5 机器故障
+
+在一次执行中,我们在计算开始数分钟后故意终止 1746 个 worker 进程中的 200 个。Worker 的终止体现为负的输入速率,因为部分先前完成的 map 工作消失并需要重做。这部分 map 工作的重新执行相对较快。包含启动开销在内,整个计算在 933 秒内完成(相对正常执行时间仅增加约 5%)。
+
+---
+
+## 6 经验
+
+我们在 2003 年 2 月完成 MapReduce 库的第一个版本,并在 2003 年 8 月做了重要增强。此后,MapReduce 在 Google 内部被广泛应用于多个领域,包括:
+
+- 大规模机器学习问题;
+- Google News 与 Froogle 产品的聚类问题;
+- 用于生成热门查询报告的数据提取(如 Google Zeitgeist);
+- 从 Web 页面提取属性以支持新实验与产品;
+- 以及大规模图计算。
+
+
+
+**图 4:MapReduce 实例随时间变化** — 从 2003 年初的 0 增长到 2004 年 9 月末的近 900 个独立实例。
+
+| 指标 | 数值 |
+|------|------|
+| Number of jobs | 29,423 |
+| Average job completion time | 634 secs |
+| Machine days used | 79,186 days |
+| Input data read | 3,288 TB |
+| Intermediate data produced | 758 TB |
+| Output data written | 193 TB |
+| Average worker machines per job | 157 |
+| Average worker deaths per job | 1.2 |
+| Average map tasks per job | 3,351 |
+| Average reduce tasks per job | 55 |
+| Unique map implementations | 395 |
+| Unique reduce implementations | 269 |
+| Unique map/reduce combinations | 426 |
+
+**表 1:** 2004 年 8 月运行的 MapReduce 作业统计
+
+### 6.1 大规模索引
+
+我们迄今对 MapReduce 最重要的应用之一,是对生产 index 系统的完整重写——该系统生成 Google Web 搜索服务所用的数据结构。index 系统以大量文档为输入(原始内容超过 20 TB)。index 过程以五到十次 MapReduce 操作的序列运行。带来的好处包括:
+
+- index 代码更简单、更短、更易理解(例如,某一阶段从约 3800 行 C++ 在用 MapReduce 表达后降至约 700 行);
+- MapReduce 库的性能足够好,我们能把概念上无关的计算分开,便于修改 index 流程;
+- index 过程的运维简单得多,因为机器故障、慢机与网络抖动等问题大多由 MapReduce 库自动处理。
+
+---
+
+## 7 相关工作
+
+许多系统通过限制编程模型并利用这些限制自动并行化计算。基于我们在大型实际计算上的经验,MapReduce 可视为这类模型的简化与提炼。更重要的是,我们提供了可扩展到数千处理器的容错实现。
+
+- **Bulk Synchronous Programming [17]** 与 **MPI [11]**:MapReduce 利用受限的编程模型自动并行化用户程序并提供透明容错。
+- **局部性**:我们的局部性优化借鉴了 **active disks [12, 15]** 等技术,将计算推向靠近本地磁盘的位置。
+- **备份任务**:与 **Charlotte System [3]** 中的 eager scheduling 机制类似;我们通过跳过坏 record 的机制修复了部分重复失败的情况。
+- **集群管理**:在思路上与 **Condor [16]** 相似。
+- **排序**:在操作上与 **NOW-Sort [1]** 类似;MapReduce 增加了用户可定义的 Map 与 Reduce 函数。
+- **River [2]**:MapReduce 将问题划分为大量细粒度 task,并在作业末尾通过冗余执行缩短完成时间。
+- **BAD-FS [5]**、**TACC [7]**:类似地通过重新执行与感知局部性的调度实现容错。
+
+---
+
+## 8 结论
+
+MapReduce 编程模型已在 Google 被成功用于多种用途。我们将成功归因于以下几点:
+
+1. 模型易于使用,即使对没有并行与分布式系统经验的程序员也是如此;
+2. 大量问题可以方便地表达为 MapReduce 计算;
+3. 我们实现的规模可扩展到由数千台机器组成的大规模集群。
+
+我们得到的认识包括:(1) 限制编程模型便于并行化与分布计算,并使其容错;(2) 网络带宽是稀缺资源,优化应着眼于减少经网络传输的数据;(3) 冗余执行可用于减轻慢机影响并应对机器故障与数据丢失。
+
+---
+
+## 致谢
+
+Josh Levenberg 修订并扩展了用户层 MapReduce API。MapReduce 从 Google File System [8] 读取输入并写入输出。感谢 Mohit Aron、Howard Gobioff、Markus Gutschke、David Kramer、Shun-Tak Leung、Josh Redstone(GFS);Percy Liang、Olcan Sercinoglu(集群管理);以及 Mike Burrows、Wilson Hsieh、Josh Levenberg、Sharon Perl、Rob Pike、Debby Wallach、匿名 OSDI 审稿人与 shepherd Eric Brewer。
+
+---
+
+## References
+
+[1] Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, David E. Culler, Joseph M. Hellerstein, and David A. Patterson. High-performance sorting on networks of workstations. In *Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data*, Tucson, Arizona, May 1997.
+
+[2] Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David Patterson, and Kathy Yelick. Cluster I/O with River: Making the fast case common. In *Proceedings of the Sixth Workshop on Input/Output in Parallel and Distributed Systems (IOPADS '99)*, pages 10–22, Atlanta, Georgia, May 1999.
+
+[3] Arash Baratloo, Mehmet Karaul, Zvi Kedem, and Peter Wyckoff. Charlotte: Metacomputing on the web. In *Proceedings of the 9th International Conference on Parallel and Distributed Computing Systems*, 1996.
+
+[4] Luiz A. Barroso, Jeffrey Dean, and Urs Hölzle. Web search for a planet: The Google cluster architecture. *IEEE Micro*, 23(2):22–28, April 2003.
+
+[5] John Bent, Douglas Thain, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, and Miron Livny. Explicit control in a batch-aware distributed file system. In *Proceedings of the 1st USENIX Symposium on Networked Systems Design and Implementation NSDI*, March 2004.
+
+[6] Guy E. Blelloch. Scans as primitive parallel operations. *IEEE Transactions on Computers*, C-38(11), November 1989.
+
+[7] Armando Fox, Steven D. Gribble, Yatin Chawathe, Eric A. Brewer, and Paul Gauthier. Cluster-based scalable network services. In *Proceedings of the 16th ACM Symposium on Operating System Principles*, pages 78–91, Saint-Malo, France, 1997.
+
+[8] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google file system. In *19th Symposium on Operating Systems Principles*, pages 29–43, Lake George, New York, 2003.
+
+[9] S. Gorlatch. Systematic efficient parallelization of scan and other list homomorphisms. In L. Bouge, P. Fraigniaud, A. Mignotte, and Y. Robert, editors, *Euro-Par'96. Parallel Processing*, Lecture Notes in Computer Science 1124, pages 401–408. Springer-Verlag, 1996.
+
+[10] Jim Gray. Sort benchmark home page. http://research.microsoft.com/barc/SortBenchmark/.
+
+[11] William Gropp, Ewing Lusk, and Anthony Skjellum. *Using MPI: Portable Parallel Programming with the Message-Passing Interface*. MIT Press, Cambridge, MA, 1999.
+
+[12] L. Huston, R. Sukthankar, R. Wickremesinghe, M. Satyanarayanan, G. R. Ganger, E. Riedel, and A. Ailamaki. Diamond: A storage architecture for early discard in interactive search. In *Proceedings of the 2004 USENIX File and Storage Technologies FAST Conference*, April 2004.
+
+[13] Richard E. Ladner and Michael J. Fischer. Parallel prefix computation. *Journal of the ACM*, 27(4):831–838, 1980.
+
+[14] Michael O. Rabin. Efficient dispersal of information for security, load balancing and fault tolerance. *Journal of the ACM*, 36(2):335–348, 1989.
+
+[15] Erik Riedel, Christos Faloutsos, Garth A. Gibson, and David Nagle. Active disks for large-scale data processing. *IEEE Computer*, pages 68–74, June 2001.
+
+[16] Douglas Thain, Todd Tannenbaum, and Miron Livny. Distributed computing in practice: The Condor experience. *Concurrency and Computation: Practice and Experience*, 2004.
+
+[17] L. G. Valiant. A bridging model for parallel computation. *Communications of the ACM*, 33(8):103–111, 1997.
+
+[18] Jim Wyllie. Spsort: How to sort a terabyte quickly. http://almaden.ibm.com/cs/spsort.pdf.
+
+---
+
+## 附录 A:词频统计
+
+本节给出一个程序,用于统计命令行指定的一组输入文件中每个不同词的出现次数。
+
+```cpp
+#include "mapreduce/mapreduce.h"
+
+// User's map function
+class WordCounter : public Mapper {
+ public:
+ virtual void Map(const MapInput& input) {
+ const string& text = input.value();
+ const int n = text.size();
+ for (int i = 0; i < n; ) {
+ // Skip past leading whitespace
+ while ((i < n) && isspace(text[i]))
+ i++;
+ // Find word end
+ int start = i;
+ while ((i < n) && !isspace(text[i]))
+ i++;
+ if (start < i)
+ Emit(text.substr(start,i-start),"1");
+ }
+ }
+};
+REGISTER_MAPPER(WordCounter);
+
+// User's reduce function
+class Adder : public Reducer {
+ virtual void Reduce(ReduceInput* input) {
+ // Iterate over all entries with the same key and add the values
+ int64 value = 0;
+ while (!input->done()) {
+ value += StringToInt(input->value());
+ input->NextValue();
+ }
+ // Emit sum for input->key()
+ Emit(IntToString(value));
+ }
+};
+REGISTER_REDUCER(Adder);
+
+int main(int argc, char** argv) {
+ ParseCommandLineFlags(argc, argv);
+ MapReduceSpecification spec;
+ // Store list of input files into "spec"
+ for (int i = 1; i < argc; i++) {
+ MapReduceInput* input = spec.add_input();
+ input->set_format("text");
+ input->set_filepattern(argv[i]);
+ input->set_mapper_class("WordCounter");
+ }
+ // Specify the output files
+ MapReduceOutput* out = spec.output();
+ out->set_filebase("/gfs/test/freq");
+ out->set_num_tasks(100);
+ out->set_format("text");
+ out->set_reducer_class("Adder");
+ // Optional: do partial sums within map tasks to save network bandwidth
+ out->set_combiner_class("Adder");
+ // Tuning parameters
+ spec.set_machines(2000);
+ spec.set_map_megabytes(100);
+ spec.set_reduce_megabytes(100);
+ // Now run it
+ MapReduceResult result;
+ if (!MapReduce(spec, &result)) abort();
+ return 0;
+}
+```
diff --git a/docs/papers/mapreduce.md b/docs/papers/mapreduce.md
new file mode 100644
index 0000000..d969c18
--- /dev/null
+++ b/docs/papers/mapreduce.md
@@ -0,0 +1,459 @@
+# MapReduce: Simplified Data Processing on Large Clusters
+
+**Jeffrey Dean and Sanjay Ghemawat** jeff@google.com, sanjay@google.com
+Google, Inc.
+
+*OSDI '04: 6th Symposium on Operating Systems Design and Implementation — USENIX Association*
+
+---
+
+## Abstract
+
+MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key. Many real world tasks are expressible in this model, as shown in the paper.
+
+Programs written in this functional style are automatically parallelized and executed on a large cluster of commodity machines. The run-time system takes care of the details of partitioning the input data, scheduling the program's execution across a set of machines, handling machine failures, and managing the required inter-machine communication. This allows programmers without any experience with parallel and distributed systems to easily utilize the resources of a large distributed system.
+
+Our implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable: a typical MapReduce computation processes many terabytes of data on thousands of machines. Programmers find the system easy to use: hundreds of MapReduce programs have been implemented and upwards of one thousand MapReduce jobs are executed on Google's clusters every day.
+
+---
+
+## 1 Introduction
+
+Over the past five years, the authors and many others at Google have implemented hundreds of special-purpose computations that process large amounts of raw data, such as crawled documents, web request logs, etc., to compute various kinds of derived data, such as inverted indices, various representations of the graph structure of web documents, summaries of the number of pages crawled per host, the set of most frequent queries in a given day, etc. Most such computations are conceptually straightforward. However, the input data is usually large and the computations have to be distributed across hundreds or thousands of machines in order to finish in a reasonable amount of time. The issues of how to parallelize the computation, distribute the data, and handle failures conspire to obscure the original simple computation with large amounts of complex code to deal with these issues.
+
+As a reaction to this complexity, we designed a new abstraction that allows us to express the simple computations we were trying to perform but hides the messy details of parallelization, fault-tolerance, data distribution and load balancing in a library. Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages. We realized that most of our computations involved applying a map operation to each logical "record" in our input in order to compute a set of intermediate key/value pairs, and then applying a reduce operation to all the values that shared the same key, in order to combine the derived data appropriately. Our use of a functional model with user-specified map and reduce operations allows us to parallelize large computations easily and to use re-execution as the primary mechanism for fault tolerance.
+
+The major contributions of this work are a simple and powerful interface that enables automatic parallelization and distribution of large-scale computations, combined with an implementation of this interface that achieves high performance on large clusters of commodity PCs.
+
+- Section 2 describes the basic programming model and gives several examples.
+- Section 3 describes an implementation of the MapReduce interface tailored towards our cluster-based computing environment.
+- Section 4 describes several refinements of the programming model that we have found useful.
+- Section 5 has performance measurements of our implementation for a variety of tasks.
+- Section 6 explores the use of MapReduce within Google including our experiences in using it as the basis for a rewrite of our production indexing system.
+- Section 7 discusses related and future work.
+
+---
+
+## 2 Programming Model
+
+The computation takes a set of input key/value pairs, and produces a set of output key/value pairs. The user of the MapReduce library expresses the computation as two functions: **Map** and **Reduce**.
+
+**Map**, written by the user, takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key *I* and passes them to the Reduce function.
+
+The **Reduce** function, also written by the user, accepts an intermediate key *I* and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user's reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
+
+### 2.1 Example
+
+Consider the problem of counting the number of occurrences of each word in a large collection of documents. The user would write code similar to the following pseudo-code:
+
+``` java
+map(String key, String value):
+ // key: document name
+ // value: document contents
+ for each word w in value:
+ EmitIntermediate(w, "1");
+
+reduce(String key, Iterator values):
+ // key: a word
+ // values: a list of counts
+ int result = 0;
+ for each v in values:
+ result += ParseInt(v);
+ Emit(AsString(result));
+```
+
+The map function emits each word plus an associated count of occurrences (just '1' in this simple example). The reduce function sums together all counts emitted for a particular word.
+
+In addition, the user writes code to fill in a mapreduce specification object with the names of the input and output files, and optional tuning parameters. The user then invokes the MapReduce function, passing it the specification object. The user's code is linked together with the MapReduce library (implemented in C++). Appendix A contains the full program text for this example.
+
+### 2.2 Types
+
+Even though the previous pseudo-code is written in terms of string inputs and outputs, conceptually the map and reduce functions supplied by the user have associated types:
+
+- **map**: (k1, v1) → list(k2, v2)
+- **reduce**: (k2, list(v2)) → list(v2)
+
+I.e., the input keys and values are drawn from a different domain than the output keys and values. Furthermore, the intermediate keys and values are from the same domain as the output keys and values.
+
+Our C++ implementation passes strings to and from the user-defined functions and leaves it to the user code to convert between strings and appropriate types.
+
+### 2.3 More Examples
+
+Here are a few simple examples of interesting programs that can be easily expressed as MapReduce computations.
+
+| Example | Description |
+| --------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **Distributed Grep** | The map function emits a line if it matches a supplied pattern. The reduce function is an identity function that just copies the supplied intermediate data to the output. |
+| **Count of URL Access Frequency** | The map function processes logs of web page requests and outputs 〈URL, 1〉. The reduce function adds together all values for the same URL and emits a 〈URL, total count〉 pair. |
+| **Reverse Web-Link Graph** | The map function outputs 〈target, source〉 pairs for each link to a target URL found in a page named source. The reduce function concatenates the list of all source URLs associated with a given target URL and emits the pair: 〈target, list(source)〉. |
+| **Term-Vector per Host** | A term vector summarizes the most important words that occur in a document or a set of documents as a list of 〈word, frequency〉 pairs. The map function emits a 〈hostname, term vector〉 pair for each input document (where the hostname is extracted from the URL of the document). The reduce function is passed all per-document term vectors for a given host. It adds these term vectors together, throwing away infrequent terms, and then emits a final 〈hostname, term vector〉 pair. |
+| **Inverted Index** | The map function parses each document, and emits a sequence of 〈word, document ID〉 pairs. The reduce function accepts all pairs for a given word, sorts the corresponding document IDs and emits a 〈word, list(document ID)〉 pair. The set of all output pairs forms a simple inverted index. It is easy to augment this computation to keep track of word positions. |
+| **Distributed Sort** | The map function extracts the key from each record, and emits a 〈key, record〉 pair. The reduce function emits all pairs unchanged. This computation depends on the partitioning facilities described in Section 4.1 and the ordering properties described in Section 4.2. |
+
+
+
+**Figure 1: Execution overview**
+
+---
+
+## 3 Implementation
+
+Many different implementations of the MapReduce interface are possible. The right choice depends on the environment. For example, one implementation may be suitable for a small shared-memory machine, another for a large NUMA multi-processor, and yet another for an even larger collection of networked machines.
+
+This section describes an implementation targeted to the computing environment in wide use at Google: large clusters of commodity PCs connected together with switched Ethernet [4]. In our environment:
+
+1. Machines are typically dual-processor x86 processors running Linux, with 2-4 GB of memory per machine.
+2. Commodity networking hardware is used – typically either 100 megabits/second or 1 gigabit/second at the machine level, but averaging considerably less in overall bisection bandwidth.
+3. A cluster consists of hundreds or thousands of machines, and therefore machine failures are common.
+4. Storage is provided by inexpensive IDE disks attached directly to individual machines. A distributed file system [8] developed in-house is used to manage the data stored on these disks. The file system uses replication to provide availability and reliability on top of unreliable hardware.
+5. Users submit jobs to a scheduling system. Each job consists of a set of tasks, and is mapped by the scheduler to a set of available machines within a cluster.
+
+### 3.1 Execution Overview
+
+The Map invocations are distributed across multiple machines by automatically partitioning the input data into a set of *M* splits. The input splits can be processed in parallel by different machines. Reduce invocations are distributed by partitioning the intermediate key space into *R* pieces using a partitioning function (e.g., hash(key) mod R). The number of partitions (R) and the partitioning function are specified by the user.
+
+When the user program calls the MapReduce function, the following sequence of actions occurs (the numbered labels in Figure 1 correspond to the numbers below):
+
+1. **Split input**: The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (controllable by the user via an optional parameter). It then starts up many copies of the program on a cluster of machines.
+
+2. **Master and workers**: One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.
+
+3. **Map worker**: A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory.
+
+4. **Periodic flush**: Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
+
+5. **Reduce worker read**: When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.
+
+6. **Reduce**: The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user's Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
+
+7. **Completion**: When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user program returns back to the user code.
+
+After successful completion, the output of the mapreduce execution is available in the R output files (one per reduce task, with file names as specified by the user). Typically, users do not need to combine these R output files into one file – they often pass these files as input to another MapReduce call, or use them from another distributed application that is able to deal with input that is partitioned into multiple files.
+
+### 3.2 Master Data Structures
+
+The master keeps several data structures. For each map task and reduce task, it stores the state (idle, in-progress, or completed), and the identity of the worker machine (for non-idle tasks).
+
+The master is the conduit through which the location of intermediate file regions is propagated from map tasks to reduce tasks. Therefore, for each completed map task, the master stores the locations and sizes of the R intermediate file regions produced by the map task. Updates to this location and size information are received as map tasks are completed. The information is pushed incrementally to workers that have in-progress reduce tasks.
+
+### 3.3 Fault Tolerance
+
+Since the MapReduce library is designed to help process very large amounts of data using hundreds or thousands of machines, the library must tolerate machine failures gracefully.
+
+#### Worker Failure
+
+The master pings every worker periodically. If no response is received from a worker in a certain amount of time, the master marks the worker as failed. Any map tasks completed by the worker are reset back to their initial idle state, and therefore become eligible for scheduling on other workers. Similarly, any map task or reduce task in progress on a failed worker is also reset to idle and becomes eligible for rescheduling.
+
+Completed map tasks are re-executed on a failure because their output is stored on the local disk(s) of the failed machine and is therefore inaccessible. Completed reduce tasks do not need to be re-executed since their output is stored in a global file system.
+
+When a map task is executed first by worker A and then later executed by worker B (because A failed), all workers executing reduce tasks are notified of the re-execution. Any reduce task that has not already read the data from worker A will read the data from worker B.
+
+MapReduce is resilient to large-scale worker failures. For example, during one MapReduce operation, network maintenance on a running cluster was causing groups of 80 machines at a time to become unreachable for several minutes. The MapReduce master simply re-executed the work done by the unreachable worker machines, and continued to make forward progress, eventually completing the MapReduce operation.
+
+#### Master Failure
+
+It is easy to make the master write periodic checkpoints of the master data structures described above. If the master task dies, a new copy can be started from the last checkpointed state. However, given that there is only a single master, its failure is unlikely; therefore our current implementation aborts the MapReduce computation if the master fails. Clients can check for this condition and retry the MapReduce operation if they desire.
+
+#### Semantics in the Presence of Failures
+
+When the user-supplied map and reduce operators are deterministic functions of their input values, our distributed implementation produces the same output as would have been produced by a non-faulting sequential execution of the entire program.
+
+We rely on atomic commits of map and reduce task outputs to achieve this property. Each in-progress task writes its output to private temporary files. A reduce task produces one such file, and a map task produces R such files (one per reduce task). When a map task completes, the worker sends a message to the master and includes the names of the R temporary files in the message. If the master receives a completion message for an already completed map task, it ignores the message. Otherwise, it records the names of R files in a master data structure.
+
+When a reduce task completes, the reduce worker atomically renames its temporary output file to the final output file. If the same reduce task is executed on multiple machines, multiple rename calls will be executed for the same final output file. We rely on the atomic rename operation provided by the underlying file system to guarantee that the final file system state contains just the data produced by one execution of the reduce task.
+
+The vast majority of our map and reduce operators are deterministic, and the fact that our semantics are equivalent to a sequential execution in this case makes it very easy for programmers to reason about their program's behavior. When the map and/or reduce operators are non-deterministic, we provide weaker but still reasonable semantics (see paper for details).
+
+### 3.4 Locality
+
+Network bandwidth is a relatively scarce resource in our computing environment. We conserve network bandwidth by taking advantage of the fact that the input data (managed by GFS [8]) is stored on the local disks of the machines that make up our cluster. GFS divides each file into 64 MB blocks, and stores several copies of each block (typically 3 copies) on different machines. The MapReduce master takes the location information of the input files into account and attempts to schedule a map task on a machine that contains a replica of the corresponding input data. Failing that, it attempts to schedule a map task near a replica of that task's input data (e.g., on a worker machine that is on the same network switch as the machine containing the data). When running large MapReduce operations on a significant fraction of the workers in a cluster, most input data is read locally and consumes no network bandwidth.
+
+### 3.5 Task Granularity
+
+We subdivide the map phase into M pieces and the reduce phase into R pieces, as described above. Ideally, M and R should be much larger than the number of worker machines. Having each worker perform many different tasks improves dynamic load balancing, and also speeds up recovery when a worker fails: the many map tasks it has completed can be spread out across all the other worker machines.
+
+There are practical bounds on how large M and R can be in our implementation, since the master must make O(M + R) scheduling decisions and keeps O(M × R) state in memory as described above. (The constant factors for memory usage are small however: the O(M × R) piece of the state consists of approximately one byte of data per map task/reduce task pair.)
+
+Furthermore, R is often constrained by users because the output of each reduce task ends up in a separate output file. In practice, we tend to choose M so that each individual task is roughly 16 MB to 64 MB of input data (so that the locality optimization described above is most effective), and we make R a small multiple of the number of worker machines we expect to use. We often perform MapReduce computations with M = 200,000 and R = 5,000, using 2,000 worker machines.
+
+### 3.6 Backup Tasks
+
+One of the common causes that lengthens the total time taken for a MapReduce operation is a "straggler": a machine that takes an unusually long time to complete one of the last few map or reduce tasks in the computation. Stragglers can arise for a whole host of reasons (e.g., bad disk, competition for resources, bugs).
+
+We have a general mechanism to alleviate the problem of stragglers. When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks. The task is marked as completed whenever either the primary or the backup execution completes. We have tuned this mechanism so that it typically increases the computational resources used by the operation by no more than a few percent. We have found that this significantly reduces the time to complete large MapReduce operations. As an example, the sort program described in Section 5.3 takes 44% longer to complete when the backup task mechanism is disabled.
+
+---
+
+## 4 Refinements
+
+Although the basic functionality provided by simply writing Map and Reduce functions is sufficient for most needs, we have found a few extensions useful. These are described in this section.
+
+### 4.1 Partitioning Function
+
+The users of MapReduce specify the number of reduce tasks/output files that they desire (R). Data gets partitioned across these tasks using a partitioning function on the intermediate key. A default partitioning function is provided that uses hashing (e.g. "hash(key) mod R"). This tends to result in fairly well-balanced partitions. In some cases, however, it is useful to partition data by some other function of the key. For example, using "hash(Hostname(urlkey)) mod R" as the partitioning function causes all URLs from the same host to end up in the same output file.
+
+### 4.2 Ordering Guarantees
+
+We guarantee that within a given partition, the intermediate key/value pairs are processed in increasing key order. This ordering guarantee makes it easy to generate a sorted output file per partition, which is useful when the output file format needs to support efficient random access lookups by key, or users of the output find it convenient to have the data sorted.
+
+### 4.3 Combiner Function
+
+In some cases, there is significant repetition in the intermediate keys produced by each map task, and the user-specified Reduce function is commutative and associative. We allow the user to specify an optional **Combiner** function that does partial merging of this data before it is sent over the network. The Combiner function is executed on each machine that performs a map task. Typically the same code is used to implement both the combiner and the reduce functions. Partial combining significantly speeds up certain classes of MapReduce operations. Appendix A contains an example that uses a combiner.
+
+### 4.4 Input and Output Types
+
+The MapReduce library provides support for reading input data in several different formats (e.g., "text" mode treats each line as a key/value pair). Users can add support for a new input type by providing an implementation of a simple reader interface. In a similar fashion, we support a set of output types for producing data in different formats.
+
+### 4.5 Side-effects
+
+In some cases, users of MapReduce have found it convenient to produce auxiliary files as additional outputs from their map and/or reduce operators. We rely on the application writer to make such side-effects atomic and idempotent. Typically the application writes to a temporary file and atomically renames this file once it has been fully generated.
+
+### 4.6 Skipping Bad Records
+
+Sometimes there are bugs in user code that cause the Map or Reduce functions to crash deterministically on certain records. We provide an optional mode of execution where the MapReduce library detects which records cause deterministic crashes and skips these records in order to make forward progress. Each worker process installs a signal handler that catches segmentation violations and bus errors; the sequence number of the argument is stored before invoking user code; on signal, a "last gasp" UDP packet is sent to the master; when the master has seen more than one failure on a particular record, it indicates that the record should be skipped on the next re-execution.
+
+### 4.7 Local Execution
+
+To help facilitate debugging, profiling, and small-scale testing, we have developed an alternative implementation of the MapReduce library that sequentially executes all of the work for a MapReduce operation on the local machine. Controls are provided to the user so that the computation can be limited to particular map tasks. Users invoke their program with a special flag and can then easily use any debugging or testing tools they find useful (e.g. gdb).
+
+### 4.8 Status Information
+
+The master runs an internal HTTP server and exports a set of status pages for human consumption. The status pages show the progress of the computation, such as how many tasks have been completed, how many are in progress, bytes of input, bytes of intermediate data, bytes of output, processing rates, etc. The pages also contain links to the standard error and standard output files generated by each task.
+
+### 4.9 Counters
+
+The MapReduce library provides a counter facility to count occurrences of various events. User code creates a named counter object and then increments the counter appropriately in the Map and/or Reduce function. Example:
+
+```cpp
+Counter* uppercase;
+uppercase = GetCounter("uppercase");
+map(String name, String contents):
+ for each word w in contents:
+ if (IsCapitalized(w)):
+ uppercase->Increment();
+ EmitIntermediate(w, "1");
+```
+
+The counter values from individual worker machines are periodically propagated to the master (piggybacked on the ping response). The master aggregates the counter values from successful map and reduce tasks and returns them to the user code when the MapReduce operation is completed. Some counter values are automatically maintained by the MapReduce library, such as the number of input key/value pairs processed and the number of output key/value pairs produced.
+
+---
+
+## 5 Performance
+
+In this section we measure the performance of MapReduce on two computations running on a large cluster of machines. One computation searches through approximately one terabyte of data looking for a particular pattern. The other computation sorts approximately one terabyte of data.
+
+### 5.1 Cluster Configuration
+
+All of the programs were executed on a cluster that consisted of approximately 1800 machines. Each machine had two 2GHz Intel Xeon processors with Hyper-Threading enabled, 4GB of memory, two 160GB IDE disks, and a gigabit Ethernet link. The machines were arranged in a two-level tree-shaped switched network with approximately 100-200 Gbps of aggregate bandwidth available at the root. All of the machines were in the same hosting facility and therefore the round-trip time between any pair of machines was less than a millisecond. Out of the 4GB of memory, approximately 1-1.5GB was reserved by other tasks running on the cluster. The programs were executed on a weekend afternoon, when the CPUs, disks, and network were mostly idle.
+
+### 5.2 Grep
+
+The grep program scans through 10^10 100-byte records, searching for a relatively rare three-character pattern (the pattern occurs in 92,337 records). The input is split into approximately 64MB pieces (M = 15000), and the entire output is placed in one file (R = 1).
+
+
+
+**Figure 2: Data transfer rate over time**
+
+### 5.3 Sort
+
+The sort program sorts 10^10 100-byte records (approximately 1 terabyte of data). This program is modeled after the TeraSort benchmark [10]. The sorting program consists of less than 50 lines of user code. A three-line Map function extracts a 10-byte sorting key from a text line and emits the key and the original text line as the intermediate key/value pair. We used a built-in Identity function as the Reduce operator. The input data is split into 64MB pieces (M = 15000). We partition the sorted output into 4000 files (R = 4000).
+
+
+
+**Figure 3: Data transfer rates over time for different executions of the sort program**
+
+### 5.4 Effect of Backup Tasks
+
+With backup tasks disabled, the execution has a very long tail where hardly any write activity occurs. After 960 seconds, all except 5 of the reduce tasks are completed. However these last few stragglers don't finish until 300 seconds later. The entire computation takes 1283 seconds, an increase of 44% in elapsed time.
+
+### 5.5 Machine Failures
+
+In an execution where 200 out of 1746 worker processes were intentionally killed several minutes into the computation, the worker deaths show up as a negative input rate since some previously completed map work disappears and needs to be redone. The re-execution of this map work happens relatively quickly. The entire computation finishes in 933 seconds including startup overhead (just an increase of 5% over the normal execution time).
+
+---
+
+## 6 Experience
+
+We wrote the first version of the MapReduce library in February of 2003, and made significant enhancements to it in August of 2003. Since that time, MapReduce has been used across a wide range of domains within Google, including:
+
+- large-scale machine learning problems,
+- clustering problems for the Google News and Froogle products,
+- extraction of data used to produce reports of popular queries (e.g. Google Zeitgeist),
+- extraction of properties of web pages for new experiments and products,
+- and large-scale graph computations.
+
+
+
+**Figure 4: MapReduce instances over time** — Growth from 0 in early 2003 to almost 900 separate instances as of late September 2004.
+
+| Metric | Value |
+| ------------------------------- | ----------- |
+| Number of jobs | 29,423 |
+| Average job completion time | 634 secs |
+| Machine days used | 79,186 days |
+| Input data read | 3,288 TB |
+| Intermediate data produced | 758 TB |
+| Output data written | 193 TB |
+| Average worker machines per job | 157 |
+| Average worker deaths per job | 1.2 |
+| Average map tasks per job | 3,351 |
+| Average reduce tasks per job | 55 |
+| Unique map implementations | 395 |
+| Unique reduce implementations | 269 |
+| Unique map/reduce combinations | 426 |
+
+**Table 1:** MapReduce jobs run in August 2004
+
+### 6.1 Large-Scale Indexing
+
+One of our most significant uses of MapReduce to date has been a complete rewrite of the production indexing system that produces the data structures used for the Google web search service. The indexing system takes as input a large set of documents (raw contents more than 20 terabytes of data). The indexing process runs as a sequence of five to ten MapReduce operations. Benefits:
+
+- The indexing code is simpler, smaller, and easier to understand (e.g., one phase dropped from ~3800 lines of C++ to ~700 lines when expressed using MapReduce).
+- The performance of the MapReduce library is good enough that we can keep conceptually unrelated computations separate, making it easy to change the indexing process.
+- The indexing process has become much easier to operate, because most problems caused by machine failures, slow machines, and networking hiccups are dealt with automatically by the MapReduce library.
+
+---
+
+## 7 Related Work
+
+Many systems have provided restricted programming models and used the restrictions to parallelize the computation automatically. MapReduce can be considered a simplification and distillation of some of these models based on our experience with large real-world computations. More significantly, we provide a fault-tolerant implementation that scales to thousands of processors.
+
+- **Bulk Synchronous Programming [17]** and **MPI [11]**: MapReduce exploits a restricted programming model to parallelize the user program automatically and to provide transparent fault-tolerance.
+- **Locality**: Our locality optimization draws inspiration from techniques such as **active disks [12, 15]**, where computation is pushed close to local disks.
+- **Backup tasks**: Similar to the eager scheduling mechanism in the **Charlotte System [3]**. We fix some instances of repeated failures with our mechanism for skipping bad records.
+- **Cluster management**: Similar in spirit to **Condor [16]**.
+- **Sorting**: Similar in operation to **NOW-Sort [1]**; MapReduce adds user-definable Map and Reduce functions.
+- **River [2]**: MapReduce partitions the problem into a large number of fine-grained tasks and uses redundant execution near the end of the job to reduce completion time.
+- **BAD-FS [5]**, **TACC [7]**: Similar use of re-execution and locality-aware scheduling for fault-tolerance.
+
+---
+
+## 8 Conclusions
+
+The MapReduce programming model has been successfully used at Google for many different purposes. We attribute this success to several reasons:
+
+1. The model is easy to use, even for programmers without experience with parallel and distributed systems.
+2. A large variety of problems are easily expressible as MapReduce computations.
+3. We have developed an implementation that scales to large clusters of machines comprising thousands of machines.
+
+We have learned: (1) Restricting the programming model makes it easy to parallelize and distribute computations and to make such computations fault-tolerant. (2) Network bandwidth is a scarce resource; optimizations target reducing data sent across the network. (3) Redundant execution can be used to reduce the impact of slow machines and to handle machine failures and data loss.
+
+---
+
+## Acknowledgements
+
+Josh Levenberg revised and extended the user-level MapReduce API. MapReduce reads its input from and writes its output to the Google File System [8]. Thanks to Mohit Aron, Howard Gobioff, Markus Gutschke, David Kramer, Shun-Tak Leung, Josh Redstone (GFS); Percy Liang, Olcan Sercinoglu (cluster management); and to Mike Burrows, Wilson Hsieh, Josh Levenberg, Sharon Perl, Rob Pike, Debby Wallach, the anonymous OSDI reviewers, and shepherd Eric Brewer.
+
+---
+
+## References
+
+[1] Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, David E. Culler, Joseph M. Hellerstein, and David A. Patterson. High-performance sorting on networks of workstations. In *Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data*, Tucson, Arizona, May 1997.
+
+[2] Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David Patterson, and Kathy Yelick. Cluster I/O with River: Making the fast case common. In *Proceedings of the Sixth Workshop on Input/Output in Parallel and Distributed Systems (IOPADS '99)*, pages 10–22, Atlanta, Georgia, May 1999.
+
+[3] Arash Baratloo, Mehmet Karaul, Zvi Kedem, and Peter Wyckoff. Charlotte: Metacomputing on the web. In *Proceedings of the 9th International Conference on Parallel and Distributed Computing Systems*, 1996.
+
+[4] Luiz A. Barroso, Jeffrey Dean, and Urs Hölzle. Web search for a planet: The Google cluster architecture. *IEEE Micro*, 23(2):22–28, April 2003.
+
+[5] John Bent, Douglas Thain, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, and Miron Livny. Explicit control in a batch-aware distributed file system. In *Proceedings of the 1st USENIX Symposium on Networked Systems Design and Implementation NSDI*, March 2004.
+
+[6] Guy E. Blelloch. Scans as primitive parallel operations. *IEEE Transactions on Computers*, C-38(11), November 1989.
+
+[7] Armando Fox, Steven D. Gribble, Yatin Chawathe, Eric A. Brewer, and Paul Gauthier. Cluster-based scalable network services. In *Proceedings of the 16th ACM Symposium on Operating System Principles*, pages 78–91, Saint-Malo, France, 1997.
+
+[8] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google file system. In *19th Symposium on Operating Systems Principles*, pages 29–43, Lake George, New York, 2003.
+
+[9] S. Gorlatch. Systematic efficient parallelization of scan and other list homomorphisms. In L. Bouge, P. Fraigniaud, A. Mignotte, and Y. Robert, editors, *Euro-Par'96. Parallel Processing*, Lecture Notes in Computer Science 1124, pages 401–408. Springer-Verlag, 1996.
+
+[10] Jim Gray. Sort benchmark home page. http://research.microsoft.com/barc/SortBenchmark/.
+
+[11] William Gropp, Ewing Lusk, and Anthony Skjellum. *Using MPI: Portable Parallel Programming with the Message-Passing Interface*. MIT Press, Cambridge, MA, 1999.
+
+[12] L. Huston, R. Sukthankar, R. Wickremesinghe, M. Satyanarayanan, G. R. Ganger, E. Riedel, and A. Ailamaki. Diamond: A storage architecture for early discard in interactive search. In *Proceedings of the 2004 USENIX File and Storage Technologies FAST Conference*, April 2004.
+
+[13] Richard E. Ladner and Michael J. Fischer. Parallel prefix computation. *Journal of the ACM*, 27(4):831–838, 1980.
+
+[14] Michael O. Rabin. Efficient dispersal of information for security, load balancing and fault tolerance. *Journal of the ACM*, 36(2):335–348, 1989.
+
+[15] Erik Riedel, Christos Faloutsos, Garth A. Gibson, and David Nagle. Active disks for large-scale data processing. *IEEE Computer*, pages 68–74, June 2001.
+
+[16] Douglas Thain, Todd Tannenbaum, and Miron Livny. Distributed computing in practice: The Condor experience. *Concurrency and Computation: Practice and Experience*, 2004.
+
+[17] L. G. Valiant. A bridging model for parallel computation. *Communications of the ACM*, 33(8):103–111, 1997.
+
+[18] Jim Wyllie. Spsort: How to sort a terabyte quickly. http://almaden.ibm.com/cs/spsort.pdf.
+
+---
+
+## Appendix A: Word Frequency
+
+This section contains a program that counts the number of occurrences of each unique word in a set of input files specified on the command line.
+
+```cpp
+#include "mapreduce/mapreduce.h"
+
+// User's map function
+class WordCounter : public Mapper {
+ public:
+ virtual void Map(const MapInput& input) {
+ const string& text = input.value();
+ const int n = text.size();
+ for (int i = 0; i < n; ) {
+ // Skip past leading whitespace
+ while ((i < n) && isspace(text[i]))
+ i++;
+ // Find word end
+ int start = i;
+ while ((i < n) && !isspace(text[i]))
+ i++;
+ if (start < i)
+ Emit(text.substr(start,i-start),"1");
+ }
+ }
+};
+REGISTER_MAPPER(WordCounter);
+
+// User's reduce function
+class Adder : public Reducer {
+ virtual void Reduce(ReduceInput* input) {
+ // Iterate over all entries with the same key and add the values
+ int64 value = 0;
+ while (!input->done()) {
+ value += StringToInt(input->value());
+ input->NextValue();
+ }
+ // Emit sum for input->key()
+ Emit(IntToString(value));
+ }
+};
+REGISTER_REDUCER(Adder);
+
+int main(int argc, char** argv) {
+ ParseCommandLineFlags(argc, argv);
+ MapReduceSpecification spec;
+ // Store list of input files into "spec"
+ for (int i = 1; i < argc; i++) {
+ MapReduceInput* input = spec.add_input();
+ input->set_format("text");
+ input->set_filepattern(argv[i]);
+ input->set_mapper_class("WordCounter");
+ }
+ // Specify the output files
+ MapReduceOutput* out = spec.output();
+ out->set_filebase("/gfs/test/freq");
+ out->set_num_tasks(100);
+ out->set_format("text");
+ out->set_reducer_class("Adder");
+ // Optional: do partial sums within map tasks to save network bandwidth
+ out->set_combiner_class("Adder");
+ // Tuning parameters
+ spec.set_machines(2000);
+ spec.set_map_megabytes(100);
+ spec.set_reduce_megabytes(100);
+ // Now run it
+ MapReduceResult result;
+ if (!MapReduce(spec, &result)) abort();
+ return 0;
+}
+```
\ No newline at end of file
diff --git a/docs/papers/mapreduce.pdf b/docs/papers/mapreduce.pdf
new file mode 100644
index 0000000..f9a1ef9
Binary files /dev/null and b/docs/papers/mapreduce.pdf differ
diff --git a/docs/papers/raft-extended-cn.md b/docs/papers/raft-extended-cn.md
new file mode 100644
index 0000000..5de38e4
--- /dev/null
+++ b/docs/papers/raft-extended-cn.md
@@ -0,0 +1,665 @@
+# 寻找一种可理解的共识算法(扩展版)
+
+**Diego Ongaro 与 John Ousterhout**
+斯坦福大学
+
+*本技术报告为 [32] 的扩展版;页边灰色条标注为新增内容。发表于 2014 年 5 月 20 日。*
+
+## 摘要
+
+Raft 是一种用于管理复制日志的共识算法。其效果与(多)Paxos 等价,效率相当,但结构不同;这使得 Raft 比 Paxos 更易理解,并为构建实用系统提供了更好的基础。为提高可理解性,Raft 将共识的关键要素分离,如 leader 选举、日志复制与安全性,并强化一致性以减少需要考虑的状态数量。用户研究表明,学生更容易学会 Raft 而非 Paxos。Raft 还包含一种新的集群成员变更机制,通过重叠多数来保证安全。
+
+## 1 引言
+
+共识算法使一组机器能够作为可承受部分成员故障的协调整体工作,因此在构建可靠的大规模软件系统中扮演关键角色。过去十年间,Paxos [15, 16] 主导了共识算法的讨论:多数共识实现基于或受其影响,Paxos 也成为教授共识的主要载体。
+
+遗憾的是,尽管有大量使其更易理解的尝试,Paxos 仍然非常难懂。此外,其架构需要复杂改动才能支持实用系统。因此,无论是系统构建者还是学生都在与 Paxos 角力。
+
+在自身与 Paxos 角力之后,我们着手寻找一种新的共识算法,为系统构建和教育提供更好基础。我们的做法不同寻常:首要目标是可理解性——能否为实用系统定义一种共识算法,并以明显比 Paxos 更易学的方式描述?此外,我们希望算法能帮助形成系统构建者所必需的直觉。算法不仅要正确,而且要让人一眼看出为何正确。
+
+这项工作的结果是一种名为 Raft 的共识算法。在设计 Raft 时,我们采用了提高可理解性的具体技术,包括分解(Raft 将 leader 选举、日志复制与安全性分开)和状态空间缩减(相对 Paxos,Raft 减少了非确定性程度以及各服务器日志不一致的方式)。对两所大学 43 名学生的用户研究表明,Raft 明显更易理解:在学完两种算法后,其中 33 名学生在回答 Raft 相关问题上优于 Paxos。
+
+Raft 与现有共识算法(尤其是 Oki 与 Liskov 的 Viewstamped Replication [29, 22])在许多方面相似,但具有若干新特点:
+
+- **强 leader:** Raft 采用比其他共识算法更强的 leader 形式。例如,日志条目仅从 leader 流向其他服务器,简化了复制日志的管理并使 Raft 更易理解。
+- **Leader 选举:** Raft 使用随机化定时器选举 leader,在已有心跳机制上只增加少量机制,即可简单快速地解决冲突。
+- **成员变更:** Raft 的集群服务器集变更机制采用新的联合共识(joint consensus)方式,在过渡期间两种配置的多数派重叠,使集群在配置变更期间仍可正常运作。
+
+我们相信 Raft 在教育与实现基础上均优于 Paxos 及其他共识算法:更简单、更易理解;描述足够完整以满足实用系统需求;有多个开源实现并被多家公司使用;安全性已形式化规范并证明;效率与其他算法相当。
+
+本文其余部分介绍复制状态机问题(第 2 节)、讨论 Paxos 的优缺点(第 3 节)、描述我们关于可理解性的一般思路(第 4 节)、给出 Raft 共识算法(第 5–8 节)、评估 Raft(第 9 节)并讨论相关工作(第 10 节)。
+
+## 2 复制状态机
+
+共识算法通常出现在复制状态机 [37] 的语境中。在该方法中,各服务器上的状态机计算相同状态的相同副本,即使部分服务器宕机也能继续运行。复制状态机用于解决分布式系统中的多种容错问题。例如,具有单一集群 leader 的大规模系统(如 GFS [8]、HDFS [38]、RAMCloud [33])通常使用独立的复制状态机来管理 leader 选举并存储必须在 leader 崩溃后保留的配置信息。复制状态机的例子包括 Chubby [2] 和 ZooKeeper [11]。
+
+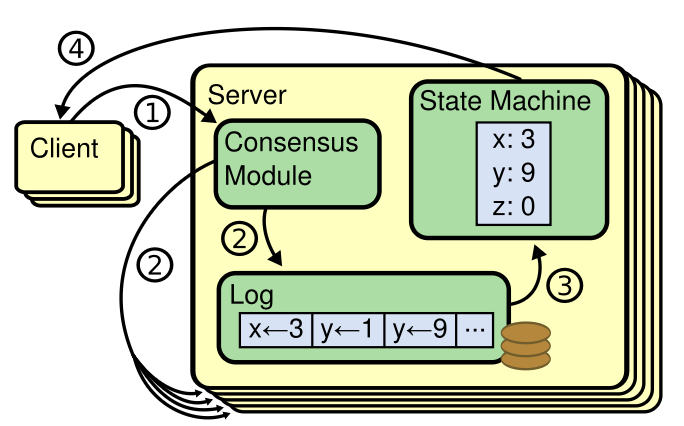
+
+**图 1:** 复制状态机架构。共识算法管理一个包含来自客户端的 state machine 命令的复制日志。各 state machine 按相同顺序处理日志中的命令,因此产生相同输出。
+
+复制状态机通常用复制日志实现,如图 1。每台服务器保存一个包含一系列命令的日志,由其 state machine 按序执行。每条日志包含相同命令且顺序相同,故每台 state machine 处理相同命令序列。由于 state machine 是确定性的,每台计算出相同状态与相同输出序列。
+
+保持复制日志一致是共识算法的职责。服务器上的共识模块接收客户端命令并加入其日志,与其他服务器上的共识模块通信,确保即使部分服务器故障,每条日志最终也以相同顺序包含相同请求。命令被正确复制后,各服务器的 state machine 按日志顺序处理它们,并将输出返回客户端。因此,这些服务器在行为上如同一台高可用的 state machine。
+
+实用系统中的共识算法通常具有以下性质:
+
+- 在所有非拜占庭条件下(包括网络延迟、分区、丢包、重复与乱序)保证安全(永不返回错误结果)。
+- 只要任意多数服务器可用且能彼此及与客户端通信,系统就完全可用。因此,典型的五台服务器集群可容忍任意两台故障。假定服务器以停机方式故障;之后可从稳定存储恢复并重新加入集群。
+- 不依赖时间假设来保证日志一致性:故障时钟与极端消息延迟最多导致可用性问题。
+- 在常见情况下,只要集群多数在一次远程过程调用(RPC)中响应,命令即可完成;少数慢速服务器不必影响整体性能。
+
+## 3 Paxos 的问题
+
+过去十年,Leslie Lamport 的 Paxos 协议 [15] 几乎成为共识的同义词:它是课程中最常讲授的协议,多数共识实现以其为起点。Paxos 首先定义能在单一决策(如一条复制日志条目)上达成一致的协议,我们称这部分为 single-decree Paxos。Paxos 随后将多个该协议实例组合以支持一系列决策(即一条日志,multi-Paxos)。Paxos 保证安全与活性,并支持集群成员变更。其正确性已获证明,在正常情况下也高效。
+
+但 Paxos 有两个明显缺点。
+
+第一,Paxos 极其难懂。完整阐述 [15] 以晦涩著称;很少有人能理解,且需付出很大努力。因此出现了多种用更简单语言解释 Paxos 的尝试 [16, 20, 21]。这些解释聚焦 single-decree 子集,仍然很有挑战。在 NSDI 2012 的非正式调查中,即便在资深研究者中也很少有人对 Paxos 感到自如。我们自己也与 Paxos 角力;直到阅读多种简化解释并设计了自己的替代协议,才理解完整协议,这一过程花了近一年。
+
+我们假设 Paxos 的晦涩源于它以 single-decree 子集为基础。Single-decree Paxos 稠密而微妙:分为两个阶段,既没有简单的直观解释,也无法独立理解。因此难以形成“为何 single-decree 协议有效”的直觉。multi-Paxos 的组合规则又带来大量复杂性与微妙之处。我们相信,在多个决策上达成共识(即一条日志而非单条)的整体问题,可以用更直接、更显然的方式分解。
+
+第二,Paxos 并未为构建实用实现提供良好基础。原因之一是没有被广泛认同的 multi-Paxos 算法。Lamport 的叙述主要关于 single-decree Paxos;他勾勒了 multi-Paxos 的可能做法,但许多细节缺失。虽有 [26]、[39]、[13] 等对 Paxos 的充实与优化尝试,它们彼此不同,也与 Lamport 的草图不同。Chubby [4] 等系统实现了类 Paxos 算法,但多数细节未公开。
+
+此外,Paxos 的架构不利于构建实用系统;这也是 single-decree 分解的后果。例如,先独立选出一组日志条目再合并成顺序日志收益甚少,只会增加复杂度。围绕日志设计系统更简单高效:新条目在约束顺序下顺序追加。另一问题是 Paxos 核心采用对称的对等方式(尽管后来建议弱形式的 leader 作为性能优化)。在只做一次决策的简化世界里合理,但实用系统很少如此。若要做出系列决策,先选 leader、再由 leader 协调决策更简单、更快。
+
+因此,实用系统与 Paxos 相去甚远。每个实现从 Paxos 起步,发现实现困难,然后发展出差异很大的架构。这既耗时又易错,而理解 Paxos 的困难又加剧了问题。Paxos 的表述或许适合证明其正确性定理,但实际实现与 Paxos 差异如此之大,以至于这些证明价值有限。Chubby 实现者的以下评论很有代表性:
+
+> Paxos 算法描述与真实系统需求之间存在显著鸿沟……最终系统将基于未经证明的协议 [4]。
+>
+
+鉴于这些问题,我们得出结论:Paxos 无论对系统构建还是教育都不是良好基础。考虑到共识在大规模软件系统中的重要性,我们决定尝试设计一种比 Paxos 性质更好的替代共识算法。Raft 就是该实验的产物。
+
+## 4 为可理解性而设计
+
+设计 Raft 时我们有若干目标:必须为系统构建提供完整且实用的基础,显著减少开发者所需的设计工作;必须在所有条件下安全、在典型运行条件下可用;必须对常见操作高效。但我们最重要也最困难的目标是可理解性。必须让大量读者能轻松理解算法;此外,必须能形成对算法的直觉,以便系统构建者能做出实际实现中不可避免的扩展。
+
+在 Raft 设计中有许多需要在不同方案间做选择的点。在这些情况下我们按可理解性评估:每种方案有多难解释(例如状态空间多复杂、是否有微妙含义)?读者能否完全理解该方案及其含义?
+
+我们承认这类分析主观性很强;尽管如此,我们采用了两条通用技术。其一是众所周知的问题分解:尽可能将问题拆成可相对独立地解决、解释和理解的子问题。例如在 Raft 中我们分离了 leader 选举、日志复制、安全性与成员变更。
+
+其二是通过减少需要考虑的状态来简化状态空间,使系统更一致,并在可能时消除非确定性。具体地,日志不允许出现空洞,且 Raft 限制了日志彼此不一致的方式。尽管在多数情况下我们试图消除非确定性,但在某些情形下非确定性反而提高可理解性。尤其是随机化方法会引入非确定性,却倾向于用统一方式处理所有可能选择(“任选其一;无所谓”)来缩小状态空间。我们用随机化简化了 Raft 的 leader 选举算法。
+
+## 5 Raft 共识算法
+
+Raft 是第 2 节所述形式的复制日志管理算法。图 2 以浓缩形式概括该算法供参考,图 3 列出算法的关键性质;这些图的内容将在本节其余部分分段讨论。
+
+Raft 通过先选举一个 distinguished leader,再赋予该 leader 管理复制日志的完整责任来实现共识。Leader 接受来自客户端的日志条目、在其他服务器上复制它们,并告知各服务器何时可以安全地将日志条目应用到其 state machine。拥有 leader 简化了复制日志的管理:例如 leader 可在不咨询其他服务器的情况下决定将新条目放在日志何处,数据以简单方式从 leader 流向其他服务器。Leader 可能故障或与其他服务器断开,此时会选举新 leader。
+
+在 leader 方案下,Raft 将共识问题分解为三个相对独立的子问题,分别在以下小节讨论:
+
+- **Leader 选举:** 当现有 leader 失败时必须选出新 leader(第 5.2 节)。
+- **日志复制:** Leader 必须接受客户端的日志条目并在集群中复制,使其他日志与其一致(第 5.3 节)。
+- **安全性:** Raft 的关键安全性质是图 3 中的 State Machine Safety:若某服务器已将某条日志条目应用到其 state machine,则其他服务器不得对同一 index 应用不同的日志条目。第 5.4 节描述 Raft 如何保证该性质;解决方案涉及对第 5.2 节选举机制的额外限制。
+
+在介绍共识算法之后,本节还会讨论可用性以及时间在系统中的作用。
+
+> **State**
+>
+>
+> **所有服务器上的持久状态**:
+>
+> *(在响应 RPC 前更新到稳定存储)*
+>
+> `currentTerm`: 服务器已知的最新 term(首次启动时初始化为 0,单调递增)
+>
+> `votedFor`: 当前 term 获得投票的 candidateId(若无则为 null)
+>
+> `log[]`: 日志条目;每条包含发给 state machine 的 command,以及 leader 收到该条目时的 term(首条 index 为 1)
+>
+>
+> **所有服务器上的易失状态:**
+>
+> `commitIndex`: 已知已提交的最高日志条目的 index(初始化为 0,单调递增)
+>
+> `lastApplied`: 已应用到 state machine 的最高日志条目的 index(初始化为 0,单调递增)
+>
+>
+> **Leader 上的易失状态:**
+>
+> *(选举后重新初始化)*
+>
+>
+> `nextIndex[]`: 对每个服务器,要发给该服务器的下一条日志条目的 index(初始化为 leader 最后一条日志 index + 1)
+>
+> `matchIndex[]`: 对每个服务器,已知已在该服务器上复制的最高日志条目的 index(初始化为 0,单调递增)
+>
+
+> **AppendEntries RPC**
+>
+>
+> *由 leader 调用以复制日志条目(§5.3);也用作心跳(§5.2)。*
+>
+>
+> **参数:**
+>
+> `term`: leader 的 term
+>
+> `leaderId`: 便于 follower 将客户端重定向到 leader
+>
+> `prevLogIndex`: 紧接在新条目之前的日志条目的 index
+>
+> `prevLogTerm`: prevLogIndex 条目的 term
+>
+> `entries[]`: 要存储的日志条目(心跳时为空;可为效率一次发送多条)
+>
+> `leaderCommit`: leader 的 commitIndex
+>
+>
+> **返回:**
+>
+> `term`: currentTerm,供 leader 更新自身
+>
+> `success`: 若 follower 在 prevLogIndex 处包含与 prevLogTerm 匹配的条目则为 true
+>
+>
+> **接收者实现:**
+>
+> 1. 若 term < currentTerm 则返回 false(§5.1)
+>
+> 2. 若日志在 prevLogIndex 处不包含 term 与 prevLogTerm 匹配的条目则返回 false(§5.3)
+>
+> 3. 若已有条目与新条目冲突(同 index 不同 term),删除该条目及之后所有条目(§5.3)
+>
+> 4. 追加尚未在日志中的新条目
+>
+> 5. 若 leaderCommit > commitIndex,则令 commitIndex = min(leaderCommit, 最后一条新条目的 index)
+>
+
+> **RequestVote RPC**
+>
+>
+> *由 candidate 调用以收集选票(§5.2)。*
+>
+>
+> **参数:**
+>
+> `term`: candidate 的 term
+>
+> `candidateId`: 请求投票的 candidate
+>
+> `lastLogIndex`: candidate 最后一条日志条目的 index(§5.4)
+>
+> `lastLogTerm`: candidate 最后一条日志条目的 term(§5.4)
+>
+>
+> **返回:**
+>
+> `term`: currentTerm,供 candidate 更新自身
+>
+> `voteGranted`: true 表示 candidate 获得投票
+>
+>
+> **接收者实现:**
+>
+> 1. 若 term < currentTerm 则返回 false(§5.1)
+>
+> 2. 若 votedFor 为 null 或 candidateId,且 candidate 的日志至少与接收者一样新,则授予投票(§5.2, §5.4)
+>
+
+> **服务器规则**
+>
+>
+> **所有服务器:**
+>
+> - 若 commitIndex > lastApplied:递增 lastApplied,将 log[lastApplied] 应用到 state machine(§5.3)
+>
+> - 若 RPC 请求或响应包含 term T > currentTerm:令 currentTerm = T,转为 follower(§5.1)
+>
+>
+> **Follower(§5.2):**
+>
+> - 响应来自 candidate 与 leader 的 RPC
+>
+> - 若在未收到当前 leader 的 AppendEntries RPC 且未向 candidate 投票的情况下选举超时:转为 candidate
+>
+>
+> **Candidate(§5.2):**
+>
+> - 转为 candidate 时发起选举:
+>
+> - 递增 currentTerm
+>
+> - 投票给自己
+>
+> - 重置选举定时器
+>
+> - 向所有其他服务器发送 RequestVote RPC
+>
+> - 若收到多数服务器的投票:成为 leader
+>
+> - 若收到新 leader 的 AppendEntries RPC:转为 follower
+>
+> - 若选举超时:发起新一轮选举
+>
+>
+> **Leader:**
+>
+> - 当选后:向每台服务器发送初始空 AppendEntries RPC(心跳);在空闲期重复以阻止选举超时(§5.2)
+>
+> - 若从客户端收到 command:追加条目到本地日志,在条目应用到 state machine 后响应(§5.3)
+>
+> - 若某 follower 的 last log index ≥ nextIndex:从 nextIndex 开始发送包含日志条目的 AppendEntries RPC
+>
+> - 若成功:更新该 follower 的 nextIndex 与 matchIndex(§5.3)
+>
+> - 若因日志不一致导致 AppendEntries 失败:递减 nextIndex 并重试(§5.3)
+>
+> - 若存在 N 使得 N > commitIndex、多数 matchIndex[i] ≥ N 且 log[N].term == currentTerm:令 commitIndex = N(§5.3, §5.4)
+>
+
+**图 2:** Raft 共识算法浓缩摘要(不含成员变更与日志压缩)。左上框中的服务器行为被描述为一系列独立、重复触发的规则。§5.2 等节号表示该特性在何处讨论。形式化规范 [31] 更精确地描述了算法。
+
+> **Election Safety:** 在给定 term 中至多选出一名 leader。§5.2
+>
+> **Leader Append-Only:** leader 从不覆盖或删除其日志中的条目;只追加新条目。§5.3
+>
+> **Log Matching:** 若两条日志在相同 index 和 term 处包含条目,则在该 index 之前两条日志完全相同。§5.3
+>
+> **Leader Completeness:** 若某日志条目在给定 term 内被提交,则该条目将出现在所有更大 term 的 leader 的日志中。§5.4
+>
+> **State Machine Safety:** 若某服务器已将某 index 处的日志条目应用到其 state machine,则其他服务器永远不会对同一 index 应用不同的日志条目。§5.4.3
+>
+
+**图 3:** Raft 保证这些性质始终成立。节号表示各性质在何处讨论。
+
+### 5.1 Raft 基础
+
+一个 Raft 集群包含若干服务器;典型数量为五台,可容忍两台故障。任意时刻每台服务器处于三种状态之一:leader、follower 或 candidate。正常运行时恰好有一名 leader,其余均为 follower。Follower 是被动的:不主动发请求,只响应 leader 与 candidate 的请求。Leader 处理所有客户端请求(若客户端联系 follower,follower 会将其重定向到 leader)。第三种状态 candidate 用于选举新 leader,见第 5.2 节。图 4 展示了状态及其转换。
+
+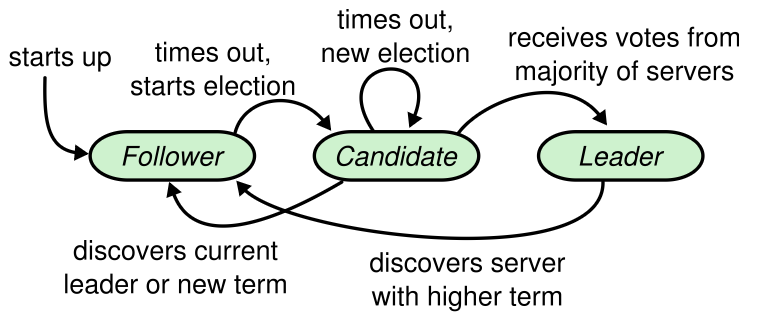
+
+**图 4:** 服务器状态。Follower 仅响应其他服务器的请求。若 follower 未收到任何通信,则变为 candidate 并发起选举。获得完整集群多数投票的 candidate 成为新 leader。Leader 通常运行直至故障。
+
+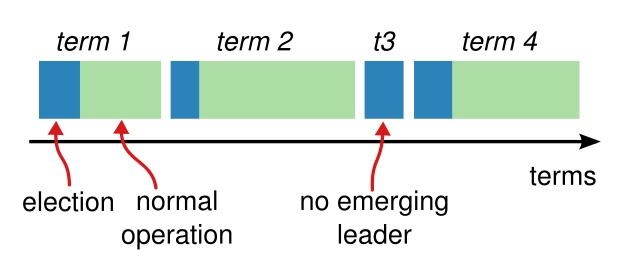
+
+**图 5:** 时间被划分为 term,每个 term 以选举开始。选举成功后,一名 leader 管理集群直至该 term 结束。部分选举会失败,此时 term 在没有选出 leader 的情况下结束。不同服务器可能在不同时刻观察到 term 之间的转换。
+
+Raft 将时间划分为任意长度的 term,如图 5。Term 用连续整数编号。每个 term 以选举开始,一名或多名 candidate 按第 5.2 节尝试成为 leader。若某 candidate 赢得选举,则在该 term 剩余时间担任 leader。有时选举会导致选票分散。此时 term 在没有 leader 的情况下结束;新的 term(伴随新选举)很快开始。Raft 保证在给定 term 中至多有一名 leader。
+
+不同服务器可能在不同时刻观察到 term 转换,某些情况下某服务器可能观察不到某次选举甚至整个 term。Term 在 Raft 中充当逻辑时钟 [14],使服务器能检测过时信息(如过期的 leader)。每台服务器保存当前 term 编号,随时间单调递增。服务器通信时会交换当前 term;若一方的 currentTerm 小于另一方,则更新为较大值。若 candidate 或 leader 发现自己的 term 已过时,立即恢复为 follower。若服务器收到带过期 term 的请求,则拒绝该请求。
+
+Raft 服务器通过远程过程调用(RPC)通信,基本共识算法只需两类 RPC。RequestVote RPC 由 candidate 在选举时发起(第 5.2 节),AppendEntries RPC 由 leader 发起以复制日志条目并作为心跳(第 5.3 节)。第 7 节增加第三种 RPC 用于在服务器间传输快照。若未及时收到响应,服务器会重试 RPC,并并行发起 RPC 以获得最佳性能。
+
+### 5.2 Leader 选举
+
+Raft 用心跳机制触发 leader 选举。服务器启动时以 follower 身份开始。只要持续收到来自 leader 或 candidate 的有效 RPC,就保持 follower。Leader 向所有 follower 定期发送心跳(不携带日志条目的 AppendEntries RPC)以维持权威。若 follower 在一段称为选举超时(election timeout)的时间内未收到任何通信,则假定没有可用 leader 并开始选举以选出新 leader。
+
+为开始选举,follower 递增其 currentTerm 并转为 candidate。随后给自己投票,并并行向集群中其他每台服务器发送 RequestVote RPC。Candidate 保持该状态直到发生以下三种情况之一:(a) 赢得选举,(b) 其他服务器确立为 leader,或 (c) 一段时间内没有胜者。
+
+若某 candidate 在同一 term 内获得完整集群中多数服务器的投票,则赢得选举。每台服务器在给定 term 内至多投给一名 candidate,先到先得(注意:第 5.4 节对投票有额外限制)。多数规则保证在特定 term 中至多一名 candidate 能赢得选举(图 3 的 Election Safety)。Candidate 赢得选举后成为 leader,随后向所有其他服务器发送心跳以确立权威并阻止新选举。
+
+在等待选票时,candidate 可能收到自称 leader 的服务器发来的 AppendEntries RPC。若该 leader 的 term(包含在其 RPC 中)至少与 candidate 的 currentTerm 一样大,candidate 承认该 leader 合法并恢复为 follower。若 RPC 中的 term 小于 candidate 的 currentTerm,candidate 拒绝该 RPC 并继续作为 candidate。
+
+第三种可能是 candidate 既未赢也未输:若多台 follower 同时变为 candidate,选票可能分散以致无人获得多数。此时每名 candidate 会超时,通过递增 term 并发起新一轮 RequestVote RPC 开始新选举。但若没有额外措施,分散选票可能无限重复。
+
+Raft 使用随机化选举超时来确保分散选票罕见且能快速解决。为防止分散,选举超时从固定区间(如 150–300ms)中随机选择。这样在多数情况下只有单台服务器会超时;它在其他服务器超时前赢得选举并发出心跳。同一机制也用于处理已发生的分散:每名 candidate 在选举开始时重启其随机选举超时,并等待超时后再开始下一轮选举,从而降低新一轮再次分散的概率。第 9.3 节表明该方式能快速选出 leader。
+
+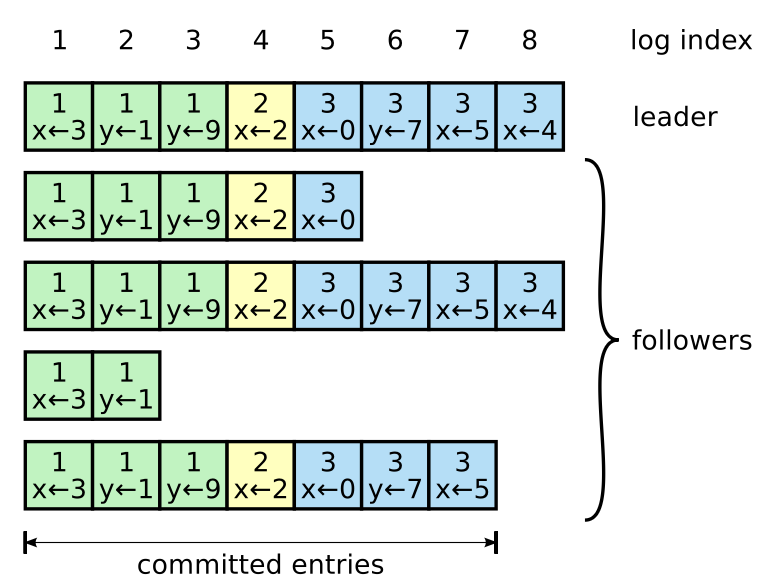
+
+**图 6:** 日志由按序编号的条目组成。每条包含创建时的 term(框中数字)以及发给 state machine 的 command。当某条目可以安全地应用到 state machine 时,该条目被视为已提交(committed)。
+
+选举是可理解性如何指导我们在设计备选间做选择的例子。我们最初计划使用排名:每名 candidate 被赋予唯一 rank,用于在竞争 candidate 间选择。若某 candidate 发现另一名 rank 更高的 candidate,会恢复为 follower 以便高 rank 的 candidate 更容易赢得下一轮选举。我们发现该方式在可用性上带来微妙问题(若高 rank 服务器故障,低 rank 服务器可能需要超时并再次成为 candidate,但若过早这样做会重置选举进度)。我们对算法做了多次调整,但每次调整后都会出现新的边界情况。最终我们得出结论:随机重试方式更直观、更易理解。
+
+### 5.3 日志复制
+
+Leader 选出后开始处理客户端请求。每个客户端请求包含要由复制 state machine 执行的 command。Leader 将 command 作为新条目追加到其日志,然后并行向其他每台服务器发送 AppendEntries RPC 以复制该条目。当条目被安全复制后(见下文),leader 将条目应用到其 state machine 并把执行结果返回客户端。若 follower 崩溃、运行缓慢或网络丢包,leader 会无限重试 AppendEntries RPC(即便在已响应客户端之后),直到所有 follower 最终都存储了所有日志条目。
+
+日志组织如图 6。每条日志条目存储一条 state machine command 以及 leader 收到该条目时的 term。日志条目中的 term 用于检测日志间的不一致并保证图 3 中的部分性质。每条日志条目还有一个整数 index 标识其在日志中的位置。
+
+Leader 决定何时可以安全地将日志条目应用到 state machine;这样的条目称为已提交(committed)。Raft 保证已提交条目持久化,并最终被所有可用 state machine 执行。当创建该条目的 leader 已将其复制到多数服务器时(如图 6 中的条目 7),该日志条目即被提交。这也会提交 leader 日志中该条目之前的所有条目,包括之前 leader 创建的条目。第 5.4 节讨论 leader 更替后应用该规则的一些细节,并说明该提交定义是安全的。Leader 记录已知已提交的最高 index,并在后续 AppendEntries RPC(含心跳)中携带该 index,使其他服务器最终得知。Follower 一旦得知某日志条目已提交,就按日志顺序将其应用到本地 state machine。
+
+我们将 Raft 的日志机制设计为在不同服务器的日志间保持高度一致。这不仅简化系统行为、使其更可预测,也是保证安全的重要一环。Raft 维持以下性质,它们共同构成图 3 的 Log Matching Property:
+
+- 若两条不同日志中的条目具有相同 index 和 term,则它们存储相同 command。
+- 若两条不同日志中的条目具有相同 index 和 term,则在该 index 之前两条日志完全相同。
+
+第一条来自:leader 在给定 term 内对给定 log index 至多创建一条条目,且日志条目在日志中的位置从不改变。第二条由 AppendEntries 的简单一致性检查保证。发送 AppendEntries RPC 时,leader 会带上其日志中紧接在新条目之前那条的 index 和 term。若 follower 在其日志中找不到 index 与 term 都匹配的条目,则拒绝新条目。该一致性检查充当归纳步:日志的初始空状态满足 Log Matching Property,且只要扩展日志,一致性检查就保持该性质。因此,每当 AppendEntries 成功返回,leader 就知道 follower 的日志在与新条目一致的部分与其相同。
+
+正常运行时,leader 与 follower 的日志保持一致,故 AppendEntries 的一致性检查不会失败。但 leader 崩溃可能使日志不一致(旧 leader 可能尚未将其日志中所有条目完全复制)。这些不一致可能在一系列 leader 与 follower 崩溃中叠加。图 7 展示了 follower 日志与新 leader 可能存在的差异:follower 可能缺少 leader 上存在的条目,可能有多出 leader 上没有的条目,或两者皆有。日志中缺失与多余条目可能跨越多个 term。
+
+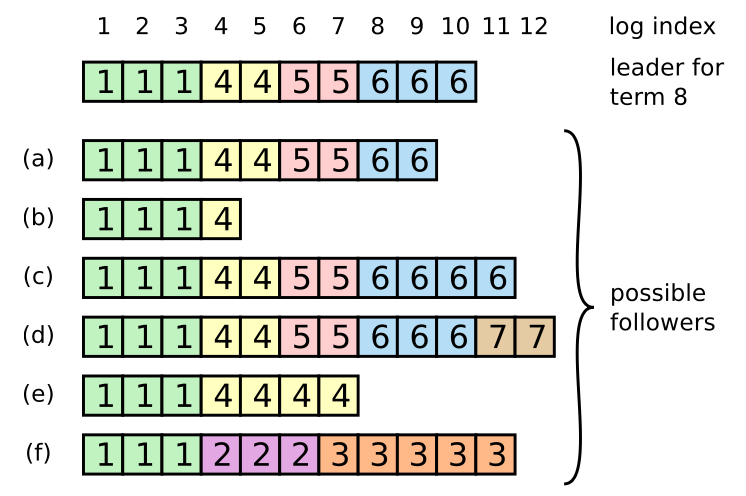
+
+**图 7:** 当顶部 leader 上台时,follower 日志可能出现 (a)–(f) 任一情况。每格代表一条日志条目;格内数字为其 term。Follower 可能缺少条目 (a–b)、可能有额外未提交条目 (c–d),或兼有 (e–f)。
+
+在 Raft 中,leader 通过强制 follower 的日志与自己的副本一致来处理不一致。即 follower 日志中的冲突条目会被 leader 日志中的条目覆盖。第 5.4 节将说明在加上一条限制后这是安全的。为使某 follower 的日志与己一致,leader 必须找到两条日志一致的最新日志条目,删除该点之后 follower 日志中的条目,并向该 follower 发送该点之后 leader 的所有条目。这些操作都在 AppendEntries RPC 执行一致性检查时完成。Leader 为每个 follower 维护 nextIndex,即将要发给该 follower 的下一条日志条目的 index。Leader 刚上台时,将所有 nextIndex 初始化为其日志最后一条的 index 加 1(图 7 中为 11)。若某 follower 的日志与 leader 不一致,下一次 AppendEntries RPC 中的一致性检查会失败。被拒后 leader 递减 nextIndex 并重试 AppendEntries RPC。最终 nextIndex 会到达 leader 与 follower 日志一致的位置。此时 AppendEntries 成功,会删除 follower 日志中的冲突条目并追加 leader 的条目(若有)。一旦 AppendEntries 成功,该 follower 的日志在本 term 内将与 leader 一致并保持。
+
+若需要,可优化协议以减少被拒的 AppendEntries RPC 数量。例如,拒绝 AppendEntries 时 follower 可附带冲突条目的 term 以及其在该 term 下存储的首条 index。据此 leader 可一次将 nextIndex 递减以跳过该 term 内所有冲突条目;每个有冲突的 term 只需一次 AppendEntries RPC,而非每条条目一次。实践中我们怀疑该优化必要性不高,因为故障不常发生且不一致条目通常不会很多。
+
+在此机制下,leader 上台时无需特别操作即可恢复日志一致性。只需按正常流程运行,日志会在 AppendEntries 一致性检查失败时自动收敛。Leader 从不覆盖或删除其自身日志中的条目(图 3 的 Leader Append-Only Property)。
+
+该日志复制机制具备第 2 节所述共识性质:只要多数服务器在线,Raft 就能接受、复制并应用新日志条目;正常情况下新条目只需一轮发往集群多数的 RPC 即可复制;单台慢 follower 不会影响性能。
+
+### 5.4 安全性
+
+前几节描述了 Raft 如何选举 leader 与复制日志条目。但仅这些机制尚不足以保证每台 state machine 以相同顺序执行完全相同的一组 command。例如,某 follower 可能在 leader 提交若干日志条目时不可用,随后被选为 leader 并用新条目覆盖这些条目,导致不同 state machine 执行不同命令序列。
+
+本节通过增加“哪些服务器可被选为 leader”的限制来补全 Raft 算法。该限制保证任意 term 的 leader 都包含之前 term 已提交的所有条目(图 3 的 Leader Completeness Property)。在此基础上,我们再精确化提交规则。最后给出 Leader Completeness 的证明梗概,并说明其如何导致复制 state machine 的正确行为。
+
+#### 5.4.1 选举限制
+
+在任何基于 leader 的共识算法中,leader 最终必须存有所有已提交的日志条目。在 Viewstamped Replication [22] 等算法中,leader 即使最初不包含所有已提交条目也可当选。这些算法包含额外机制,在选举过程中或之后识别并传输缺失条目给新 leader。遗憾的是,这会带来大量额外机制与复杂度。Raft 采用更简单的方式:保证每个新 leader 从当选那一刻起就拥有之前 term 的所有已提交条目,无需再传输。这意味着日志条目只从 leader 流向 follower,且 leader 从不覆盖其日志中已有条目。
+
+
+
+**图 8:** 时间序列说明 leader 无法仅凭旧 term 的日志条目确定提交。在 (a) 中 S1 为 leader 并部分复制了 index 2 处的日志条目。在 (b) 中 S1 崩溃;S5 在 S3、S4 与自己的投票下当选 term 3 的 leader,并在 log index 2 接受了一条不同条目。在 (c) 中 S5 崩溃;S1 重启、当选 leader 并继续复制。此时 term 2 的日志条目已在多数服务器上复制,但尚未提交。若 S1 如 (d) 般崩溃,S5 可能当选 leader(获 S2、S3、S4 投票)并用其 term 3 的条目覆盖。但若 S1 在崩溃前如 (e) 那样将当前 term 的一条条目复制到多数服务器,则该条目被提交(S5 无法赢得选举)。此时日志中该条目之前的所有条目也被提交。
+
+Raft 通过投票过程阻止其日志不包含所有已提交条目的 candidate 赢得选举。Candidate 必须联系集群多数才能当选,即每个已提交条目都至少出现在这些服务器之一上。若 candidate 的日志至少与该多数中任一日志一样新(“一样新”的定义见下),则其将拥有所有已提交条目。RequestVote RPC 实现该限制:RPC 携带 candidate 的日志信息,若投票者自己的日志比 candidate 更新,则拒绝投票。
+
+Raft 通过比较两条日志最后一条的 index 与 term 来判断谁更新。若最后一条的 term 不同,term 更大的日志更新。若最后一条 term 相同,则更长的日志更新。
+
+#### 5.4.2 提交之前 term 的条目
+
+如第 5.3 节所述,当某条目已存储在多数服务器上时,leader 即知该 term 的该条目已提交。若 leader 在提交前崩溃,后续 leader 会尝试完成复制。但 leader 不能仅因某条旧 term 的条目已在多数服务器上就立即认定其已提交。图 8 展示了旧日志条目已在多数服务器上仍可能被后续 leader 覆盖的情况。
+
+
+
+**图 9:** 若 S1(term T 的 leader)提交了其 term 的一条新日志条目,而 S5 当选后续 term U 的 leader,则至少有一台服务器(S3)既接受了该日志条目又投票给 S5。
+
+为避免图 8 这类问题,Raft 从不通过统计副本数来提交之前 term 的日志条目。只有 leader 当前 term 的日志条目才通过统计副本提交;一旦当前 term 的某条以这种方式被提交,则凭借 Log Matching Property,其之前所有条目被间接提交。某些情况下 leader 可以安全地推断某条更早的日志条目已提交(例如该条目已存在于每台服务器),但 Raft 为简单起见采用更保守的做法。
+
+Raft 在提交规则上承担这份额外复杂度,是因为 leader 在复制之前 term 的条目时保留其原始 term。在其他共识算法中,若新 leader 重新复制之前“term”的条目,必须用新的“term 编号”复制。Raft 的做法使推理日志条目更简单,因为它们在不同时间和不同日志中保持相同 term。此外,Raft 的新 leader 需要发送的来自之前 term 的日志条目少于其他算法(其他算法必须先发送冗余日志条目并重新编号才能提交)。
+
+#### 5.4.3 安全性论证
+
+在完整 Raft 算法下,我们可以更精确地论证 Leader Completeness Property 成立(该论证基于安全性证明,见第 9.2 节)。假设 Leader Completeness 不成立,然后推出矛盾。设 term T 的 leader(leaderT)提交了其 term 的一条日志条目,但该条目未被某未来 term 的 leader 存储。考虑最小的 U > T 使得其 leader(leaderU)不存储该条目。
+
+1. 该已提交条目在 leaderU 当选时必然不在其日志中(leader 从不删除或覆盖条目)。
+2. leaderT 将该条目复制到集群多数,leaderU 也获得了集群多数的投票。因此至少有一台服务器(“投票者”)既接受了 leaderT 的该条目又投票给 leaderU,如图 9。该投票者是得到矛盾的关键。
+3. 投票者必然在投票给 leaderU 之前已接受 leaderT 的该已提交条目;否则会拒绝 leaderT 的 AppendEntries 请求(其 currentTerm 会高于 T)。
+4. 投票者在投票给 leaderU 时仍保存该条目,因为(由假设)每个中间的 leader 都包含该条目,leader 从不删除条目,follower 仅在与 leader 冲突时才删除条目。
+5. 投票者将票投给 leaderU,故 leaderU 的日志至少与投票者一样新。由此得到两种矛盾之一。
+6. 若投票者与 leaderU 的最后一条日志 term 相同,则 leaderU 的日志至少与投票者一样长,故其日志包含投票者日志中的每条条目。这与“投票者包含已提交条目而 leaderU 假定不包含”矛盾。
+7. 否则 leaderU 的最后一条日志 term 必然大于投票者的。且该 term 大于 T,因为投票者的最后一条日志 term 至少为 T(其包含 term T 的已提交条目)。创建 leaderU 最后一条日志条目的更早 leader 由假设必然在其日志中包含该已提交条目。于是由 Log Matching Property,leaderU 的日志也必然包含该已提交条目,矛盾。
+8. 矛盾完成。故所有大于 T 的 term 的 leader 都包含在 term T 内提交的 term T 的所有条目。
+9. Log Matching Property 保证后续 leader 也会包含被间接提交的条目,如图 8(d) 中的 index 2。
+
+由 Leader Completeness Property 可证明图 3 的 State Machine Safety Property:若某服务器已将某 index 处的日志条目应用到其 state machine,则其他服务器永远不会对同一 index 应用不同的日志条目。当某服务器将某日志条目应用到其 state machine 时,其日志在该条目之前必须与 leader 的日志一致,且该条目必须已提交。考虑任意服务器对某 log index 进行应用的 term 中最小的那个;Log Completeness Property 保证所有更大 term 的 leader 都会存储该同一条目,故在更大 term 中应用该 index 的服务器会应用相同值。因此 State Machine Safety 成立。
+
+最后,Raft 要求服务器按 log index 顺序应用条目。结合 State Machine Safety,即所有服务器将以相同顺序向 state machine 应用完全相同的日志条目集合。
+
+### 5.5 Follower 与 candidate 崩溃
+
+此前我们主要关注 leader 故障。Follower 与 candidate 崩溃比 leader 崩溃简单得多,且处理方式相同。若 follower 或 candidate 崩溃,发往它的 RequestVote 与 AppendEntries RPC 将失败。Raft 通过无限重试处理这些故障;若崩溃的服务器重启,RPC 会成功完成。若某服务器在完成 RPC 但尚未响应时崩溃,重启后会再次收到同一 RPC。Raft 的 RPC 是幂等的,故不会造成问题。例如,若 follower 收到的 AppendEntries 请求中的日志条目已在其日志中,它会忽略新请求中的这些条目。
+
+### 5.6 时间与可用性
+
+我们对 Raft 的要求之一是安全不依赖时间:系统不能仅因某事件比预期更快或更慢就产生错误结果。但可用性(系统及时响应客户端的能力)必然依赖时间。例如,若消息往返时间比服务器典型故障间隔还长,candidate 将无法在选举中坚持足够久;没有稳定的 leader,Raft 无法取得进展。
+
+Leader 选举是 Raft 中最依赖时间的部分。只要系统满足以下时间不等式,Raft 就能选出并维持稳定 leader:
+
+**broadcastTime ≪ electionTimeout ≪ MTBF**
+
+其中 broadcastTime 是服务器并行向集群中每台服务器发送 RPC 并收到响应的平均时间;electionTimeout 即第 5.2 节的选举超时;MTBF 是单台服务器的平均故障间隔。广播时间应比选举超时小一个数量级,以便 leader 可靠地发送阻止 follower 发起选举所需的心跳;结合选举超时的随机化,该不等式也使选票分散不太可能发生。选举超时应比 MTBF 小几个数量级,使系统稳定进展。Leader 崩溃时,系统大约在选举超时时间内不可用;我们希望这只占整体时间的一小部分。
+
+广播时间与 MTBF 由底层系统决定,选举超时则需我们选择。Raft 的 RPC 通常要求接收方将信息持久化到稳定存储,故广播时间可能在 0.5ms 到 20ms 之间,取决于存储技术。因此选举超时可能在 10ms 到 500ms 之间。典型服务器 MTBF 为数月或更长,容易满足该时间要求。
+
+## 6 集群成员变更
+
+此前我们假定集群配置(参与共识算法的服务器集合)固定。实践中偶尔需要变更配置,例如在服务器故障时替换或改变复制度。虽然可以通过将整个集群下线、更新配置文件再重启来完成,这会使集群在变更期间不可用。此外,若有任何人工步骤,会带来操作错误风险。为避免这些问题,我们决定将配置变更自动化并纳入 Raft 共识算法。
+
+为使配置变更机制安全,在过渡期间任何时刻都不能出现同一 term 内选出两名 leader 的可能。不幸的是,服务器直接从旧配置切换到新配置的任何做法都不安全。无法原子地同时切换所有服务器,因此过渡期间集群可能分裂成两个独立的多数派(见图 10)。
+
+
+
+**图 10:** 直接从一种配置切换到另一种不安全,因为不同服务器会在不同时刻切换。本例中集群从三台扩展到五台。不幸的是,存在某一时刻可能在同一 term 内选出两名不同 leader,一个拥有旧配置(C_old)的多数,另一个拥有新配置(C_new)的多数。
+
+为确保安全,配置变更必须采用两阶段方式。在 Raft 中集群先切换到我们称为联合共识(joint consensus)的过渡配置;联合共识被提交后,系统再过渡到新配置。联合共识同时包含旧配置与新配置:
+
+- 日志条目被复制到两种配置中的全部服务器。
+- 两种配置中的任意服务器均可担任 leader。
+- 达成一致(选举与条目提交)需要旧配置与新配置各自的多数派同时同意。
+
+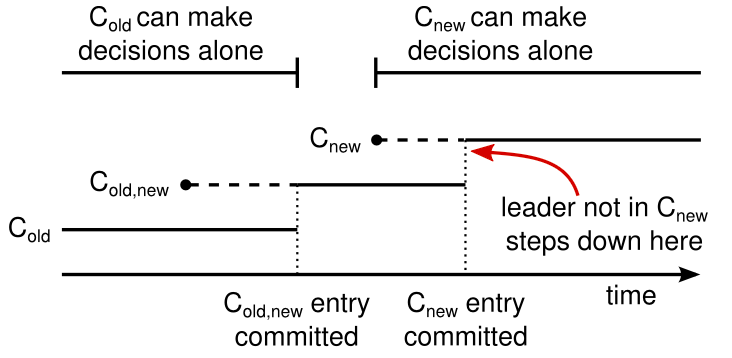
+
+**图 11:** 配置变更时间线。虚线表示已创建但未提交的配置条目,实线表示最新已提交的配置条目。Leader 先在日志中创建 C_old,new 配置条目并提交到 C_old,new(C_old 的多数与 C_new 的多数)。然后创建 C_new 条目并提交到 C_new 的多数。不存在 C_old 与 C_new 能独立做决策的时刻。
+
+联合共识允许各服务器在不同时刻完成配置过渡而不影响安全。此外,联合共识使集群能在整个配置变更期间继续服务客户端请求。
+
+集群配置通过复制日志中的特殊条目存储与传播;图 11 展示了配置变更过程。当 leader 收到从 C_old 变更到 C_new 的请求时,将联合共识的配置(图中为 C_old,new)作为日志条目存储,并用前述机制复制该条目。某服务器一旦将新配置条目加入其日志,就将其用于之后所有决策(服务器始终使用其日志中最新配置,不论该条目是否已提交)。这意味着 leader 将用 C_old,new 的规则判断 C_old,new 的日志条目何时被提交。若 leader 崩溃,新 leader 可能在 C_old 或 C_old,new 下选出,取决于获胜 candidate 是否已收到 C_old,new。无论如何,此期间 C_new 不能单独做决策。
+
+一旦 C_old,new 被提交,C_old 与 C_new 都不能在未经对方同意下做决策,且 Leader Completeness Property 保证只有带有 C_old,new 日志条目的服务器能被选为 leader。此时 leader 可以安全地创建描述 C_new 的日志条目并复制到集群。同样,该配置在每台服务器看到时即生效。当新配置按 C_new 的规则被提交后,旧配置不再相关,不在新配置中的服务器可被关闭。如图 11,不存在 C_old 与 C_new 能同时独立做决策的时刻;这保证了安全。
+
+重新配置还有三个问题需要处理。第一,新服务器最初可能不存储任何日志条目。若在此状态下加入集群,它们可能需要很长时间才能赶上,期间可能无法提交新日志条目。为避免可用性缺口,Raft 在配置变更前增加一个阶段,新服务器以无投票权成员身份加入集群(leader 向它们复制日志条目,但不计入多数)。一旦新服务器赶上集群其余部分,即可按上述进行重新配置。
+
+第二,集群 leader 可能不在新配置中。此时 leader 在提交 C_new 日志条目后卸任(恢复为 follower)。这意味着会有一段时间(在提交 C_new 期间)leader 在管理一个不包含自己的集群;它复制日志条目但不把自己算入多数。Leader 交接在 C_new 被提交时发生,因为这是新配置能独立运作的最早时刻(从 C_new 中总能选出 leader)。在此之前,可能只有 C_old 中的服务器能被选为 leader。
+
+第三,被移除的服务器(不在 C_new 中的)可能干扰集群。这些服务器收不到心跳,会超时并发起新选举,随后发送带新 term 的 RequestVote RPC,导致当前 leader 恢复为 follower。最终会选出新 leader,但被移除的服务器会再次超时,过程重复,导致可用性变差。为防止此问题,服务器在认为当前存在 leader 时忽略 RequestVote RPC。具体地,若某服务器在收到当前 leader 消息后的最小选举超时内收到 RequestVote RPC,不更新其 term 也不授予投票。这不影响正常选举,因为每台服务器在发起选举前至少等待最小选举超时。但这有助于避免被移除服务器的干扰:若 leader 能向集群发送心跳,就不会被更大的 term 罢免。
+
+## 7 日志压缩
+
+Raft 的日志在正常运行中会增长以容纳更多客户端请求,但在实用系统中不能无限增长。随着日志变长,占用更多空间且回放更耗时,最终会在没有丢弃日志中积累的过时信息的机制时导致可用性问题。
+
+快照(snapshotting)是最简单的压缩方式。在快照中,将整个当前系统状态写入稳定存储上的快照,然后丢弃该点之前的全部日志。Chubby 与 ZooKeeper 使用快照,本节余下部分描述 Raft 中的快照。
+
+增量压缩方式如 log cleaning [36] 与 log-structured merge trees [30, 5] 也可行。它们每次只处理一部分数据,使压缩负载随时间更均匀分布。它们先选择积累了大量已删除与覆盖对象的数据区域,将该区域中的存活对象更紧凑地重写并释放该区域。与快照相比,这需要大量额外机制与复杂度;快照通过始终针对整个数据集操作来简化问题。Log cleaning 需要对 Raft 做修改,而 state machine 可用与快照相同的接口实现 LSM tree。
+
+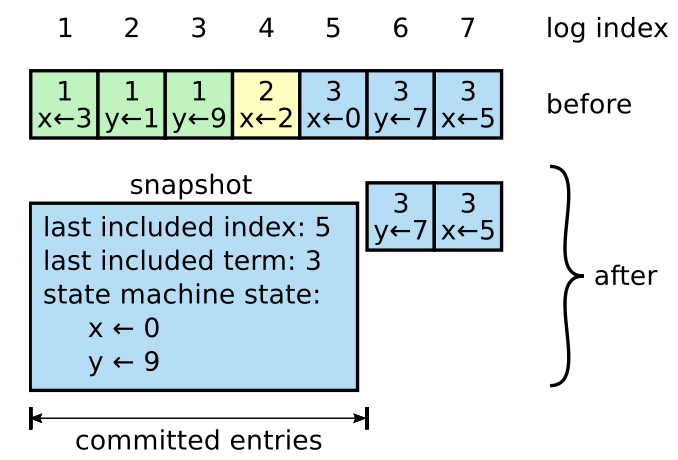
+
+**图 12:** 某服务器用新快照替换其日志中已提交的条目(index 1 到 5),快照仅存储当前状态(本例中为变量 x 和 y)。快照的 last included index 与 term 用于将快照定位于条目 6 之前的日志中。
+
+图 12 展示了 Raft 中快照的基本思路。每台服务器独立制作快照,仅覆盖其日志中已提交的条目。主要工作由 state machine 将其当前状态写入快照完成。Raft 还在快照中包含少量元数据:last included index 是快照所替换的日志中最后一条的 index(即 state machine 已应用的最后一条),last included term 是该条目的 term。这些被保留以支持快照之后第一条日志条目的 AppendEntries 一致性检查,因为该条目需要前一条的 log index 与 term。为支持集群成员变更(第 6 节),快照还包含截至 last included index 的日志中的最新配置。服务器完成快照写入后,可删除 last included index 及之前的所有日志条目以及任何更早的快照。
+
+尽管服务器通常独立制作快照,leader 偶尔需要向落后的 follower 发送快照。当 leader 已丢弃需要发给某 follower 的下一条日志条目时会发生这种情况。Leader 使用名为 InstallSnapshot 的新 RPC 向落后过多的 follower 发送快照;见图 13。Follower 收到该 RPC 的快照后,必须决定如何处理其现有日志条目。通常快照会包含接收方日志中尚未有的新信息,此时 follower 丢弃其全部日志;它们都被快照取代,且可能含有与快照冲突的未提交条目。若 follower 收到描述其日志前缀的快照(因重传或错误),则删除快照覆盖的日志条目,但快照之后的条目仍然有效且必须保留。
+
+> InstallSnapshot RPC
+>
+>
+> *由 leader 调用以向 follower 发送快照的分片。*
+>
+> *Leader 始终按序发送分片。*
+>
+>
+> **参数:**
+>
+> `term`: leader 的 term
+>
+> `leaderId`: 便于 follower 将客户端重定向到 leader
+>
+> `lastIncludedIndex`: 快照替换的直至并包含该 index 的所有条目
+>
+> `lastIncludedTerm`: lastIncludedIndex 的 term
+>
+> `offset`: 分片在快照文件中的字节偏移
+>
+> `data[]`: 从 offset 开始的快照分片原始字节
+>
+> `done`: 若此为最后一块则为 true
+>
+>
+> **返回:**
+>
+> `term`: currentTerm,供 leader 更新自身
+>
+>
+> **接收者实现:**
+>
+> 1. 若 term < currentTerm 则立即回复
+>
+> 2. 若是第一块(offset 为 0)则创建新快照文件
+>
+> 3. 在给定 offset 处将 data 写入快照文件
+>
+> 4. 若 done 为 false 则回复并等待更多 data 分片
+>
+> 5. 保存快照文件,丢弃任何 index 更小的已有或部分快照
+>
+> 6. 若已有日志条目与快照的 last included 条目 index 和 term 相同,保留其后的日志条目并回复
+>
+> 7. 丢弃整个日志
+>
+> 8. 用快照内容重置 state machine(并加载快照的集群配置)
+>
+
+**图 13:** InstallSnapshot RPC 摘要。快照被分成块传输;每块都给 follower 一个存活的信号,使其能重置选举定时器。
+
+这种快照方式偏离了 Raft 的强 leader 原则,因为 follower 可在 leader 不知情的情况下制作快照。但我们认为这种偏离是合理的。Leader 有助于在达成共识时避免冲突决策,而快照时共识已经达成,故没有决策冲突。数据仍只从 leader 流向 follower,只是 follower 现在可以重组其数据。
+
+还有两个影响快照性能的问题。第一,服务器必须决定何时制作快照。若过于频繁会浪费磁盘带宽与能耗;若过于稀疏则可能耗尽存储并在重启时增加回放日志所需时间。一种简单策略是当日志达到固定字节大小时制作快照。若该大小设得比预期快照大小大不少,快照的磁盘带宽开销会较小。第二,写快照可能耗时较长,我们不希望这延迟正常操作。解决方法是使用 copy-on-write 技术,使新更新能在不影响正在写入的快照的情况下被接受。例如,用函数式数据结构实现的 state machine 天然支持这一点。也可使用操作系统的 copy-on-write 支持(如 Linux 的 fork)为整个 state machine 创建内存快照(我们的实现采用此方式)。
+
+## 8 客户端交互
+
+本节描述客户端如何与 Raft 交互,包括客户端如何发现集群 leader 以及 Raft 如何支持可线性化语义 [10]。这些问题适用于所有基于共识的系统,Raft 的方案与其他系统类似。
+
+Raft 的客户端将所有请求发往 leader。客户端首次启动时连接到随机选中的服务器。若首选不是 leader,该服务器会拒绝请求并提供其最近得知的 leader 信息(AppendEntries 请求包含 leader 的网络地址)。若 leader 崩溃,客户端请求会超时;客户端随后随机选择服务器重试。
+
+我们对 Raft 的目标是实现可线性化语义(每个操作在其调用与响应之间的某时刻看起来被瞬时、恰好执行一次)。但就目前描述而言,Raft 可能多次执行同一 command:例如若 leader 在提交日志条目后、响应客户端前崩溃,客户端会向新 leader 重试该 command,导致其被再次执行。解决方法是让客户端为每条 command 分配唯一序列号。然后 state machine 记录每个客户端已处理的最新序列号及对应响应。若收到序列号已执行过的 command,立即响应而不重新执行。
+
+只读操作可以不写日志处理。但若没有额外措施,可能返回过期数据,因为响应请求的 leader 可能已被其不知情的新 leader 取代。可线性化读不能返回过期数据,Raft 需要两条额外预防措施在不写日志的情况下保证这一点。第一,leader 必须掌握哪些条目已提交的最新信息。Leader Completeness Property 保证 leader 拥有所有已提交条目,但在其 term 开始时可能不知道是哪些。要弄清这一点,需要提交其 term 的一条条目。Raft 的做法是让每个 leader 在 term 开始时向日志提交一条空白 no-op 条目。第二,leader 在处理只读请求前必须检查自己是否已被罢免(若已选出更新的 leader,其信息可能已过期)。Raft 的做法是让 leader 在响应只读请求前与集群多数交换心跳。 Alternatively,leader 可依赖心跳机制提供某种 lease [9],但这会依赖时间假设来保证安全(假定有界时钟偏差)。
+
+## 9 实现与评估
+
+我们将 Raft 实现为 RAMCloud [33] 的复制 state machine 的一部分,用于存储配置信息并协助 RAMCloud coordinator 的故障转移。Raft 实现约 2000 行 C++ 代码,不含测试、注释与空行。源代码可公开获取 [23]。另有约 25 个基于本文草稿、处于不同开发阶段的独立第三方开源实现 [34]。多家公司也在部署基于 Raft 的系统 [34]。
+
+本节其余部分从可理解性、正确性与性能三方面评估 Raft。
+
+### 9.1 可理解性
+
+为衡量 Raft 相对 Paxos 的可理解性,我们使用斯坦福大学高级操作系统课程与加州大学伯克利分校分布式计算课程的高年级本科生与研究生进行了实验。我们录制了 Raft 与 Paxos 的视频讲座并制作了对应测验。Raft 讲座覆盖本文除日志压缩外的内容;Paxos 讲座覆盖了构建等价复制 state machine 所需的材料,包括 single-decree Paxos、multi-decree Paxos、重新配置以及实践中需要的若干优化(如 leader 选举)。测验既考察对算法的基本理解,也要求学生推理边界情况。每名学生观看一个视频、参加对应测验,再观看第二个视频、参加第二个测验。约一半参与者先做 Paxos 部分、另一半先做 Raft 部分,以兼顾个体差异与先做部分带来的经验。我们比较了参与者在两次测验上的得分,以判断是否对 Raft 表现更好。
+
+我们尽量使 Paxos 与 Raft 的对比公平。实验在两方面有利于 Paxos:43 名参与者中有 15 人报告有 Paxos 先验经验,且 Paxos 视频比 Raft 视频长 14%。如表 1 所示,我们采取了措施缓解潜在偏差来源。所有材料可供审阅 [28, 31]。
+
+平均而言,参与者在 Raft 测验上比 Paxos 测验高 4.9 分(满分 60,Raft 平均 25.7,Paxos 平均 20.8);图 14 展示了个人得分。配对 t 检验表明,在 95% 置信度下,Raft 得分的真实分布均值至少比 Paxos 高 2.5 分。
+
+我们还建立了线性回归模型,基于三个因素预测新学生的测验得分:参加哪个测验、Paxos 先验经验程度、学习算法的顺序。模型预测测验选择会产生有利于 Raft 的 12.5 分差异。这显著高于观测到的 4.9 分,因为许多学生有 Paxos 先验经验,这对 Paxos 帮助较大、对 Raft 略小。有趣的是,模型还预测先参加 Paxos 测验的人在 Raft 上得分低 6.3 分;尽管原因不明,这在统计上似乎显著。
+
+我们还在测验后调查了参与者认为哪种算法更容易实现或解释;结果见图 15。绝大多数参与者认为 Raft 更容易实现和解释(41 人中有 33 人分别对两个问题如此回答)。但这些自我报告可能不如测验得分可靠,且参与者可能因知晓我们“Raft 更易理解”的假设而产生偏差。Raft 用户研究的详细讨论见 [31]。
+
+
+
+**图 14:** 43 名参与者在 Raft 与 Paxos 测验上表现的散点图。对角线上方(33 人)表示 Raft 得分更高的参与者。
+
+
+
+**图 15:** 使用 5 点量表,参与者被问及(左)哪种算法在实现一个正确、高效的系统时更容易实现,(右)哪种更容易向 CS 研究生解释。
+
+### 9.2 正确性
+
+我们为第 5 节描述的共识机制开发了形式化规范与安全性证明。形式化规范 [31] 使用 TLA+ 规范语言 [17] 将图 2 中的信息完全精确化。其约 400 行,作为证明的对象。对任何实现 Raft 的人也有独立价值。我们使用 TLA 证明系统 [7] 机械化证明了 Log Completeness Property。但该证明依赖未经机械化检查的不变量(例如我们未证明规范的类型安全)。此外,我们撰写了 State Machine Safety 的非形式证明 [31],其是完整的(仅依赖规范)且相对精确(约 3500 词)。
+
+**表 1:** 研究中可能对 Paxos 不利的顾虑、为缓解每项所采取的措施,以及可审阅的补充材料。
+
+| 顾虑 | 缓解偏差的措施 | 可审阅材料 [28, 31] |
+|--------|-----------------------------|------------------------------|
+| 讲座质量相当 | 同一讲师。Paxos 讲座基于并改进多所大学使用的现有材料。Paxos 讲座长 14%。 | videos |
+| 测验难度相当 | 按难度分组并在两套试卷间配对题目。 | quizzes |
+| 评分公平 | 使用评分标准。随机顺序评分,两套测验交替。 | rubric |
+
+### 9.3 性能
+
+Raft 的性能与 Paxos 等共识算法相当。最重要的性能场景是已确立的 leader 在复制新日志条目时。Raft 以最少的消息数实现这一点(从 leader 到半数集群的单次往返)。也可进一步优化 Raft 性能,例如它容易支持批处理与流水线以提高吞吐、降低延迟。文献中针对其他算法提出了多种优化,其中许多可应用于 Raft,我们留作未来工作。
+
+我们使用 Raft 实现测量了其 leader 选举算法的性能,并回答两个问题:第一,选举过程是否快速收敛?第二,leader 崩溃后能达到的最小停机时间是多少?为测量 leader 选举,我们反复使五台服务器集群的 leader 崩溃,并计时检测崩溃与选出新 leader 所需时间(见图 16)。图 16 上图表明选举超时中少量随机化就足以避免选举中的选票分散。在没有随机性时,我们的测试中 leader 选举持续超过 10 秒,因多次选票分散。仅增加 5ms 随机性就有显著帮助,中位停机时间 287ms。更多随机性改善最坏情况:50ms 随机性时,1000 次试验的最坏完成时间为 513ms。图 16 下图表明可通过减小选举超时来减少停机时间。在 12–24ms 选举超时下,平均仅需 35ms 即可选出 leader(最长一次 152ms)。但将超时降得过低会违反 Raft 的时间要求:leader 难以在其他服务器发起新选举前广播心跳,可能导致不必要的 leader 更替并降低整体可用性。我们建议使用保守的选举超时如 150–300ms;此类超时不太会引起不必要的 leader 更替,仍能提供良好可用性。
+
+
+
+**图 16:** 检测并替换崩溃 leader 所需时间。上图变化选举超时中的随机量,下图缩放最小选举超时。每条线代表 1000 次试验(“150–150ms”为 100 次),对应一种选举超时选择;例如“150–155ms”表示选举超时在 150ms 与 155ms 间均匀随机选择。测量在五台服务器、广播时间约 15ms 的集群上进行。九台服务器集群结果类似。
+
+## 10 相关工作
+
+有大量与共识算法相关的文献,多属以下类别之一:
+
+- Lamport 对 Paxos 的原始描述 [15],以及用更清晰方式解释的尝试 [16, 20, 21]。
+- 对 Paxos 的细化,填补缺失细节并修改算法以为实现提供更好基础 [26, 39, 13]。
+- 实现共识算法的系统,如 Chubby [2, 4]、ZooKeeper [11, 12]、Spanner [6]。Chubby 与 Spanner 的算法未详细公开,尽管二者均称基于 Paxos。ZooKeeper 的算法公开较详细,但与 Paxos 差异很大。
+- 可应用于 Paxos 的性能优化 [18, 19, 3, 25, 1, 27]。
+- Oki 与 Liskov 的 Viewstamped Replication (VR),与 Paxos 大约同时发展的另一种共识思路。原始描述 [29] 与分布式事务协议交织,但核心共识协议在近期更新 [22] 中已分离。VR 采用与 Raft 有许多相似之处的基于 leader 的方式。
+
+Raft 与 Paxos 的最大区别在于 Raft 的强领导:Raft 将 leader 选举作为共识协议的核心部分,并尽可能将功能集中在 leader。这得到更简单、更易理解的算法。例如在 Paxos 中,leader 选举与基本共识协议正交:仅作为性能优化,并非达成共识所必需。但这带来额外机制:Paxos 既有基本共识的两阶段协议,又有独立的 leader 选举机制。相比之下,Raft 将 leader 选举直接纳入共识算法并作为共识两阶段中的第一阶段,机制少于 Paxos。
+
+与 Raft 一样,VR 与 ZooKeeper 也是基于 leader 的,因此共享 Raft 相对 Paxos 的许多优势。但 Raft 的机制少于 VR 或 ZooKeeper,因为它最小化非 leader 的功能。例如 Raft 中日志条目只沿一个方向流动:在 AppendEntries RPC 中从 leader 向外。VR 中日志条目双向流动(leader 在选举过程中可接收日志条目),带来额外机制与复杂度。ZooKeeper 的公开描述也在与 leader 之间双向传输日志条目,但实现显然更接近 Raft [35]。
+
+Raft 的消息类型少于我们所知的任何其他基于共识的日志复制算法。例如我们统计了 VR 与 ZooKeeper 用于基本共识与成员变更的消息类型(排除日志压缩与客户端交互,因它们与算法几乎独立)。VR 与 ZooKeeper 各定义 10 种消息类型,而 Raft 仅有 4 种(两种 RPC 请求及其响应)。Raft 的消息略比其它算法密集,但总体上更简单。
+
+Raft 的强领导方式简化了算法,但排除了部分性能优化。例如 Egalitarian Paxos (EPaxos) 在某些条件下能以无 leader 方式获得更高性能 [27]。EPaxos 利用 state machine command 的可交换性。只要与某 command 并发提出的其他 command 与之可交换,任意服务器只需一轮通信即可提交该 command。但若并发提出的 command 彼此不可交换,EPaxos 需要额外一轮通信。因任意服务器都可提交 command,EPaxos 在服务器间负载均衡良好,在 WAN 环境下能达到比 Raft 更低的延迟,但显著增加了 Paxos 的复杂度。
+
+其他工作中提出或实现了多种集群成员变更方式,包括 Lamport 的原始提议 [15]、VR [22]、SMART [24]。我们为 Raft 选择联合共识是因为它利用共识协议的其余部分,成员变更几乎不需要额外机制。Lamport 的基于 α 的方式不适用于 Raft,因其假定无需 leader 即可达成共识。与 VR 和 SMART 相比,Raft 的重新配置算法的优势是成员变更可在不限制正常请求处理的情况下进行;相反,VR 在配置变更期间停止所有正常处理,SMART 对未完成请求数量施加类 α 限制。Raft 的方式也比 VR 或 SMART 增加更少机制。
+
+## 11 结论
+
+算法常以正确性、效率和/或简洁为主要目标。尽管这些目标都值得追求,我们相信可理解性同样重要。在开发者将算法落实为实用实现之前,其他目标都无法实现,而实现必然会在已发表形式基础上偏离与扩展。除非开发者对算法有深入理解并能形成直觉,否则很难在实现中保留其理想性质。
+
+本文针对分布式共识问题:被广泛接受却难以理解的 Paxos 多年来一直困扰学生与开发者。我们提出了一种新算法 Raft,并表明其比 Paxos 更易理解。我们也相信 Raft 为系统构建提供了更好基础。以可理解性为主要设计目标改变了我们设计 Raft 的方式;随着设计推进,我们反复运用少数几种技术,如问题分解与状态空间简化。这些技术不仅提高了 Raft 的可理解性,也使我们更容易确信其正确性。
+
+## 12 致谢
+
+若无 Ali Ghodsi、David Mazières 以及伯克利 CS 294-91 与斯坦福 CS 240 学生的支持,用户研究无法完成。Scott Klemmer 帮助我们设计用户研究,Nelson Ray 在统计分析上提供建议。用户研究中的 Paxos 幻灯片大量借鉴了 Lorenzo Alvisi 最初制作的讲稿。特别感谢 David Mazières 与 Ezra Hoch 发现 Raft 中的微妙错误。许多人就论文与用户研究材料提供了有益反馈,包括 Ed Bugnion, Michael Chan, Hugues Evrard, Daniel Giffin, Arjun Gopalan, Jon Howell, Vimalkumar Jeyakumar, Ankita Kejriwal, Aleksandar Kracun, Amit Levy, Joel Martin, Satoshi Matsushita, Oleg Pesok, David Ramos, Robbert van Renesse, Mendel Rosenblum, Nicolas Schiper, Deian Stefan, Andrew Stone, Ryan Stutsman, David Terei, Stephen Yang, Matei Zaharia,24 位匿名会议审稿人(含重复),以及我们的 shepherd Eddie Kohler。Werner Vogels 在推特上转发了早期草稿链接,为 Raft 带来了大量关注。本工作由 Gigascale Systems Research Center 与 Multiscale Systems Center(半导体研究公司 Focus Center Research Program 资助的六个研究中心中的两个)、STARnet(MARCO 与 DARPA 资助的半导体研究公司项目)、美国国家科学基金会(资助号 0963859)以及 Facebook、Google、Mellanox、NEC、NetApp、SAP、Samsung 的资助支持。Diego Ongaro 受 The Junglee Corporation Stanford Graduate Fellowship 资助。
+
+## 参考文献
+
+[1] BOLOSKY, W. J., BRADSHAW, D., HAAGENS, R. B., KUSTERS, N. P., AND LI, P. Paxos replicated state machines as the basis of a high-performance data store. In Proc. NSDI'11, USENIX Conference on Networked Systems Design and Implementation (2011), USENIX, pp. 141–154.
+
+[2] BURROWS, M. The Chubby lock service for loosely-coupled distributed systems. In Proc. OSDI'06, Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 335–350.
+
+[3] CAMARGOS, L. J., SCHMIDT, R. M., AND PEDONE, F. Multicoordinated Paxos. In Proc. PODC'07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 316–317.
+
+[4] CHANDRA, T. D., GRIESEMER, R., AND REDSTONE, J. Paxos made live: an engineering perspective. In Proc. PODC'07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 398–407.
+
+[5] CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W. C., WALLACH, D. A., BURROWS, M., CHANDRA, T., FIKES, A., AND GRUBER, R. E. Bigtable: a distributed storage system for structured data. In Proc. OSDI'06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 205–218.
+
+[6] CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV, A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google's globally-distributed database. In Proc. OSDI'12, USENIX Conference on Operating Systems Design and Implementation (2012), USENIX, pp. 251–264.
+
+[7] COUSINEAU, D., DOLIGEZ, D., LAMPORT, L., MERZ, S., RICKETTS, D., AND VANZETTO, H. TLA+ proofs. In Proc. FM'12, Symposium on Formal Methods (2012), D. Giannakopoulou and D. M´ery, Eds., vol. 7436 of Lecture Notes in Computer Science, Springer, pp. 147–154.
+
+[8] GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google file system. In Proc. SOSP'03, ACM Symposium on Operating Systems Principles (2003), ACM, pp. 29–43.
+
+[9] GRAY, C., AND CHERITON, D. Leases: An efficient fault-tolerant mechanism for distributed file cache consistency. In Proceedings of the 12th ACM Symposium on Operating Systems Principles (1989), pp. 202–210.
+
+[10] HERLIHY, M. P., AND WING, J. M. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems 12 (July 1990), 463–492.
+
+[11] HUNT, P., KONAR, M., JUNQUEIRA, F. P., AND REED, B. ZooKeeper: wait-free coordination for internet-scale systems. In Proc ATC'10, USENIX Annual Technical Conference (2010), USENIX, pp. 145–158.
+
+[12] JUNQUEIRA, F. P., REED, B. C., AND SERAFINI, M. Zab: High-performance broadcast for primary-backup systems. In Proc. DSN'11, IEEE/IFIP Int'l Conf. on Dependable Systems & Networks (2011), IEEE Computer Society, pp. 245–256.
+
+[13] KIRSCH, J., AND AMIR, Y. Paxos for system builders. Tech. Rep. CNDS-2008-2, Johns Hopkins University, 2008.
+
+[14] LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM 21, 7 (July 1978), 558–565.
+
+[15] LAMPORT, L. The part-time parliament. ACM Transactions on Computer Systems 16, 2 (May 1998), 133–169.
+
+[16] LAMPORT, L. Paxos made simple. ACM SIGACT News 32, 4 (Dec. 2001), 18–25.
+
+[17] LAMPORT, L. Specifying Systems, The TLA+ Language and Tools for Hardware and Software Engineers. Addison-Wesley, 2002.
+
+[18] LAMPORT, L. Generalized consensus and Paxos. Tech. Rep. MSR-TR-2005-33, Microsoft Research, 2005.
+
+[19] LAMPORT, L. Fast paxos. Distributed Computing 19, 2 (2006), 79–103.
+
+[20] LAMPSON, B. W. How to build a highly available system using consensus. In Distributed Algorithms, O. Babaoğlu and K. Marzullo, Eds. Springer-Verlag, 1996, pp. 1–17.
+
+[21] LAMPSON, B. W. The ABCD's of Paxos. In Proc. PODC'01, ACM Symposium on Principles of Distributed Computing (2001), ACM, pp. 13–13.
+
+[22] LISKOV, B., AND COWLING, J. Viewstamped replication revisited. Tech. Rep. MIT-CSAIL-TR-2012-021, MIT, July 2012.
+
+[23] LogCabin source code. http://github.com/logcabin/logcabin.
+
+[24] LORCH, J. R., ADYA, A., BOLOSKY, W. J., CHAIKEN, R., DOUCEUR, J. R., AND HOWELL, J. The SMART way to migrate replicated stateful services. In Proc. EuroSys'06, ACM SIGOPS/EuroSys European Conference on Computer Systems (2006), ACM, pp. 103–115.
+
+[25] MAO, Y., JUNQUEIRA, F. P., AND MARZULLO, K. Mencius: building efficient replicated state machines for WANs. In Proc. OSDI'08, USENIX Conference on Operating Systems Design and Implementation (2008), USENIX, pp. 369–384.
+
+[26] MAZIÈRES, D. Paxos made practical. http://www.scs.stanford.edu/~dm/home/papers/paxos.pdf, Jan. 2007.
+
+[27] MORARU, I., ANDERSEN, D. G., AND KAMINSKY, M. There is more consensus in egalitarian parliaments. In Proc. SOSP'13, ACM Symposium on Operating System Principles (2013), ACM.
+
+[28] Raft user study. http://ramcloud.stanford.edu/~ongaro/userstudy/.
+
+[29] OKI, B. M., AND LISKOV, B. H. Viewstamped replication: A new primary copy method to support highly-available distributed systems. In Proc. PODC'88, ACM Symposium on Principles of Distributed Computing (1988), ACM, pp. 8–17.
+
+[30] O'NEIL, P., CHENG, E., GAWLICK, D., AND ONEIL, E. The log-structured merge-tree (LSM-tree). Acta Informatica 33, 4 (1996), 351–385.
+
+[31] ONGARO, D. Consensus: Bridging Theory and Practice. PhD thesis, Stanford University, 2014 (work in progress). http://ramcloud.stanford.edu/~ongaro/thesis.pdf.
+
+[32] ONGARO, D., AND OUSTERHOUT, J. In search of an understandable consensus algorithm. In Proc ATC'14, USENIX Annual Technical Conference (2014), USENIX.
+
+[33] OUSTERHOUT, J., AGRAWAL, P., ERICKSON, D., KOZYRAKIS, C., LEVERICH, J., MAZIÈRES, D., MITRA, S., NARAYANAN, A., ONGARO, D., PARULKAR, G., ROSENBLUM, M., RUMBLE, S. M., STRATMANN, E., AND STUTSMAN, R. The case for RAMCloud. Communications of the ACM 54 (July 2011), 121–130.
+
+[34] Raft consensus algorithm website. http://raftconsensus.github.io.
+
+[35] REED, B. Personal communications, May 17, 2013.
+
+[36] ROSENBLUM, M., AND OUSTERHOUT, J. K. The design and implementation of a log-structured file system. ACM Trans. Comput. Syst. 10 (February 1992), 26–52.
+
+[37] SCHNEIDER, F. B. Implementing fault-tolerant services using the state machine approach: a tutorial. ACM Computing Surveys 22, 4 (Dec. 1990), 299–319.
+
+[38] SHVACHKO, K., KUANG, H., RADIA, S., AND CHANSLER, R. The Hadoop distributed file system. In Proc. MSST'10, Symposium on Mass Storage Systems and Technologies (2010), IEEE Computer Society, pp. 1–10.
+
+[39] VAN RENESSE, R. Paxos made moderately complex. Tech. rep., Cornell University, 2012.
diff --git a/docs/papers/raft-extended.md b/docs/papers/raft-extended.md
new file mode 100644
index 0000000..44abd2a
--- /dev/null
+++ b/docs/papers/raft-extended.md
@@ -0,0 +1,666 @@
+# In Search of an Understandable Consensus Algorithm (Extended Version)
+
+**Diego Ongaro and John Ousterhout**
+
+Stanford University
+
+*This tech report is an extended version of [32]; additional material is noted with a gray bar in the margin. Published May 20, 2014.*
+
+## Abstract
+
+Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos; this makes Raft more understandable than Paxos and also provides a better foundation for building practical systems. In order to enhance understandability, Raft separates the key elements of consensus, such as leader election, log replication, and safety, and it enforces a stronger degree of coherency to reduce the number of states that must be considered. Results from a user study demonstrate that Raft is easier for students to learn than Paxos. Raft also includes a new mechanism for changing the cluster membership, which uses overlapping majorities to guarantee safety.
+
+## 1 Introduction
+
+Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members. Because of this, they play a key role in building reliable large-scale software systems. Paxos [15, 16] has dominated the discussion of consensus algorithms over the last decade: most implementations of consensus are based on Paxos or influenced by it, and Paxos has become the primary vehicle used to teach students about consensus.
+
+Unfortunately, Paxos is quite difficult to understand, in spite of numerous attempts to make it more approachable. Furthermore, its architecture requires complex changes to support practical systems. As a result, both system builders and students struggle with Paxos.
+
+After struggling with Paxos ourselves, we set out to find a new consensus algorithm that could provide a better foundation for system building and education. Our approach was unusual in that our primary goal was understandability: could we define a consensus algorithm for practical systems and describe it in a way that is significantly easier to learn than Paxos? Furthermore, we wanted the algorithm to facilitate the development of intuitions that are essential for system builders. It was important not just for the algorithm to work, but for it to be obvious why it works.
+
+The result of this work is a consensus algorithm called Raft. In designing Raft we applied specific techniques to improve understandability, including decomposition (Raft separates leader election, log replication, and safety) and state space reduction (relative to Paxos, Raft reduces the degree of nondeterminism and the ways servers can be inconsistent with each other). A user study with 43 students at two universities shows that Raft is significantly easier to understand than Paxos: after learning both algorithms, 33 of these students were able to answer questions about Raft better than questions about Paxos.
+
+Raft is similar in many ways to existing consensus algorithms (most notably, Oki and Liskov's Viewstamped Replication [29, 22]), but it has several novel features:
+
+- **Strong leader:** Raft uses a stronger form of leadership than other consensus algorithms. For example, log entries only flow from the leader to other servers. This simplifies the management of the replicated log and makes Raft easier to understand.
+- **Leader election:** Raft uses randomized timers to elect leaders. This adds only a small amount of mechanism to the heartbeats already required for any consensus algorithm, while resolving conflicts simply and rapidly.
+- **Membership changes:** Raft's mechanism for changing the set of servers in the cluster uses a new joint consensus approach where the majorities of two different configurations overlap during transitions. This allows the cluster to continue operating normally during configuration changes.
+
+We believe that Raft is superior to Paxos and other consensus algorithms, both for educational purposes and as a foundation for implementation. It is simpler and more understandable than other algorithms; it is described completely enough to meet the needs of a practical system; it has several open-source implementations and is used by several companies; its safety properties have been formally specified and proven; and its efficiency is comparable to other algorithms.
+
+The remainder of the paper introduces the replicated state machine problem (Section 2), discusses the strengths and weaknesses of Paxos (Section 3), describes our general approach to understandability (Section 4), presents the Raft consensus algorithm (Sections 5–8), evaluates Raft (Section 9), and discusses related work (Section 10).
+
+## 2 Replicated state machines
+
+Consensus algorithms typically arise in the context of replicated state machines [37]. In this approach, state machines on a collection of servers compute identical copies of the same state and can continue operating even if some of the servers are down. Replicated state machines are used to solve a variety of fault tolerance problems in distributed systems. For example, large-scale systems that have a single cluster leader, such as GFS [8], HDFS [38], and RAMCloud [33], typically use a separate replicated state machine to manage leader election and store configuration information that must survive leader crashes. Examples of replicated state machines include Chubby [2] and ZooKeeper [11].
+
+
+
+**Figure 1:** Replicated state machine architecture. The consensus algorithm manages a replicated log containing state machine commands from clients. The state machines process identical sequences of commands from the logs, so they produce the same outputs.
+
+Replicated state machines are typically implemented using a replicated log, as shown in Figure 1. Each server stores a log containing a series of commands, which its state machine executes in order. Each log contains the same commands in the same order, so each state machine processes the same sequence of commands. Since the state machines are deterministic, each computes the same state and the same sequence of outputs.
+
+Keeping the replicated log consistent is the job of the consensus algorithm. The consensus module on a server receives commands from clients and adds them to its log. It communicates with the consensus modules on other servers to ensure that every log eventually contains the same requests in the same order, even if some servers fail. Once commands are properly replicated, each server's state machine processes them in log order, and the outputs are returned to clients. As a result, the servers appear to form a single, highly reliable state machine.
+
+Consensus algorithms for practical systems typically have the following properties:
+
+- They ensure safety (never returning an incorrect result) under all non-Byzantine conditions, including network delays, partitions, and packet loss, duplication, and reordering.
+- They are fully functional (available) as long as any majority of the servers are operational and can communicate with each other and with clients. Thus, a typical cluster of five servers can tolerate the failure of any two servers. Servers are assumed to fail by stopping; they may later recover from state on stable storage and rejoin the cluster.
+- They do not depend on timing to ensure the consistency of the logs: faulty clocks and extreme message delays can, at worst, cause availability problems.
+- In the common case, a command can complete as soon as a majority of the cluster has responded to a single round of remote procedure calls; a minority of slow servers need not impact overall system performance.
+
+## 3 What's wrong with Paxos?
+
+Over the last ten years, Leslie Lamport's Paxos protocol [15] has become almost synonymous with consensus: it is the protocol most commonly taught in courses, and most implementations of consensus use it as a starting point. Paxos first defines a protocol capable of reaching agreement on a single decision, such as a single replicated log entry. We refer to this subset as single-decree Paxos. Paxos then combines multiple instances of this protocol to facilitate a series of decisions such as a log (multi-Paxos). Paxos ensures both safety and liveness, and it supports changes in cluster membership. Its correctness has been proven, and it is efficient in the normal case.
+
+Unfortunately, Paxos has two significant drawbacks.
+
+The first drawback is that Paxos is exceptionally difficult to understand. The full explanation [15] is notoriously opaque; few people succeed in understanding it, and only with great effort. As a result, there have been several attempts to explain Paxos in simpler terms [16, 20, 21]. These explanations focus on the single-decree subset, yet they are still challenging. In an informal survey of attendees at NSDI 2012, we found few people who were comfortable with Paxos, even among seasoned researchers. We struggled with Paxos ourselves; we were not able to understand the complete protocol until after reading several simplified explanations and designing our own alternative protocol, a process that took almost a year.
+
+We hypothesize that Paxos' opaqueness derives from its choice of the single-decree subset as its foundation. Single-decree Paxos is dense and subtle: it is divided into two stages that do not have simple intuitive explanations and cannot be understood independently. Because of this, it is difficult to develop intuitions about why the single-decree protocol works. The composition rules for multi-Paxos add significant additional complexity and subtlety. We believe that the overall problem of reaching consensus on multiple decisions (i.e., a log instead of a single entry) can be decomposed in other ways that are more direct and obvious.
+
+The second problem with Paxos is that it does not provide a good foundation for building practical implementations. One reason is that there is no widely agreed-upon algorithm for multi-Paxos. Lamport's descriptions are mostly about single-decree Paxos; he sketched possible approaches to multi-Paxos, but many details are missing. There have been several attempts to flesh out and optimize Paxos, such as [26], [39], and [13], but these differ from each other and from Lamport's sketches. Systems such as Chubby [4] have implemented Paxos-like algorithms, but in most cases their details have not been published.
+
+Furthermore, the Paxos architecture is a poor one for building practical systems; this is another consequence of the single-decree decomposition. For example, there is little benefit to choosing a collection of log entries independently and then melding them into a sequential log; this just adds complexity. It is simpler and more efficient to design a system around a log, where new entries are appended sequentially in a constrained order. Another problem is that Paxos uses a symmetric peer-to-peer approach at its core (though it eventually suggests a weak form of leadership as a performance optimization). This makes sense in a simplified world where only one decision will be made, but few practical systems use this approach. If a series of decisions must be made, it is simpler and faster to first elect a leader, then have the leader coordinate the decisions.
+
+As a result, practical systems bear little resemblance to Paxos. Each implementation begins with Paxos, discovers the difficulties in implementing it, and then develops a significantly different architecture. This is time-consuming and error-prone, and the difficulties of understanding Paxos exacerbate the problem. Paxos' formulation may be a good one for proving theorems about its correctness, but real implementations are so different from Paxos that the proofs have little value. The following comment from the Chubby implementers is typical:
+
+> There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. . . . the final system will be based on an unproven protocol [4].
+>
+
+Because of these problems, we concluded that Paxos does not provide a good foundation either for system building or for education. Given the importance of consensus in large-scale software systems, we decided to see if we could design an alternative consensus algorithm with better properties than Paxos. Raft is the result of that experiment.
+
+## 4 Designing for understandability
+
+We had several goals in designing Raft: it must provide a complete and practical foundation for system building, so that it significantly reduces the amount of design work required of developers; it must be safe under all conditions and available under typical operating conditions; and it must be efficient for common operations. But our most important goal—and most difficult challenge—was understandability. It must be possible for a large audience to understand the algorithm comfortably. In addition, it must be possible to develop intuitions about the algorithm, so that system builders can make the extensions that are inevitable in real-world implementations.
+
+There were numerous points in the design of Raft where we had to choose among alternative approaches. In these situations we evaluated the alternatives based on understandability: how hard is it to explain each alternative (for example, how complex is its state space, and does it have subtle implications?), and how easy will it be for a reader to completely understand the approach and its implications?
+
+We recognize that there is a high degree of subjectivity in such analysis; nonetheless, we used two techniques that are generally applicable. The first technique is the well-known approach of problem decomposition: wherever possible, we divided problems into separate pieces that could be solved, explained, and understood relatively independently. For example, in Raft we separated leader election, log replication, safety, and membership changes.
+
+Our second approach was to simplify the state space by reducing the number of states to consider, making the system more coherent and eliminating nondeterminism where possible. Specifically, logs are not allowed to have holes, and Raft limits the ways in which logs can become inconsistent with each other. Although in most cases we tried to eliminate nondeterminism, there are some situations where nondeterminism actually improves understandability. In particular, randomized approaches introduce nondeterminism, but they tend to reduce the state space by handling all possible choices in a similar fashion ("choose any; it doesn't matter"). We used randomization to simplify the Raft leader election algorithm.
+
+## 5 The Raft consensus algorithm
+
+Raft is an algorithm for managing a replicated log of the form described in Section 2. Figure 2 summarizes the algorithm in condensed form for reference, and Figure 3 lists key properties of the algorithm; the elements of these figures are discussed piecewise over the rest of this section.
+
+Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machines. Having a leader simplifies the management of the replicated log. For example, the leader can decide where to place new entries in the log without consulting other servers, and data flows in a simple fashion from the leader to other servers. A leader can fail or become disconnected from the other servers, in which case a new leader is elected.
+
+Given the leader approach, Raft decomposes the consensus problem into three relatively independent subproblems, which are discussed in the subsections that follow:
+
+- **Leader election:** a new leader must be chosen when an existing leader fails (Section 5.2).
+- **Log replication:** the leader must accept log entries from clients and replicate them across the cluster, forcing the other logs to agree with its own (Section 5.3).
+- **Safety:** the key safety property for Raft is the State Machine Safety Property in Figure 3: if any server has applied a particular log entry to its state machine, then no other server may apply a different command for the same log index. Section 5.4 describes how Raft ensures this property; the solution involves an additional restriction on the election mechanism described in Section 5.2.
+
+After presenting the consensus algorithm, this section discusses the issue of availability and the role of timing in the system.
+
+> **State**
+>
+>
+> **Persistent state on all servers**:
+>
+> *(Updated on stable storage before responding to RPCs)*
+>
+> `currentTerm`: latest term server has seen (initialized to 0 on first boot, increases monotonically)
+>
+> `votedFor`: candidateId that received vote in current term (or null if none)
+>
+> `log[]`: log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1)
+>
+>
+> **Volatile state on all servers:**
+>
+> `commit Index`: index of highest log entry known to be committed (initialized to 0, increases monotonically)
+>
+> `last Applied`: index of highest log entry applied to state machine (initialized to 0, increases monotonically)
+>
+>
+> **Volatile state on leaders:**
+>
+> *(Reinitialized after election)*
+>
+>
+> `nextIndex[]`: for each server, index of the next log entry to send to that server (initialized to leader last log index + 1)
+>
+> `matchIndex[]`: for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically)
+>
+
+> **AppendEntries RPC**
+>
+>
+> *Invoked by leader to replicate log entries (§5.3); also used as heartbeat (§5.2).*
+>
+>
+> **Arguments:**
+>
+> `term`: leader's term
+>
+> `leaderId`: so follower can redirect clients
+>
+> `prevLogIndex`: index of log entry immediately preceding new ones
+>
+> `prevLogTerm`: term of prevLogIndex entry
+>
+> `entries[]`: log entries to store (empty for heartbeat; may send more than one for efficiency)
+>
+> `leaderCommit`: leader's commitIndex
+>
+>
+> **Results:**
+>
+> `term`: currentTerm, for leader to update itself
+>
+> `success`: true if follower contained entry matching prevLogIndex and prevLogTerm
+>
+>
+> **Receiver implementation:**
+>
+> 1. Reply false if term < currentTerm (§5.1)
+>
+> 2. Reply false if log doesn't contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
+>
+> 3. If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
+>
+> 4. Append any new entries not already in the log
+>
+> 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
+>
+
+> **RequestVote RPC**
+>
+>
+> *Invoked by candidates to gather votes (§5.2).*
+>
+>
+> **Arguments:**
+>
+> `term`: candidate's term
+>
+> `candidateId`: candidate requesting vote
+>
+> `lastLogIndex`: index of candidate's last log entry (§5.4)
+>
+> `lastLogTerm`: term of candidate's last log entry (§5.4)
+>
+>
+> **Results:**
+>
+> `term`: currentTerm, for candidate to update itself
+>
+> `voteGranted`: true means candidate received vote
+>
+>
+> **Receiver implementation:**
+>
+> 1. Reply false if term < currentTerm (§5.1)
+>
+> 2. If votedFor is null or candidateId, and candidate's log is at least as up-to-date as receiver's log, grant vote (§5.2, §5.4)
+>
+
+> **Rules for Servers**
+>
+>
+> **All Servers:**
+>
+> - If commitIndex > lastApplied: increment lastApplied, apply log\[lastApplied] to state machine (§5.3)
+>
+> - If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
+>
+>
+> **Followers (§5.2):**
+>
+> - Respond to RPCs from candidates and leaders
+>
+> - If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
+>
+>
+> **Candidates (§5.2):**
+>
+> - On conversion to candidate, start election:
+>
+> - Increment currentTerm
+>
+> - Vote for self
+>
+> - Reset election timer
+>
+> - Send RequestVote RPCs to all other servers.
+>
+> - If votes received from majority of servers: become leader.
+>
+> - If AppendEntries RPC received from new leader: convert to follower
+>
+> - If election timeout elapses: start new election
+>
+>
+> **Leaders:**
+>
+> - Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server; repeat during idle periods to prevent election timeouts (§5.2)
+>
+> - If command received from client: append entry to local log, respond after entry applied to state machine (§5.3)
+>
+> - If last log index ≥ nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex
+>
+> - If successful: update nextIndex and matchIndex for follower (§5.3)
+>
+> - If AppendEntries fails because of log inconsistency: decrement nextIndex and retry (§5.3)
+>
+> - If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, and log\[N].term == currentTerm: set commitIndex = N (§5.3, §5.4).
+>
+
+**Figure 2:** A condensed summary of the Raft consensus algorithm (excluding membership changes and log compaction). The server behavior in the upper-left box is described as a set of rules that trigger independently and repeatedly. Section numbers such as §5.2 indicate where particular features are discussed. A formal specification [31] describes the algorithm more precisely.
+
+> **Election Safety:** at most one leader can be elected in a given term. §5.2
+>
+> **Leader Append-Only:** a leader never overwrites or deletes entries in its log; it only appends new entries. §5.3
+>
+> **Log Matching:** if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index. §5.3
+>
+> **Leader Completeness:** if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms. §5.4
+>
+> **State Machine Safety:** if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. §5.4.3
+>
+
+**Figure 3:** Raft guarantees that each of these properties is true at all times. The section numbers indicate where each property is discussed.
+
+### 5.1 Raft basics
+
+A Raft cluster contains several servers; five is a typical number, which allows the system to tolerate two failures. At any given time each server is in one of three states: leader, follower, or candidate. In normal operation there is exactly one leader and all of the other servers are followers. Followers are passive: they issue no requests on their own but simply respond to requests from leaders and candidates. The leader handles all client requests (if a client contacts a follower, the follower redirects it to the leader). The third state, candidate, is used to elect a new leader as described in Section 5.2. Figure 4 shows the states and their transitions.
+
+
+
+**Figure 4:** Server states. Followers only respond to requests from other servers. If a follower receives no communication, it becomes a candidate and initiates an election. A candidate that receives votes from a majority of the full cluster becomes the new leader. Leaders typically operate until they fail.
+
+
+
+**Figure 5:** Time is divided into terms, and each term begins with an election. After a successful election, a single leader manages the cluster until the end of the term. Some elections fail, in which case the term ends without choosing a leader. The transitions between terms may be observed at different times on different servers.
+
+Raft divides time into terms of arbitrary length, as shown in Figure 5. Terms are numbered with consecutive integers. Each term begins with an election, in which one or more candidates attempt to become leader as described in Section 5.2. If a candidate wins the election, then it serves as leader for the rest of the term. In some situations an election will result in a split vote. In this case the term will end with no leader; a new term (with a new election) will begin shortly. Raft ensures that there is at most one leader in a given term.
+
+Different servers may observe the transitions between terms at different times, and in some situations a server may not observe an election or even entire terms. Terms act as a logical clock [14] in Raft, and they allow servers to detect obsolete information such as stale leaders. Each server stores a current term number, which increases monotonically over time. Current terms are exchanged whenever servers communicate; if one server's current term is smaller than the other's, then it updates its current term to the larger value. If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state. If a server receives a request with a stale term number, it rejects the request.
+
+Raft servers communicate using remote procedure calls (RPCs), and the basic consensus algorithm requires only two types of RPCs. RequestVote RPCs are initiated by candidates during elections (Section 5.2), and AppendEntries RPCs are initiated by leaders to replicate log entries and to provide a form of heartbeat (Section 5.3). Section 7 adds a third RPC for transferring snapshots between servers. Servers retry RPCs if they do not receive a response in a timely manner, and they issue RPCs in parallel for best performance.
+
+### 5.2 Leader election
+
+Raft uses a heartbeat mechanism to trigger leader election. When servers start up, they begin as followers. A server remains in follower state as long as it receives valid RPCs from a leader or candidate. Leaders send periodic heartbeats (AppendEntries RPCs that carry no log entries) to all followers in order to maintain their authority. If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
+
+To begin an election, a follower increments its current term and transitions to candidate state. It then votes for itself and issues RequestVote RPCs in parallel to each of the other servers in the cluster. A candidate continues in this state until one of three things happens: (a) it wins the election, (b) another server establishes itself as leader, or (c) a period of time goes by with no winner.
+
+A candidate wins an election if it receives votes from a majority of the servers in the full cluster for the same term. Each server will vote for at most one candidate in a given term, on a first-come-first-served basis (note: Section 5.4 adds an additional restriction on votes). The majority rule ensures that at most one candidate can win the election for a particular term (the Election Safety Property in Figure 3). Once a candidate wins an election, it becomes leader. It then sends heartbeat messages to all of the other servers to establish its authority and prevent new elections.
+
+While waiting for votes, a candidate may receive an AppendEntries RPC from another server claiming to be leader. If the leader's term (included in its RPC) is at least as large as the candidate's current term, then the candidate recognizes the leader as legitimate and returns to follower state. If the term in the RPC is smaller than the candidate's current term, then the candidate rejects the RPC and continues in candidate state.
+
+The third possible outcome is that a candidate neither wins nor loses the election: if many followers become candidates at the same time, votes could be split so that no candidate obtains a majority. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of RequestVote RPCs. However, without extra measures split votes could repeat indefinitely.
+
+Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly. To prevent split votes in the first place, election timeouts are chosen randomly from a fixed interval (e.g., 150–300ms). This spreads out the servers so that in most cases only a single server will time out; it wins the election and sends heartbeats before any other servers time out. The same mechanism is used to handle split votes. Each candidate restarts its randomized election timeout at the start of an election, and it waits for that timeout to elapse before starting the next election; this reduces the likelihood of another split vote in the new election. Section 9.3 shows that this approach elects a leader rapidly.
+
+
+
+**Figure 6:** Logs are composed of entries, which are numbered sequentially. Each entry contains the term in which it was created (the number in each box) and a command for the state machine. An entry is considered committed if it is safe for that entry to be applied to state machines.
+
+Elections are an example of how understandability guided our choice between design alternatives. Initially we planned to use a ranking system: each candidate was assigned a unique rank, which was used to select between competing candidates. If a candidate discovered another candidate with higher rank, it would return to follower state so that the higher ranking candidate could more easily win the next election. We found that this approach created subtle issues around availability (a lower-ranked server might need to time out and become a candidate again if a higher-ranked server fails, but if it does so too soon, it can reset progress towards electing a leader). We made adjustments to the algorithm several times, but after each adjustment new corner cases appeared. Eventually we concluded that the randomized retry approach is more obvious and understandable.
+
+### 5.3 Log replication
+
+Once a leader has been elected, it begins servicing client requests. Each client request contains a command to be executed by the replicated state machines. The leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry. When the entry has been safely replicated (as described below), the leader applies the entry to its state machine and returns the result of that execution to the client. If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries RPCs indefinitely (even after it has responded to the client) until all followers eventually store all log entries.
+
+Logs are organized as shown in Figure 6. Each log entry stores a state machine command along with the term number when the entry was received by the leader. The term numbers in log entries are used to detect inconsistencies between logs and to ensure some of the properties in Figure 3. Each log entry also has an integer index identifying its position in the log.
+
+The leader decides when it is safe to apply a log entry to the state machines; such an entry is called committed. Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines. A log entry is committed once the leader that created the entry has replicated it on a majority of the servers (e.g., entry 7 in Figure 6). This also commits all preceding entries in the leader's log, including entries created by previous leaders. Section 5.4 discusses some subtleties when applying this rule after leader changes, and it also shows that this definition of commitment is safe. The leader keeps track of the highest index it knows to be committed, and it includes that index in future AppendEntries RPCs (including heartbeats) so that the other servers eventually find out. Once a follower learns that a log entry is committed, it applies the entry to its local state machine (in log order).
+
+We designed the Raft log mechanism to maintain a high level of coherency between the logs on different servers. Not only does this simplify the system's behavior and make it more predictable, but it is an important component of ensuring safety. Raft maintains the following properties, which together constitute the Log Matching Property in Figure 3:
+
+- If two entries in different logs have the same index and term, then they store the same command.
+- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
+
+The first property follows from the fact that a leader creates at most one entry with a given log index in a given term, and log entries never change their position in the log. The second property is guaranteed by a simple consistency check performed by AppendEntries. When sending an AppendEntries RPC, the leader includes the index and term of the entry in its log that immediately precedes the new entries. If the follower does not find an entry in its log with the same index and term, then it refuses the new entries. The consistency check acts as an induction step: the initial empty state of the logs satisfies the Log Matching Property, and the consistency check preserves the Log Matching Property whenever logs are extended. As a result, whenever AppendEntries returns successfully, the leader knows that the follower's log is identical to its own log up through the new entries.
+
+During normal operation, the logs of the leader and followers stay consistent, so the AppendEntries consistency check never fails. However, leader crashes can leave the logs inconsistent (the old leader may not have fully replicated all of the entries in its log). These inconsistencies can compound over a series of leader and follower crashes. Figure 7 illustrates the ways in which followers' logs may differ from that of a new leader. A follower may be missing entries that are present on the leader, it may have extra entries that are not present on the leader, or both. Missing and extraneous entries in a log may span multiple terms.
+
+
+
+**Figure 7:** When the leader at the top comes to power, it is possible that any of scenarios (a–f) could occur in follower logs. Each box represents one log entry; the number in the box is its term. A follower may be missing entries (a–b), may have extra uncommitted entries (c–d), or both (e–f).
+
+In Raft, the leader handles inconsistencies by forcing the followers' logs to duplicate its own. This means that conflicting entries in follower logs will be overwritten with entries from the leader's log. Section 5.4 will show that this is safe when coupled with one more restriction. To bring a follower's log into consistency with its own, the leader must find the latest log entry where the two logs agree, delete any entries in the follower's log after that point, and send the follower all of the leader's entries after that point. All of these actions happen in response to the consistency check performed by AppendEntries RPCs. The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower. When a leader first comes to power, it initializes all nextIndex values to the index just after the last one in its log (11 in Figure 7). If a follower's log is inconsistent with the leader's, the AppendEntries consistency check will fail in the next AppendEntries RPC. After a rejection, the leader decrements nextIndex and retries the AppendEntries RPC. Eventually nextIndex will reach a point where the leader and follower logs match. When this happens, AppendEntries will succeed, which removes any conflicting entries in the follower's log and appends entries from the leader's log (if any). Once AppendEntries succeeds, the follower's log is consistent with the leader's, and it will remain that way for the rest of the term.
+
+If desired, the protocol can be optimized to reduce the number of rejected AppendEntries RPCs. For example, when rejecting an AppendEntries request, the follower can include the term of the conflicting entry and the first index it stores for that term. With this information, the leader can decrement nextIndex to bypass all of the conflicting entries in that term; one AppendEntries RPC will be required for each term with conflicting entries, rather than one RPC per entry. In practice, we doubt this optimization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent entries.
+
+With this mechanism, a leader does not need to take any special actions to restore log consistency when it comes to power. It just begins normal operation, and the logs automatically converge in response to failures of the AppendEntries consistency check. A leader never overwrites or deletes entries in its own log (the Leader Append-Only Property in Figure 3).
+
+This log replication mechanism exhibits the desirable consensus properties described in Section 2: Raft can accept, replicate, and apply new log entries as long as a majority of the servers are up; in the normal case a new entry can be replicated with a single round of RPCs to a majority of the cluster; and a single slow follower will not impact performance.
+
+### 5.4 Safety
+
+The previous sections described how Raft elects leaders and replicates log entries. However, the mechanisms described so far are not quite sufficient to ensure that each state machine executes exactly the same commands in the same order. For example, a follower might be unavailable while the leader commits several log entries, then it could be elected leader and overwrite these entries with new ones; as a result, different state machines might execute different command sequences.
+
+This section completes the Raft algorithm by adding a restriction on which servers may be elected leader. The restriction ensures that the leader for any given term contains all of the entries committed in previous terms (the Leader Completeness Property from Figure 3). Given the election restriction, we then make the rules for commitment more precise. Finally, we present a proof sketch for the Leader Completeness Property and show how it leads to correct behavior of the replicated state machine.
+
+#### 5.4.1 Election restriction
+
+In any leader-based consensus algorithm, the leader must eventually store all of the committed log entries. In some consensus algorithms, such as Viewstamped Replication [22], a leader can be elected even if it doesn't initially contain all of the committed entries. These algorithms contain additional mechanisms to identify the missing entries and transmit them to the new leader, either during the election process or shortly afterwards. Unfortunately, this results in considerable additional mechanism and complexity. Raft uses a simpler approach where it guarantees that all the committed entries from previous terms are present on each new leader from the moment of its election, without the need to transfer those entries to the leader. This means that log entries only flow in one direction, from leaders to followers, and leaders never overwrite existing entries in their logs.
+
+
+
+**Figure 8:** A time sequence showing why a leader cannot de-termine commitment using log entries from older terms. In (a) S1 is leader and partially replicates the log entry at index 2. In (b) S1 crashes; S5 is elected leader for term 3 with votes from S3, S4, and itself, and accepts a different entry at log index 2. In (c) S5 crashes; S1 restarts, is elected leader, and continues replication. At this point, the log entry from term 2 has been replicated on a majority of the servers, but it is not committed. If S1 crashes as in (d), S5 could be elected leader (with votes from S2, S3, and S4) and overwrite the entry with its own entry from term 3. However, if S1 replicates an en- try from its current term on a majority of the servers before crashing, as in (e), then this entry is committed (S5 cannot win an election). At this point all preceding entries in the log are committed as well.
+
+Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries. A candidate must contact a majority of the cluster in order to be elected, which means that every committed entry must be present in at least one of those servers. If the candidate's log is at least as up-to-date as any other log in that majority (where "up-to-date" is defined precisely below), then it will hold all the committed entries. The RequestVote RPC implements this restriction: the RPC includes information about the candidate's log, and the voter denies its vote if its own log is more up-to-date than that of the candidate.
+
+Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
+
+#### 5.4.2 Committing entries from previous terms
+
+As described in Section 5.3, a leader knows that an entry from its current term is committed once that entry is stored on a majority of the servers. If a leader crashes before committing an entry, future leaders will attempt to finish replicating the entry. However, a leader cannot immediately conclude that an entry from a previous term is committed once it is stored on a majority of servers. Figure 8 illustrates a situation where an old log entry is stored on a majority of servers, yet can still be overwritten by a future leader.
+
+
+
+**Figure 9:** If S1 (leader for term T) commits a new log entry from its term, and S5 is elected leader for a later term U, then there must be at least one server (S3) that accepted the log entry and also voted for S5.
+
+To eliminate problems like the one in Figure 8, Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader's current term are committed by counting replicas; once an entry from the current term has been committed in this way, then all prior entries are committed indirectly because of the Log Matching Property. There are some situations where a leader could safely conclude that an older log entry is committed (for example, if that entry is stored on every server), but Raft takes a more conservative approach for simplicity.
+
+Raft incurs this extra complexity in the commitment rules because log entries retain their original term numbers when a leader replicates entries from previous terms. In other consensus algorithms, if a new leader re-replicates entries from prior "terms," it must do so with its new "term number." Raft's approach makes it easier to reason about log entries, since they maintain the same term number over time and across logs. In addition, new leaders in Raft send fewer log entries from previous terms than in other algorithms (other algorithms must send redundant log entries to renumber them before they can be committed).
+
+#### 5.4.3 Safety argument
+
+Given the complete Raft algorithm, we can now argue more precisely that the Leader Completeness Property holds (this argument is based on the safety proof; see Section 9.2). We assume that the Leader Completeness Property does not hold, then we prove a contradiction. Suppose the leader for term T (leaderT) commits a log entry from its term, but that log entry is not stored by the leader of some future term. Consider the smallest term U > T whose leader (leaderU) does not store the entry.
+
+1. The committed entry must have been absent from leaderU's log at the time of its election (leaders never delete or overwrite entries).
+2. leaderT replicated the entry on a majority of the cluster, and leaderU received votes from a majority of the cluster. Thus, at least one server ("the voter") both accepted the entry from leaderT and voted for leaderU, as shown in Figure 9. The voter is key to reaching a contradiction.
+3. The voter must have accepted the committed entry from leaderT before voting for leaderU; otherwise it would have rejected the AppendEntries request from leaderT (its current term would have been higher than T).
+4. The voter still stored the entry when it voted for leaderU, since every intervening leader contained the entry (by assumption), leaders never remove entries, and followers only remove entries if they conflict with the leader.
+5. The voter granted its vote to leaderU, so leaderU's log must have been as up-to-date as the voter's. This leads to one of two contradictions.
+6. First, if the voter and leaderU shared the same last log term, then leaderU's log must have been at least as long as the voter's, so its log contained every entry in the voter's log. This is a contradiction, since the voter contained the committed entry and leaderU was assumed not to.
+7. Otherwise, leaderU's last log term must have been larger than the voter's. Moreover, it was larger than T, since the voter's last log term was at least T (it contains the committed entry from term T). The earlier leader that created leaderU's last log entry must have contained the committed entry in its log (by assumption). Then, by the Log Matching Property, leaderU's log must also contain the committed entry, which is a contradiction.
+8. This completes the contradiction. Thus, the leaders of all terms greater than T must contain all entries from term T that are committed in term T.
+9. The Log Matching Property guarantees that future leaders will also contain entries that are committed indirectly, such as index 2 in Figure 8(d).
+
+Given the Leader Completeness Property, we can prove the State Machine Safety Property from Figure 3, which states that if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. At the time a server applies a log entry to its state machine, its log must be identical to the leader's log up through that entry and the entry must be committed. Now consider the lowest term in which any server applies a given log index; the Log Completeness Property guarantees that the leaders for all higher terms will store that same log entry, so servers that apply the index in later terms will apply the same value. Thus, the State Machine Safety Property holds.
+
+Finally, Raft requires servers to apply entries in log index order. Combined with the State Machine Safety Property, this means that all servers will apply exactly the same set of log entries to their state machines, in the same order.
+
+### 5.5 Follower and candidate crashes
+
+Until this point we have focused on leader failures. Follower and candidate crashes are much simpler to handle than leader crashes, and they are both handled in the same way. If a follower or candidate crashes, then future RequestVote and AppendEntries RPCs sent to it will fail. Raft handles these failures by retrying indefinitely; if the crashed server restarts, then the RPC will complete successfully. If a server crashes after completing an RPC but before responding, then it will receive the same RPC again after it restarts. Raft RPCs are idempotent, so this causes no harm. For example, if a follower receives an AppendEntries request that includes log entries already present in its log, it ignores those entries in the new request.
+
+### 5.6 Timing and availability
+
+One of our requirements for Raft is that safety must not depend on timing: the system must not produce incorrect results just because some event happens more quickly or slowly than expected. However, availability (the ability of the system to respond to clients in a timely manner) must inevitably depend on timing. For example, if message exchanges take longer than the typical time between server crashes, candidates will not stay up long enough to win an election; without a steady leader, Raft cannot make progress.
+
+Leader election is the aspect of Raft where timing is most critical. Raft will be able to elect and maintain a steady leader as long as the system satisfies the following timing requirement:
+
+**broadcastTime ≪ electionTimeout ≪ MTBF**
+
+In this inequality broadcastTime is the average time it takes a server to send RPCs in parallel to every server in the cluster and receive their responses; electionTimeout is the election timeout described in Section 5.2; and MTBF is the average time between failures for a single server. The broadcast time should be an order of magnitude less than the election timeout so that leaders can reliably send the heartbeat messages required to keep followers from starting elections; given the randomized approach used for election timeouts, this inequality also makes split votes unlikely. The election timeout should be a few orders of magnitude less than MTBF so that the system makes steady progress. When the leader crashes, the system will be unavailable for roughly the election timeout; we would like this to represent only a small fraction of overall time.
+
+The broadcast time and MTBF are properties of the underlying system, while the election timeout is something we must choose. Raft's RPCs typically require the recipient to persist information to stable storage, so the broadcast time may range from 0.5ms to 20ms, depending on storage technology. As a result, the election timeout is likely to be somewhere between 10ms and 500ms. Typical server MTBFs are several months or more, which easily satisfies the timing requirement.
+
+## 6 Cluster membership changes
+
+Up until now we have assumed that the cluster configuration (the set of servers participating in the consensus algorithm) is fixed. In practice, it will occasionally be necessary to change the configuration, for example to replace servers when they fail or to change the degree of replication. Although this can be done by taking the entire cluster off-line, updating configuration files, and then restarting the cluster, this would leave the cluster unavailable during the changeover. In addition, if there are any manual steps, they risk operator error. In order to avoid these issues, we decided to automate configuration changes and incorporate them into the Raft consensus algorithm.
+
+For the configuration change mechanism to be safe, there must be no point during the transition where it is possible for two leaders to be elected for the same term. Unfortunately, any approach where servers switch directly from the old configuration to the new configuration is unsafe. It isn't possible to atomically switch all of the servers at once, so the cluster can potentially split into two independent majorities during the transition (see Figure 10).
+
+
+
+**Figure 10:** Switching directly from one configuration to another is unsafe because different servers will switch at different times. In this example, the cluster grows from three servers to five. Unfortunately, there is a point in time where two different leaders can be elected for the same term, one with a majority of the old configuration (C_old) and another with a majority of the new configuration (C_new).
+
+In order to ensure safety, configuration changes must use a two-phase approach. In Raft the cluster first switches to a transitional configuration we call joint consensus; once the joint consensus has been committed, the system then transitions to the new configuration. The joint consensus combines both the old and new configurations:
+
+- Log entries are replicated to all servers in both configurations.
+- Any server from either configuration may serve as leader.
+- Agreement (for elections and entry commitment) requires separate majorities from both the old and new configurations.
+
+
+
+**Figure 11:** Timeline for a configuration change. Dashed lines show configuration entries that have been created but not committed, and solid lines show the latest committed configuration entry. The leader first creates the C_old,new configuration entry in its log and commits it to C_old,new (a majority of C_old and a majority of C_new). Then it creates the C_new entry and commits it to a majority of C_new. There is no point in time in which C_old and C_new can both make decisions independently.
+
+The joint consensus allows individual servers to transition between configurations at different times without compromising safety. Furthermore, joint consensus allows the cluster to continue servicing client requests throughout the configuration change.
+
+Cluster configurations are stored and communicated using special entries in the replicated log; Figure 11 illustrates the configuration change process. When the leader receives a request to change the configuration from C_old to C_new, it stores the configuration for joint consensus (C_old,new in the figure) as a log entry and replicates that entry using the mechanisms described previously. Once a given server adds the new configuration entry to its log, it uses that configuration for all future decisions (a server always uses the latest configuration in its log, regardless of whether the entry is committed). This means that the leader will use the rules of C_old,new to determine when the log entry for C_old,new is committed. If the leader crashes, a new leader may be chosen under either C_old or C_old,new, depending on whether the winning candidate has received C_old,new. In any case, C_new cannot make unilateral decisions during this period.
+
+Once C_old,new has been committed, neither C_old nor C_new can make decisions without approval of the other, and the Leader Completeness Property ensures that only servers with the C_old,new log entry can be elected as leader. It is now safe for the leader to create a log entry describing C_new and replicate it to the cluster. Again, this configuration will take effect on each server as soon as it is seen. When the new configuration has been committed under the rules of C_new, the old configuration is irrelevant and servers not in the new configuration can be shut down. As shown in Figure 11, there is no time when C_old and C_new can both make unilateral decisions; this guarantees safety.
+
+There are three more issues to address for reconfiguration. The first issue is that new servers may not initially store any log entries. If they are added to the cluster in this state, it could take quite a while for them to catch up, during which time it might not be possible to commit new log entries. In order to avoid availability gaps, Raft introduces an additional phase before the configuration change, in which the new servers join the cluster as non-voting members (the leader replicates log entries to them, but they are not considered for majorities). Once the new servers have caught up with the rest of the cluster, the reconfiguration can proceed as described above.
+
+The second issue is that the cluster leader may not be part of the new configuration. In this case, the leader steps down (returns to follower state) once it has committed the C_new log entry. This means that there will be a period of time (while it is committing C_new) when the leader is managing a cluster that does not include itself; it replicates log entries but does not count itself in majorities. The leader transition occurs when C_new is committed because this is the first point when the new configuration can operate independently (it will always be possible to choose a leader from C_new). Before this point, it may be the case that only a server from C_old can be elected leader.
+
+The third issue is that removed servers (those not in C_new) can disrupt the cluster. These servers will not receive heartbeats, so they will time out and start new elections. They will then send RequestVote RPCs with new term numbers, and this will cause the current leader to revert to follower state. A new leader will eventually be elected, but the removed servers will time out again and the process will repeat, resulting in poor availability. To prevent this problem, servers disregard RequestVote RPCs when they believe a current leader exists. Specifically, if a server receives a RequestVote RPC within the minimum election timeout of hearing from a current leader, it does not update its term or grant its vote. This does not affect normal elections, where each server waits at least a minimum election timeout before starting an election. However, it helps avoid disruptions from removed servers: if a leader is able to get heartbeats to its cluster, then it will not be deposed by larger term numbers.
+
+## 7 Log compaction
+
+Raft's log grows during normal operation to incorporate more client requests, but in a practical system, it cannot grow without bound. As the log grows longer, it occupies more space and takes more time to replay. This will eventually cause availability problems without some mechanism to discard obsolete information that has accumulated in the log.
+
+Snapshotting is the simplest approach to compaction. In snapshotting, the entire current system state is written to a snapshot on stable storage, then the entire log up to that point is discarded. Snapshotting is used in Chubby and ZooKeeper, and the remainder of this section describes snapshotting in Raft.
+
+Incremental approaches to compaction, such as log cleaning [36] and log-structured merge trees [30, 5], are also possible. These operate on a fraction of the data at once, so they spread the load of compaction more evenly over time. They first select a region of data that has accumulated many deleted and overwritten objects, then they rewrite the live objects from that region more compactly and free the region. This requires significant additional mechanism and complexity compared to snapshotting, which simplifies the problem by always operating on the entire data set. While log cleaning would require modifications to Raft, state machines can implement LSM trees using the same interface as snapshotting.
+
+
+
+**Figure 12:** A server replaces the committed entries in its log (indexes 1 through 5) with a new snapshot, which stores just the current state (variables x and y in this example). The snapshot's last included index and term serve to position the snapshot in the log preceding entry 6.
+
+Figure 12 shows the basic idea of snapshotting in Raft. Each server takes snapshots independently, covering just the committed entries in its log. Most of the work consists of the state machine writing its current state to the snapshot. Raft also includes a small amount of metadata in the snapshot: the last included index is the index of the last entry in the log that the snapshot replaces (the last entry the state machine had applied), and the last included term is the term of this entry. These are preserved to support the AppendEntries consistency check for the first log entry following the snapshot, since that entry needs a previous log index and term. To enable cluster membership changes (Section 6), the snapshot also includes the latest configuration in the log as of last included index. Once a server completes writing a snapshot, it may delete all log entries up through the last included index, as well as any prior snapshot.
+
+Although servers normally take snapshots independently, the leader must occasionally send snapshots to followers that lag behind. This happens when the leader has already discarded the next log entry that it needs to send to a follower. The leader uses a new RPC called InstallSnapshot to send snapshots to followers that are too far behind; see Figure 13. When a follower receives a snapshot with this RPC, it must decide what to do with its existing log entries. Usually the snapshot will contain new information not already in the recipient's log. In this case, the follower discards its entire log; it is all superseded by the snapshot and may possibly have uncommitted entries that conflict with the snapshot. If instead the follower receives a snapshot that describes a prefix of its log (due to retransmission or by mistake), then log entries covered by the snapshot are deleted but entries following the snapshot are still valid and must be retained.
+
+> InstallSnapshot RPC
+>
+>
+> *Invoked by leader to send chunks of a snapshot to a follower.*
+>
+> *Leaders always send chunks in order.*
+>
+>
+> **Arguments:**
+>
+> `term`: leader's term
+>
+> `leaderId`: so follower can redirect clients
+>
+> `lastIncludedIndex`: the snapshot replaces all entries up through and including this index
+>
+> `lastIncludedTerm`: term of lastIncludedIndex
+>
+> `offset`: byte offset where chunk is positioned in the snapshot file
+>
+> `data[]`: raw bytes of the snapshot chunk, starting at offset
+>
+> `done`: true if this is the last chunk
+>
+>
+> **Results:**
+>
+> `term`: currentTerm, for leader to update itself
+>
+>
+> **Receiver implementation:**
+>
+> 1. Reply immediately if term < currentTerm
+>
+> 2. Create new snapshot file if first chunk (offset is 0)
+>
+> 3. Write data into snapshot file at given offset
+>
+> 4. Reply and wait for more data chunks if done is false
+>
+> 5. Save snapshot file, discard any existing or partial snapshot with a smaller index
+>
+> 6. If existing log entry has same index and term as snapshot's last included entry, retain log entries following it and reply
+>
+> 7. Discard the entire log
+>
+> 8. Reset state machine using snapshot contents (and load snapshot's cluster configuration)
+>
+
+**Figure 13:** A summary of the InstallSnapshot RPC. Snapshots are split into chunks for transmission; this gives the follower a sign of life with each chunk, so it can reset its election timer.
+
+This snapshotting approach departs from Raft's strong leader principle, since followers can take snapshots without the knowledge of the leader. However, we think this departure is justified. While having a leader helps avoid conflicting decisions in reaching consensus, consensus has already been reached when snapshotting, so no decisions conflict. Data still only flows from leaders to followers, just followers can now reorganize their data.
+
+There are two more issues that impact snapshotting performance. First, servers must decide when to snapshot. If a server snapshots too often, it wastes disk bandwidth and energy; if it snapshots too infrequently, it risks exhausting its storage capacity, and it increases the time required to replay the log during restarts. One simple strategy is to take a snapshot when the log reaches a fixed size in bytes. If this size is set to be significantly larger than the expected size of a snapshot, then the disk bandwidth overhead for snapshotting will be small. The second performance issue is that writing a snapshot can take a significant amount of time, and we do not want this to delay normal operations. The solution is to use copy-on-write techniques so that new updates can be accepted without impacting the snapshot being written. For example, state machines built with functional data structures naturally support this. Alternatively, the operating system's copy-on-write support (e.g., fork on Linux) can be used to create an in-memory snapshot of the entire state machine (our implementation uses this approach).
+
+## 8 Client interaction
+
+This section describes how clients interact with Raft, including how clients find the cluster leader and how Raft supports linearizable semantics [10]. These issues apply to all consensus-based systems, and Raft's solutions are similar to other systems.
+
+Clients of Raft send all of their requests to the leader. When a client first starts up, it connects to a randomly-chosen server. If the client's first choice is not the leader, that server will reject the client's request and supply information about the most recent leader it has heard from (AppendEntries requests include the network address of the leader). If the leader crashes, client requests will time out; clients then try again with randomly-chosen servers.
+
+Our goal for Raft is to implement linearizable semantics (each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response). However, as described so far Raft can execute a command multiple times: for example, if the leader crashes after committing the log entry but before responding to the client, the client will retry the command with a new leader, causing it to be executed a second time. The solution is for clients to assign unique serial numbers to every command. Then, the state machine tracks the latest serial number processed for each client, along with the associated response. If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
+
+Read-only operations can be handled without writing anything into the log. However, with no additional measures, this would run the risk of returning stale data, since the leader responding to the request might have been superseded by a newer leader of which it is unaware. Linearizable reads must not return stale data, and Raft needs two extra precautions to guarantee this without using the log. First, a leader must have the latest information on which entries are committed. The Leader Completeness Property guarantees that a leader has all committed entries, but at the start of its term, it may not know which those are. To find out, it needs to commit an entry from its term. Raft handles this by having each leader commit a blank no-op entry into the log at the start of its term. Second, a leader must check whether it has been deposed before processing a read-only request (its information may be stale if a more recent leader has been elected). Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests. Alternatively, the leader could rely on the heartbeat mechanism to provide a form of lease [9], but this would rely on timing for safety (it assumes bounded clock skew).
+
+## 9 Implementation and evaluation
+
+We have implemented Raft as part of a replicated state machine that stores configuration information for RAMCloud [33] and assists in failover of the RAMCloud coordinator. The Raft implementation contains roughly 2000 lines of C++ code, not including tests, comments, or blank lines. The source code is freely available [23]. There are also about 25 independent third-party open source implementations [34] of Raft in various stages of development, based on drafts of this paper. Also, various companies are deploying Raft-based systems [34].
+
+The remainder of this section evaluates Raft using three criteria: understandability, correctness, and performance.
+
+### 9.1 Understandability
+
+To measure Raft's understandability relative to Paxos, we conducted an experimental study using upper-level undergraduate and graduate students in an Advanced Operating Systems course at Stanford University and a Distributed Computing course at U.C. Berkeley. We recorded a video lecture of Raft and another of Paxos, and created corresponding quizzes. The Raft lecture covered the content of this paper except for log compaction; the Paxos lecture covered enough material to create an equivalent replicated state machine, including single-decree Paxos, multi-decree Paxos, reconfiguration, and a few optimizations needed in practice (such as leader election). The quizzes tested basic understanding of the algorithms and also required students to reason about corner cases. Each student watched one video, took the corresponding quiz, watched the second video, and took the second quiz. About half of the participants did the Paxos portion first and the other half did the Raft portion first in order to account for both individual differences in performance and experience gained from the first portion of the study. We compared participants' scores on each quiz to determine whether participants showed a better understanding of Raft.
+
+We tried to make the comparison between Paxos and Raft as fair as possible. The experiment favored Paxos in two ways: 15 of the 43 participants reported having some prior experience with Paxos, and the Paxos video is 14% longer than the Raft video. As summarized in Table 1, we have taken steps to mitigate potential sources of bias. All of our materials are available for review [28, 31].
+
+On average, participants scored 4.9 points higher on the Raft quiz than on the Paxos quiz (out of a possible 60 points, the mean Raft score was 25.7 and the mean Paxos score was 20.8); Figure 14 shows their individual scores. A paired t-test states that, with 95% confidence, the true distribution of Raft scores has a mean at least 2.5 points larger than the true distribution of Paxos scores.
+
+We also created a linear regression model that predicts a new student's quiz scores based on three factors: which quiz they took, their degree of prior Paxos experience, and the order in which they learned the algorithms. The model predicts that the choice of quiz produces a 12.5-point difference in favor of Raft. This is significantly higher than the observed difference of 4.9 points, because many of the actual students had prior Paxos experience, which helped Paxos considerably, whereas it helped Raft slightly less. Curiously, the model also predicts scores 6.3 points lower on Raft for people that have already taken the Paxos quiz; although we don't know why, this does appear to be statistically significant.
+
+We also surveyed participants after their quizzes to see which algorithm they felt would be easier to implement or explain; these results are shown in Figure 15. An overwhelming majority of participants reported Raft would be easier to implement and explain (33 of 41 for each question). However, these self-reported feelings may be less reliable than participants' quiz scores, and participants may have been biased by knowledge of our hypothesis that Raft is easier to understand. A detailed discussion of the Raft user study is available at [31].
+
+
+
+**Figure 14:** A scatter plot comparing 43 participants’ performance on the Raft and Paxos quizzes. Points above the diagonal (33) represent participants who scored higher for Raft.
+
+
+
+**Figure 15:** Using a 5-point scale, participants were asked (left) which algorithm they felt would be easier to implement in a functioning, correct, and efficient system, and (right) which would be easier to explain to a CS graduate student.
+
+### 9.2 Correctness
+
+We have developed a formal specification and a proof of safety for the consensus mechanism described in Section 5. The formal specification [31] makes the information summarized in Figure 2 completely precise using the TLA+ specification language [17]. It is about 400 lines long and serves as the subject of the proof. It is also useful on its own for anyone implementing Raft. We have mechanically proven the Log Completeness Property using the TLA proof system [7]. However, this proof relies on invariants that have not been mechanically checked (for example, we have not proven the type safety of the specification). Furthermore, we have written an informal proof [31] of the State Machine Safety property which is complete (it relies on the specification alone) and relatively precise (it is about 3500 words long).
+
+**Table 1:** Concerns of possible bias against Paxos in the study, steps taken to counter each, and additional materials available.
+
+| Concern | Steps taken to mitigate bias | Materials for review [28, 31] |
+|--------|-----------------------------|------------------------------|
+| Equal lecture quality | Same lecturer for both. Paxos lecture based on and improved from existing materials used in several universities. Paxos lecture is 14% longer. | videos |
+| Equal quiz difficulty | Questions grouped in difficulty and paired across exams. | quizzes |
+| Fair grading | Used rubric. Graded in random order, alternating between quizzes. | rubric |
+
+### 9.3 Performance
+
+Raft's performance is similar to other consensus algorithms such as Paxos. The most important case for performance is when an established leader is replicating new log entries. Raft achieves this using the minimal number of messages (a single round-trip from the leader to half the cluster). It is also possible to further improve Raft's performance. For example, it easily supports batching and pipelining requests for higher throughput and lower latency. Various optimizations have been proposed in the literature for other algorithms; many of these could be applied to Raft, but we leave this to future work.
+
+We used our Raft implementation to measure the performance of Raft's leader election algorithm and answer two questions. First, does the election process converge quickly? Second, what is the minimum downtime that can be achieved after leader crashes? To measure leader election, we repeatedly crashed the leader of a cluster of five servers and timed how long it took to detect the crash and elect a new leader (see Figure 16). The top graph in Figure 16 shows that a small amount of randomization in the election timeout is enough to avoid split votes in elections. In the absence of randomness, leader election consistently took longer than 10 seconds in our tests due to many split votes. Adding just 5ms of randomness helps significantly, resulting in a median downtime of 287ms. Using more randomness improves worst-case behavior: with 50ms of randomness the worst-case completion time (over 1000 trials) was 513ms. The bottom graph in Figure 16 shows that downtime can be reduced by reducing the election timeout. With an election timeout of 12–24ms, it takes only 35ms on average to elect a leader (the longest trial took 152ms). However, lowering the timeouts beyond this point violates Raft's timing requirement: leaders have difficulty broadcasting heartbeats before other servers start new elections. This can cause unnecessary leader changes and lower overall system availability. We recommend using a conservative election timeout such as 150–300ms; such timeouts are unlikely to cause unnecessary leader changes and will still provide good availability.
+
+
+
+**Figure 16:** The time to detect and replace a crashed leader. The top graph varies the amount of randomness in election timeouts, and the bottom graph scales the minimum election timeout. Each line represents 1000 trials (except for 100 trials for “150–150ms”) and corresponds to a particular choice of election timeouts; for example, “150–155ms” means that election timeouts were chosen randomly and uniformly between 150ms and 155ms. The measurements were taken on a cluster of five servers with a broadcast time of roughly 15ms. Results for a cluster of nine servers are similar.
+
+## 10 Related work
+
+There have been numerous publications related to consensus algorithms, many of which fall into one of the following categories:
+
+- Lamport's original description of Paxos [15], and attempts to explain it more clearly [16, 20, 21].
+- Elaborations of Paxos, which fill in missing details and modify the algorithm to provide a better foundation for implementation [26, 39, 13].
+- Systems that implement consensus algorithms, such as Chubby [2, 4], ZooKeeper [11, 12], and Spanner [6]. The algorithms for Chubby and Spanner have not been published in detail, though both claim to be based on Paxos. ZooKeeper's algorithm has been published in more detail, but it is quite different from Paxos.
+- Performance optimizations that can be applied to Paxos [18, 19, 3, 25, 1, 27].
+- Oki and Liskov's Viewstamped Replication (VR), an alternative approach to consensus developed around the same time as Paxos. The original description [29] was intertwined with a protocol for distributed transactions, but the core consensus protocol has been separated in a recent update [22]. VR uses a leader-based approach with many similarities to Raft.
+
+The greatest difference between Raft and Paxos is Raft's strong leadership: Raft uses leader election as an essential part of the consensus protocol, and it concentrates as much functionality as possible in the leader. This approach results in a simpler algorithm that is easier to understand. For example, in Paxos, leader election is orthogonal to the basic consensus protocol: it serves only as a performance optimization and is not required for achieving consensus. However, this results in additional mechanism: Paxos includes both a two-phase protocol for basic consensus and a separate mechanism for leader election. In contrast, Raft incorporates leader election directly into the consensus algorithm and uses it as the first of the two phases of consensus. This results in less mechanism than in Paxos.
+
+Like Raft, VR and ZooKeeper are leader-based and therefore share many of Raft's advantages over Paxos. However, Raft has less mechanism than VR or ZooKeeper because it minimizes the functionality in non-leaders. For example, log entries in Raft flow in only one direction: outward from the leader in AppendEntries RPCs. In VR log entries flow in both directions (leaders can receive log entries during the election process); this results in additional mechanism and complexity. The published description of ZooKeeper also transfers log entries both to and from the leader, but the implementation is apparently more like Raft [35].
+
+Raft has fewer message types than any other algorithm for consensus-based log replication that we are aware of. For example, we counted the message types VR and ZooKeeper use for basic consensus and membership changes (excluding log compaction and client interaction, as these are nearly independent of the algorithms). VR and ZooKeeper each define 10 different message types, while Raft has only 4 message types (two RPC requests and their responses). Raft's messages are a bit more dense than the other algorithms', but they are simpler collectively.
+
+Raft's strong leadership approach simplifies the algorithm, but it precludes some performance optimizations. For example, Egalitarian Paxos (EPaxos) can achieve higher performance under some conditions with a leaderless approach [27]. EPaxos exploits commutativity in state machine commands. Any server can commit a command with just one round of communication as long as other commands that are proposed concurrently commute with it. However, if commands that are proposed concurrently do not commute with each other, EPaxos requires an additional round of communication. Because any server may commit commands, EPaxos balances load well between servers and is able to achieve lower latency than Raft in WAN settings. However, it adds significant complexity to Paxos.
+
+Several different approaches for cluster membership changes have been proposed or implemented in other work, including Lamport's original proposal [15], VR [22], and SMART [24]. We chose the joint consensus approach for Raft because it leverages the rest of the consensus protocol, so that very little additional mechanism is required for membership changes. Lamport's α-based approach was not an option for Raft because it assumes consensus can be reached without a leader. In comparison to VR and SMART, Raft's reconfiguration algorithm has the advantage that membership changes can occur without limiting the processing of normal requests; in contrast, VR stops all normal processing during configuration changes, and SMART imposes an α-like limit on the number of outstanding requests. Raft's approach also adds less mechanism than either VR or SMART.
+
+## 11 Conclusion
+
+Algorithms are often designed with correctness, efficiency, and/or conciseness as the primary goals. Although these are all worthy goals, we believe that understandability is just as important. None of the other goals can be achieved until developers render the algorithm into a practical implementation, which will inevitably deviate from and expand upon the published form. Unless developers have a deep understanding of the algorithm and can create intuitions about it, it will be difficult for them to retain its desirable properties in their implementation.
+
+In this paper we addressed the issue of distributed consensus, where a widely accepted but impenetrable algorithm, Paxos, has challenged students and developers for many years. We developed a new algorithm, Raft, which we have shown to be more understandable than Paxos. We also believe that Raft provides a better foundation for system building. Using understandability as the primary design goal changed the way we approached the design of Raft; as the design progressed we found ourselves reusing a few techniques repeatedly, such as decomposing the problem and simplifying the state space. These techniques not only improved the understandability of Raft but also made it easier to convince ourselves of its correctness.
+
+## 12 Acknowledgments
+
+The user study would not have been possible without the support of Ali Ghodsi, David Mazières, and the students of CS 294-91 at Berkeley and CS 240 at Stanford. Scott Klemmer helped us design the user study, and Nelson Ray advised us on statistical analysis. The Paxos slides for the user study borrowed heavily from a slide deck originally created by Lorenzo Alvisi. Special thanks go to David Mazières and Ezra Hoch for finding subtle bugs in Raft. Many people provided helpful feedback on the paper and user study materials, including Ed Bugnion, Michael Chan, Hugues Evrard, Daniel Giffin, Arjun Gopalan, Jon Howell, Vimalkumar Jeyakumar, Ankita Kejriwal, Aleksandar Kracun, Amit Levy, Joel Martin, Satoshi Matsushita, Oleg Pesok, David Ramos, Robbert van Renesse, Mendel Rosenblum, Nicolas Schiper, Deian Stefan, Andrew Stone, Ryan Stutsman, David Terei, Stephen Yang, Matei Zaharia, 24 anonymous conference reviewers (with duplicates), and especially our shepherd Eddie Kohler. Werner Vogels tweeted a link to an earlier draft, which gave Raft significant exposure. This work was supported by the Gigascale Systems Research Center and the Multiscale Systems Center, two of six research centers funded under the Focus Center Research Program, a Semiconductor Research Corporation program, by STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA, by the National Science Foundation under Grant No. 0963859, and by grants from Facebook, Google, Mellanox, NEC, NetApp, SAP, and Samsung. Diego Ongaro is supported by The Junglee Corporation Stanford Graduate Fellowship.
+
+## References
+
+[1] BOLOSKY, W. J., BRADSHAW, D., HAAGENS, R. B., KUSTERS, N. P., AND LI, P. Paxos replicated state machines as the basis of a high-performance data store. In Proc. NSDI'11, USENIX Conference on Networked Systems Design and Implementation (2011), USENIX, pp. 141–154.
+
+[2] BURROWS, M. The Chubby lock service for loosely-coupled distributed systems. In Proc. OSDI'06, Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 335–350.
+
+[3] CAMARGOS, L. J., SCHMIDT, R. M., AND PEDONE, F. Multicoordinated Paxos. In Proc. PODC'07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 316–317.
+
+[4] CHANDRA, T. D., GRIESEMER, R., AND REDSTONE, J. Paxos made live: an engineering perspective. In Proc. PODC'07, ACM Symposium on Principles of Distributed Computing (2007), ACM, pp. 398–407.
+
+[5] CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W. C., WALLACH, D. A., BURROWS, M., CHANDRA, T., FIKES, A., AND GRUBER, R. E. Bigtable: a distributed storage system for structured data. In Proc. OSDI'06, USENIX Symposium on Operating Systems Design and Implementation (2006), USENIX, pp. 205–218.
+
+[6] CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV, A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google's globally-distributed database. In Proc. OSDI'12, USENIX Conference on Operating Systems Design and Implementation (2012), USENIX, pp. 251–264.
+
+[7] COUSINEAU, D., DOLIGEZ, D., LAMPORT, L., MERZ, S., RICKETTS, D., AND VANZETTO, H. TLA+ proofs. In Proc. FM'12, Symposium on Formal Methods (2012), D. Giannakopoulou and D. M´ery, Eds., vol. 7436 of Lecture Notes in Computer Science, Springer, pp. 147–154.
+
+[8] GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google file system. In Proc. SOSP'03, ACM Symposium on Operating Systems Principles (2003), ACM, pp. 29–43.
+
+[9] GRAY, C., AND CHERITON, D. Leases: An efficient fault-tolerant mechanism for distributed file cache consistency. In Proceedings of the 12th ACM Symposium on Operating Systems Principles (1989), pp. 202–210.
+
+[10] HERLIHY, M. P., AND WING, J. M. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems 12 (July 1990), 463–492.
+
+[11] HUNT, P., KONAR, M., JUNQUEIRA, F. P., AND REED, B. ZooKeeper: wait-free coordination for internet-scale systems. In Proc ATC'10, USENIX Annual Technical Conference (2010), USENIX, pp. 145–158.
+
+[12] JUNQUEIRA, F. P., REED, B. C., AND SERAFINI, M. Zab: High-performance broadcast for primary-backup systems. In Proc. DSN'11, IEEE/IFIP Int'l Conf. on Dependable Systems & Networks (2011), IEEE Computer Society, pp. 245–256.
+
+[13] KIRSCH, J., AND AMIR, Y. Paxos for system builders. Tech. Rep. CNDS-2008-2, Johns Hopkins University, 2008.
+
+[14] LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM 21, 7 (July 1978), 558–565.
+
+[15] LAMPORT, L. The part-time parliament. ACM Transactions on Computer Systems 16, 2 (May 1998), 133–169.
+
+[16] LAMPORT, L. Paxos made simple. ACM SIGACT News 32, 4 (Dec. 2001), 18–25.
+
+[17] LAMPORT, L. Specifying Systems, The TLA+ Language and Tools for Hardware and Software Engineers. Addison-Wesley, 2002.
+
+[18] LAMPORT, L. Generalized consensus and Paxos. Tech. Rep. MSR-TR-2005-33, Microsoft Research, 2005.
+
+[19] LAMPORT, L. Fast paxos. Distributed Computing 19, 2 (2006), 79–103.
+
+[20] LAMPSON, B. W. How to build a highly available system using consensus. In Distributed Algorithms, O. Babaoğlu and K. Marzullo, Eds. Springer-Verlag, 1996, pp. 1–17.
+
+[21] LAMPSON, B. W. The ABCD's of Paxos. In Proc. PODC'01, ACM Symposium on Principles of Distributed Computing (2001), ACM, pp. 13–13.
+
+[22] LISKOV, B., AND COWLING, J. Viewstamped replication revisited. Tech. Rep. MIT-CSAIL-TR-2012-021, MIT, July 2012.
+
+[23] LogCabin source code. http://github.com/logcabin/logcabin.
+
+[24] LORCH, J. R., ADYA, A., BOLOSKY, W. J., CHAIKEN, R., DOUCEUR, J. R., AND HOWELL, J. The SMART way to migrate replicated stateful services. In Proc. EuroSys'06, ACM SIGOPS/EuroSys European Conference on Computer Systems (2006), ACM, pp. 103–115.
+
+[25] MAO, Y., JUNQUEIRA, F. P., AND MARZULLO, K. Mencius: building efficient replicated state machines for WANs. In Proc. OSDI'08, USENIX Conference on Operating Systems Design and Implementation (2008), USENIX, pp. 369–384.
+
+[26] MAZIÈRES, D. Paxos made practical. http://www.scs.stanford.edu/~dm/home/papers/paxos.pdf, Jan. 2007.
+
+[27] MORARU, I., ANDERSEN, D. G., AND KAMINSKY, M. There is more consensus in egalitarian parliaments. In Proc. SOSP'13, ACM Symposium on Operating System Principles (2013), ACM.
+
+[28] Raft user study. http://ramcloud.stanford.edu/~ongaro/userstudy/.
+
+[29] OKI, B. M., AND LISKOV, B. H. Viewstamped replication: A new primary copy method to support highly-available distributed systems. In Proc. PODC'88, ACM Symposium on Principles of Distributed Computing (1988), ACM, pp. 8–17.
+
+[30] O'NEIL, P., CHENG, E., GAWLICK, D., AND ONEIL, E. The log-structured merge-tree (LSM-tree). Acta Informatica 33, 4 (1996), 351–385.
+
+[31] ONGARO, D. Consensus: Bridging Theory and Practice. PhD thesis, Stanford University, 2014 (work in progress). http://ramcloud.stanford.edu/~ongaro/thesis.pdf.
+
+[32] ONGARO, D., AND OUSTERHOUT, J. In search of an understandable consensus algorithm. In Proc ATC'14, USENIX Annual Technical Conference (2014), USENIX.
+
+[33] OUSTERHOUT, J., AGRAWAL, P., ERICKSON, D., KOZYRAKIS, C., LEVERICH, J., MAZIÈRES, D., MITRA, S., NARAYANAN, A., ONGARO, D., PARULKAR, G., ROSENBLUM, M., RUMBLE, S. M., STRATMANN, E., AND STUTSMAN, R. The case for RAMCloud. Communications of the ACM 54 (July 2011), 121–130.
+
+[34] Raft consensus algorithm website. http://raftconsensus.github.io.
+
+[35] REED, B. Personal communications, May 17, 2013.
+
+[36] ROSENBLUM, M., AND OUSTERHOUT, J. K. The design and implementation of a log-structured file system. ACM Trans. Comput. Syst. 10 (February 1992), 26–52.
+
+[37] SCHNEIDER, F. B. Implementing fault-tolerant services using the state machine approach: a tutorial. ACM Computing Surveys 22, 4 (Dec. 1990), 299–319.
+
+[38] SHVACHKO, K., KUANG, H., RADIA, S., AND CHANSLER, R. The Hadoop distributed file system. In Proc. MSST'10, Symposium on Mass Storage Systems and Technologies (2010), IEEE Computer Society, pp. 1–10.
+
+[39] VAN RENESSE, R. Paxos made moderately complex. Tech. rep., Cornell University, 2012.
diff --git a/docs/papers/raft-extended.pdf b/docs/papers/raft-extended.pdf
new file mode 100644
index 0000000..34966b1
Binary files /dev/null and b/docs/papers/raft-extended.pdf differ
diff --git a/docs/papers/raft-locking-cn.txt b/docs/papers/raft-locking-cn.txt
new file mode 100644
index 0000000..527f202
--- /dev/null
+++ b/docs/papers/raft-locking-cn.txt
@@ -0,0 +1,54 @@
+Raft 加锁建议
+
+若你在 6.824 的 Raft 实验里不知如何用锁,下面是一些可能有用的规则和思路。
+
+规则 1:只要有多于一个 goroutine 使用的数据,且至少有一个 goroutine 可能修改该数据,这些 goroutine 就应使用锁来防止同时使用该数据。Go 的 race detector 在检测违反此规则方面表现不错(但不会帮助下面几条规则)。
+
+规则 2:只要代码对共享数据做一连串修改,且若其他 goroutine 在这串修改中途看到数据会出错,你就应在这整串操作外加锁。
+
+示例:
+
+ rf.mu.Lock()
+ rf.currentTerm += 1
+ rf.state = Candidate
+ rf.mu.Unlock()
+
+让另一个 goroutine 只看到其中一次更新(即旧 state 配新 term,或新 term 配旧 state)都是错误的。因此我们需要在这整串更新期间持续持有锁。所有使用 rf.currentTerm 或 rf.state 的其他代码也必须持有该锁,以保证所有访问的互斥。
+
+Lock() 和 Unlock() 之间的代码常被称为“临界区”(critical section)。程序员选定的加锁规则(例如“使用 rf.currentTerm 或 rf.state 时必须持有 rf.mu”)常被称为“加锁协议”(locking protocol)。
+
+规则 3:只要代码对共享数据做一连串读(或读和写),且若另一 goroutine 在这串操作中途修改数据会出错,你就应在这整串操作外加锁。
+
+一个可能在 Raft RPC handler 中出现的例子:
+
+ rf.mu.Lock()
+ if args.Term > rf.currentTerm {
+ rf.currentTerm = args.Term
+ }
+ rf.mu.Unlock()
+
+这段代码需要在这整串操作期间持续持有锁。Raft 要求 currentTerm 只增不减。另一个 RPC handler 可能在另一个 goroutine 中执行;若允许它在 if 判断和更新 rf.currentTerm 之间修改 rf.currentTerm,这段代码可能最终把 rf.currentTerm 减小。因此必须在这整串操作期间持续持有锁。此外,所有对 currentTerm 的其他使用都必须持有锁,以确保在我们临界区内没有其他 goroutine 修改 currentTerm。
+
+真实的 Raft 代码需要比这些示例更长的临界区;例如,Raft RPC handler 通常应在整个 handler 期间持有锁。
+
+规则 4:在持有锁的情况下做任何可能等待的事通常不是好主意:读 Go channel、向 channel 发送、等待定时器、调用 time.Sleep()、或发送 RPC(并等待回复)。一个原因是你可能希望其他 goroutine 在等待期间能推进。另一个原因是避免死锁。设想两个节点在持锁时互相发 RPC;两个 RPC handler 都需要对方节点的锁;两个 RPC handler 都无法完成,因为各自需要的锁正被等待中的 RPC 调用持有。
+
+会等待的代码应先释放锁。若不方便,有时可以单独起一个 goroutine 去做等待。
+
+规则 5:在释放锁再重新获取锁时,要小心对跨这段间隔的假设。一种常见情况是为了避免持锁等待。例如,下面这段发送 vote RPC 的代码是错误的:
+
+ rf.mu.Lock()
+ rf.currentTerm += 1
+ rf.state = Candidate
+ for {
+ go func() {
+ rf.mu.Lock()
+ args.Term = rf.currentTerm
+ rf.mu.Unlock()
+ Call("Raft.RequestVote", &args, ...)
+ // handle the reply...
+ } ()
+ }
+ rf.mu.Unlock()
+
+这段代码在单独的 goroutine 中发送每个 RPC。错误在于 args.Term 可能与外层代码决定成为 Candidate 时的 rf.currentTerm 不一致。从外层创建 goroutine 到 goroutine 读取 rf.currentTerm 可能过了很久;例如可能经过多个 term,该节点可能已不再是 candidate。一种修复方式是让创建的 goroutine 使用外层代码持锁时复制的 rf.currentTerm。类似地,Call() 之后的回复处理代码在重新获取锁后必须重新检查所有相关假设;例如应检查 rf.currentTerm 自决定成为 candidate 以来是否已改变。
diff --git a/docs/papers/raft-locking.txt b/docs/papers/raft-locking.txt
new file mode 100644
index 0000000..af9c071
--- /dev/null
+++ b/docs/papers/raft-locking.txt
@@ -0,0 +1,54 @@
+Raft Locking Advice
+
+If you are wondering how to use locks in the 6.824 Raft labs, here are some rules and ways of thinking that might be helpful.
+
+Rule 1: Whenever you have data that more than one goroutine uses, and at least one goroutine might modify the data, the goroutines should use locks to prevent simultaneous use of the data. The Go race detector is pretty good at detecting violations of this rule (though it won't help with any of the rules below).
+
+Rule 2: Whenever code makes a sequence of modifications to shared data, and other goroutines might malfunction if they looked at the data midway through the sequence, you should use a lock around the whole sequence.
+
+An example:
+
+ rf.mu.Lock()
+ rf.currentTerm += 1
+ rf.state = Candidate
+ rf.mu.Unlock()
+
+It would be a mistake for another goroutine to see either of these updates alone (i.e. the old state with the new term, or the new term with the old state). So we need to hold the lock continuously over the whole sequence of updates. All other code that uses rf.currentTerm or rf.state must also hold the lock, in order to ensure exclusive access for all uses.
+
+The code between Lock() and Unlock() is often called a "critical section." The locking rules a programmer chooses (e.g. "a goroutine must hold rf.mu when using rf.currentTerm or rf.state") are often called a "locking protocol".
+
+Rule 3: Whenever code does a sequence of reads of shared data (or reads and writes), and would malfunction if another goroutine modified the data midway through the sequence, you should use a lock around the whole sequence.
+
+An example that could occur in a Raft RPC handler:
+
+ rf.mu.Lock()
+ if args.Term > rf.currentTerm {
+ rf.currentTerm = args.Term
+ }
+ rf.mu.Unlock()
+
+This code needs to hold the lock continuously for the whole sequence. Raft requires that currentTerm only increases, and never decreases. Another RPC handler could be executing in a separate goroutine; if it were allowed to modify rf.currentTerm between the if statement and the update to rf.currentTerm, this code might end up decreasing rf.currentTerm. Hence the lock must be held continuously over the whole sequence. In addition, every other use of currentTerm must hold the lock, to ensure that no other goroutine modifies currentTerm during our critical section.
+
+Real Raft code would need to use longer critical sections than these examples; for example, a Raft RPC handler should probably hold the lock for the entire handler.
+
+Rule 4: It's usually a bad idea to hold a lock while doing anything that might wait: reading a Go channel, sending on a channel, waiting for a timer, calling time.Sleep(), or sending an RPC (and waiting for the reply). One reason is that you probably want other goroutines to make progress during the wait. Another reason is deadlock avoidance. Imagine two peers sending each other RPCs while holding locks; both RPC handlers need the receiving peer's lock; neither RPC handler can ever complete because it needs the lock held by the waiting RPC call.
+
+Code that waits should first release locks. If that's not convenient, sometimes it's useful to create a separate goroutine to do the wait.
+
+Rule 5: Be careful about assumptions across a drop and re-acquire of a lock. One place this can arise is when avoiding waiting with locks held. For example, this code to send vote RPCs is incorrect:
+
+ rf.mu.Lock()
+ rf.currentTerm += 1
+ rf.state = Candidate
+ for {
+ go func() {
+ rf.mu.Lock()
+ args.Term = rf.currentTerm
+ rf.mu.Unlock()
+ Call("Raft.RequestVote", &args, ...)
+ // handle the reply...
+ } ()
+ }
+ rf.mu.Unlock()
+
+The code sends each RPC in a separate goroutine. It's incorrect because args.Term may not be the same as the rf.currentTerm at which the surrounding code decided to become a Candidate. Lots of time may pass between when the surrounding code creates the goroutine and when the goroutine reads rf.currentTerm; for example, multiple terms may come and go, and the peer may no longer be a candidate. One way to fix this is for the created goroutine to use a copy of rf.currentTerm made while the outer code holds the lock. Similarly, reply-handling code after the Call() must re-check all relevant assumptions after re-acquiring the lock; for example, it should check that rf.currentTerm hasn't changed since the decision to become a candidate.
diff --git a/docs/papers/raft-structure-cn.txt b/docs/papers/raft-structure-cn.txt
new file mode 100644
index 0000000..814ce50
--- /dev/null
+++ b/docs/papers/raft-structure-cn.txt
@@ -0,0 +1,15 @@
+Raft 结构建议
+
+一个 Raft 实例需要应对外部事件的到达(Start() 调用、AppendEntries 与 RequestVote RPC、以及 RPC 回复),并执行周期性任务(选举与心跳)。组织 Raft 代码来管理这些活动的方式很多;本文档简述几种思路。
+
+每个 Raft 实例有一批状态(log、current index 等),需要在并发 goroutine 产生的事件下更新。Go 文档指出,goroutine 可以直接用共享数据结构和锁来更新,也可以通过 channel 传递消息。经验表明,对 Raft 而言最直接的是使用共享数据和锁。
+
+一个 Raft 实例有两种由时间驱动的活动:leader 必须发送心跳,其他节点在超过一定时间未收到 leader 消息后必须发起选举。最好用各自独立的长驻 goroutine 驱动这两种活动,而不是把多种活动塞进一个 goroutine。
+
+选举超时的管理常是头疼来源。或许最简单的做法是在 Raft 结构体里维护一个变量,记录该节点上次收到 leader 消息的时间,并让选举超时 goroutine 定期检查自那时起是否已超过超时时间。用带小常数的 time.Sleep() 驱动定期检查最简单。不要用 time.Ticker 和 time.Timer;它们容易用错。
+
+你需要一个独立的长驻 goroutine,按顺序在 applyCh 上发送已提交的日志条目。它必须独立,因为向 applyCh 发送可能阻塞;且必须是单个 goroutine,否则很难保证按日志顺序发送。推进 commitIndex 的代码需要唤醒 apply goroutine;用条件变量(Go 的 sync.Cond)通常最简单。
+
+每个 RPC 最好在各自的 goroutine 中发送(并处理回复),原因有二:让不可达的节点不会拖慢收集多数回复;让心跳和选举定时器随时都能继续走。在同一 goroutine 里处理 RPC 回复最简单,而不是通过 channel 传递回复信息。
+
+要记住网络会延迟 RPC 和 RPC 回复,而且在并发发送 RPC 时,网络可能重排请求和回复。Figure 2 在指出 RPC handler 需要小心的地方(例如应忽略旧 term 的 RPC)方面写得不错。Figure 2 对 RPC 回复处理的说明并不总是显式。Leader 在处理回复时必须小心:必须检查自发送 RPC 以来 term 是否已变,并必须考虑对同一 follower 的并发 RPC 的回复可能已改变 leader 的状态(例如 nextIndex)。
diff --git a/docs/papers/raft-structure.txt b/docs/papers/raft-structure.txt
new file mode 100644
index 0000000..9bf6bd1
--- /dev/null
+++ b/docs/papers/raft-structure.txt
@@ -0,0 +1,15 @@
+Raft Structure Advice
+
+A Raft instance has to deal with the arrival of external events (Start() calls, AppendEntries and RequestVote RPCs, and RPC replies), and it has to execute periodic tasks (elections and heart-beats). There are many ways to structure your Raft code to manage these activities; this document outlines a few ideas.
+
+Each Raft instance has a bunch of state (the log, the current index, &c) which must be updated in response to events arising in concurrent goroutines. The Go documentation points out that the goroutines can perform the updates directly using shared data structures and locks, or by passing messages on channels. Experience suggests that for Raft it is most straightforward to use shared data and locks.
+
+A Raft instance has two time-driven activities: the leader must send heart-beats, and others must start an election if too much time has passed since hearing from the leader. It's probably best to drive each of these activities with a dedicated long-running goroutine, rather than combining multiple activities into a single goroutine.
+
+The management of the election timeout is a common source of headaches. Perhaps the simplest plan is to maintain a variable in the Raft struct containing the last time at which the peer heard from the leader, and to have the election timeout goroutine periodically check to see whether the time since then is greater than the timeout period. It's easiest to use time.Sleep() with a small constant argument to drive the periodic checks. Don't use time.Ticker and time.Timer; they are tricky to use correctly.
+
+You'll want to have a separate long-running goroutine that sends committed log entries in order on the applyCh. It must be separate, since sending on the applyCh can block; and it must be a single goroutine, since otherwise it may be hard to ensure that you send log entries in log order. The code that advances commitIndex will need to kick the apply goroutine; it's probably easiest to use a condition variable (Go's sync.Cond) for this.
+
+Each RPC should probably be sent (and its reply processed) in its own goroutine, for two reasons: so that unreachable peers don't delay the collection of a majority of replies, and so that the heartbeat and election timers can continue to tick at all times. It's easiest to do the RPC reply processing in the same goroutine, rather than sending reply information over a channel.
+
+Keep in mind that the network can delay RPCs and RPC replies, and when you send concurrent RPCs, the network can re-order requests and replies. Figure 2 is pretty good about pointing out places where RPC handlers have to be careful about this (e.g. an RPC handler should ignore RPCs with old terms). Figure 2 is not always explicit about RPC reply processing. The leader has to be careful when processing replies; it must check that the term hasn't changed since sending the RPC, and must account for the possibility that replies from concurrent RPCs to the same follower have changed the leader's state (e.g. nextIndex).
diff --git a/docs/papers/raft_diagram.pdf b/docs/papers/raft_diagram.pdf
new file mode 100644
index 0000000..29c93d1
Binary files /dev/null and b/docs/papers/raft_diagram.pdf differ