454 lines
32 KiB
Markdown
454 lines
32 KiB
Markdown
# MapReduce:大规模集群上的简化数据处理
|
||
|
||
**Jeffrey Dean and Sanjay Ghemawat** jeff@google.com, sanjay@google.com
|
||
Google, Inc.
|
||
|
||
*OSDI '04: 6th Symposium on Operating Systems Design and Implementation — USENIX Association*
|
||
|
||
---
|
||
|
||
## 摘要
|
||
|
||
MapReduce 是一种用于处理与生成大规模数据集的编程模型及其相关实现。用户指定一个 map 函数,用于处理 key/value 对并生成一组中间 key/value 对;以及一个 reduce 函数,用于合并与同一中间 key 关联的所有中间 value。如本文所示,许多现实任务都可以用该模型表达。
|
||
|
||
以这种函数式风格编写的程序会被自动并行化,并在由大量商用机构成的大规模集群上执行。运行时系统负责:对输入数据分区、在多台机器上调度程序执行、处理机器故障以及管理所需的机器间通信。这样,没有并行与分布式系统经验的程序员也能轻松利用大规模分布式系统的资源。
|
||
|
||
我们的 MapReduce 实现运行在由大量商用机构成的大规模集群上,并具有很好的可扩展性:典型的 MapReduce 计算会在数千台机器上处理数 TB 级数据。程序员认为该系统易于使用:已有数百个 MapReduce 程序被实现,每天在 Google 的集群上执行的 MapReduce 作业超过一千个。
|
||
|
||
---
|
||
|
||
## 1 引言
|
||
|
||
在过去五年中,本文作者与 Google 的许多其他人实现了数百种专用计算,用于处理大量原始数据(如爬取的文档、Web 请求日志等),并生成各类派生数据(如倒排 index、Web 文档图结构的多种表示、按 host 爬取页面数汇总、某日最常见查询集合等)。这类计算在概念上大多很直接,但输入数据通常很大,计算不得不分布在数百或数千台机器上才能在合理时间内完成。如何并行化计算、如何分布数据、如何应对故障等问题交织在一起,用大量处理这些问题的复杂代码掩盖了原本简单的计算逻辑。
|
||
|
||
针对这种复杂性,我们设计了一种新的抽象:既能表达我们想要执行的简单计算,又把并行化、容错、数据分布与负载均衡等繁琐细节隐藏在库中。该抽象受到 Lisp 及许多其他函数式语言中 map 与 reduce 原语的启发。我们意识到,我们的大多数计算都对输入中的每条逻辑「record」施加一次 map 操作,得到一组中间 key/value 对,再对共享同一 key 的所有 value 施加一次 reduce 操作,以恰当方式合并派生数据。采用由用户指定 map 与 reduce 操作的函数式模型,使我们能轻松并行化大规模计算,并以重新执行作为容错的主要机制。
|
||
|
||
本工作的主要贡献是:一个简单而强大的接口,能够自动并行化与分布大规模计算;以及该接口的一种实现,在由大量商用 PC 构成的大规模集群上达到高性能。
|
||
|
||
- 第 2 节描述基本编程模型并给出若干示例。
|
||
- 第 3 节描述针对我们基于集群的计算环境定制的 MapReduce 接口实现。
|
||
- 第 4 节描述我们觉得有用的若干编程模型改进。
|
||
- 第 5 节给出我们在多种任务上的性能测量结果。
|
||
- 第 6 节探讨 MapReduce 在 Google 内的使用,包括以其为基础重写生产 index 系统的经验。
|
||
- 第 7 节讨论相关工作与未来工作。
|
||
|
||
---
|
||
|
||
## 2 编程模型
|
||
|
||
计算以一组输入 key/value 对为输入,产生一组输出 key/value 对。MapReduce 库的用户将计算表示为两个函数:**Map** 和 **Reduce**。
|
||
|
||
由用户编写的 **Map** 接受一个输入对,产生一组中间 key/value 对。MapReduce 库把所有与同一中间 key *I* 关联的中间 value 归为一组,并将它们传给 Reduce 函数。
|
||
|
||
同样由用户编写的 **Reduce** 函数接受一个中间 key *I* 以及该 key 的一组 value。它将这组 value 合并成可能更小的一组 value。通常每次 Reduce 调用只产生零个或一个输出 value。中间 value 通过 iterator 提供给用户的 reduce 函数,从而可以处理因过大而无法放入内存的 value 列表。
|
||
|
||
### 2.1 示例
|
||
|
||
考虑在大规模文档集合中统计每个词出现次数的问题。用户会编写与下面伪代码类似的代码:
|
||
|
||
```java
|
||
map(String key, String value):
|
||
// key: document name
|
||
// value: document contents
|
||
for each word w in value:
|
||
EmitIntermediate(w, "1");
|
||
|
||
reduce(String key, Iterator values):
|
||
// key: a word
|
||
// values: a list of counts
|
||
int result = 0;
|
||
for each v in values:
|
||
result += ParseInt(v);
|
||
Emit(AsString(result));
|
||
```
|
||
|
||
map 函数对每个词输出其出现次数(在本例中简单地为 '1')。reduce 函数将同一词的所有计数相加。
|
||
|
||
此外,用户还需编写代码,在 mapreduce 的 specification 对象中填入输入、输出文件名以及可选的调优参数,然后调用 MapReduce 函数并传入该 specification 对象。用户代码与 MapReduce 库(以 C++ 实现)链接在一起。附录 A 给出该示例的完整程序文本。
|
||
|
||
### 2.2 类型
|
||
|
||
尽管上述伪代码以 string 的输入输出书写,从概念上用户提供的 map 与 reduce 函数具有如下类型:
|
||
|
||
- **map**: (k1, v1) → list(k2, v2)
|
||
- **reduce**: (k2, list(v2)) → list(v2)
|
||
|
||
即输入 key、value 与输出 key、value 来自不同的域,而中间 key、value 与输出 key、value 来自同一域。
|
||
|
||
我们的 C++ 实现在用户定义函数之间以 string 传递数据,由用户代码负责在 string 与适当类型之间转换。
|
||
|
||
### 2.3 更多示例
|
||
|
||
下面是一些可以轻松表达为 MapReduce 计算的有趣程序的简单示例。
|
||
|
||
| 示例 | 描述 |
|
||
|------|------|
|
||
| **Distributed Grep** | map 函数在行匹配给定 pattern 时输出该行;reduce 函数是恒等函数,仅将提供的中间数据复制到输出。 |
|
||
| **Count of URL Access Frequency** | map 函数处理 Web 页面请求日志,输出 〈URL, 1〉;reduce 函数对同一 URL 的所有 value 求和,并输出 〈URL, total count〉 对。 |
|
||
| **Reverse Web-Link Graph** | map 函数对在名为 source 的页面中发现的每个指向 target URL 的链接输出 〈target, source〉 对;reduce 函数将给定 target URL 对应的所有 source URL 拼接成列表,并输出 〈target, list(source)〉。 |
|
||
| **Term-Vector per Host** | term vector 将文档或文档集合中出现的最重要词概括为 〈word, frequency〉 对的列表。map 函数对每份输入文档(hostname 从文档 URL 中提取)输出一个 〈hostname, term vector〉 对。reduce 函数接收给定 host 下每文档的 term vector,将它们相加、丢弃低频词,然后输出最终的 〈hostname, term vector〉 对。 |
|
||
| **Inverted Index** | map 函数解析每份文档并输出一系列 〈word, document ID〉 对;reduce 函数接受给定词的所有对,对相应 document ID 排序并输出 〈word, list(document ID)〉。所有输出对的集合即构成简单的 inverted index。很容易扩展该计算以记录词位置。 |
|
||
| **Distributed Sort** | map 函数从每条 record 中提取 key,并输出 〈key, record〉 对;reduce 函数原样输出所有对。该计算依赖于第 4.1 节的分区设施与第 4.2 节的顺序性质。 |
|
||
|
||
|
||
|
||
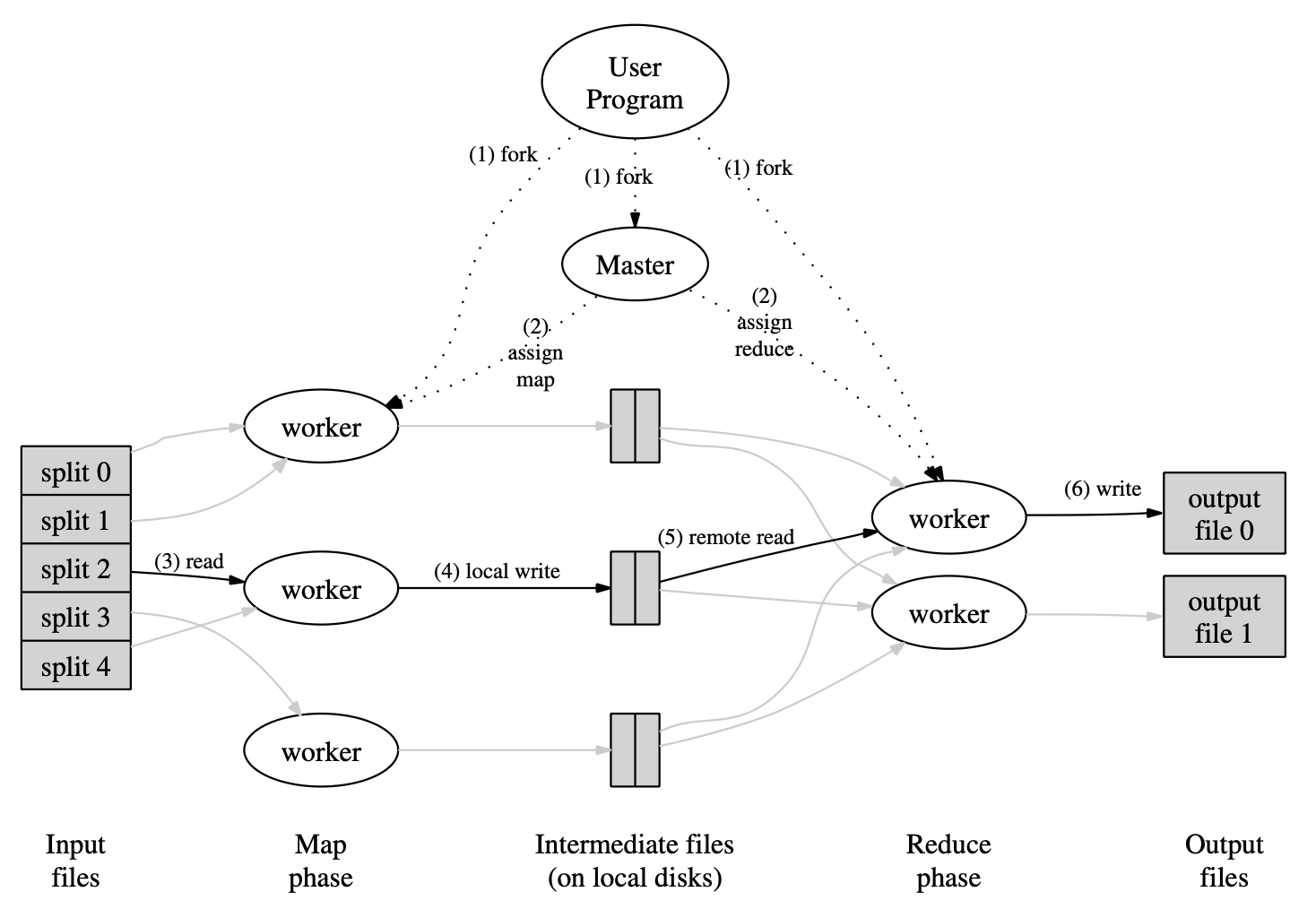
**图 1:执行概览**
|
||
|
||
---
|
||
|
||
## 3 实现
|
||
|
||
MapReduce 接口可以有多种不同实现,合适的选择取决于运行环境。例如,一种实现可能适用于小型共享内存机器,另一种适用于大型 NUMA 多处理器,再一种适用于更大规模的联网机器集群。
|
||
|
||
本节描述的实现面向 Google 广泛使用的计算环境:由交换机以太网 [4] 连接的大规模商用 PC 集群。在我们的环境中:
|
||
|
||
1. 机器通常是双路 x86 处理器、运行 Linux,每台机器 2–4 GB 内存。
|
||
2. 使用商用网络硬件——机器层面通常是 100 Mb/s 或 1 Gb/s,但整体二分带宽平均要低不少。
|
||
3. 集群由数百或数千台机器组成,因此机器故障很常见。
|
||
4. 存储由直接挂载到单机的廉价 IDE 磁盘提供;使用内部开发的分布式文件系统 [8] 管理这些磁盘上的数据,通过复制在不可靠硬件上提供可用性与可靠性。
|
||
5. 用户向调度系统提交作业;每个作业由一组 task 组成,由调度器映射到集群内一组可用机器。
|
||
|
||
### 3.1 执行概览
|
||
|
||
通过将输入数据自动划分为 *M* 个 split,Map 调用被分布到多台机器上;这些 input split 可由不同机器并行处理。Reduce 调用则通过对中间 key 空间用分区函数(如 hash(key) mod R)划分为 *R* 块来分布。分区数 R 与分区函数由用户指定。
|
||
|
||
当用户程序调用 MapReduce 函数时,将发生以下动作序列(图 1 中的编号与下列序号对应):
|
||
|
||
1. **划分输入**:用户程序中的 MapReduce 库先将输入文件切分为 M 块,每块通常 16 MB 到 64 MB(可由用户通过可选参数控制),然后在集群上启动程序的多个副本。
|
||
2. **Master 与 worker**:其中一份程序副本是特殊的——即 master,其余为由 master 分配工作的 worker。共有 M 个 map task 和 R 个 reduce task 需要分配。Master 挑选空闲 worker,为每个分配一个 map task 或一个 reduce task。
|
||
3. **Map worker**:被分配到 map task 的 worker 读取对应 input split 的内容,从输入数据中解析出 key/value 对,并把每一对传给用户定义的 Map 函数。Map 函数产生的中间 key/value 对先缓存在内存中。
|
||
4. **定期刷写**:缓存的配对会定期写入本地磁盘,并依分区函数划分为 R 个区域。这些缓存在本地磁盘上的位置会回传给 master,由 master 负责将这些位置转发给 reduce worker。
|
||
5. **Reduce worker 读取**:当 reduce worker 被 master 通知这些位置后,它通过远程过程调用从 map worker 的本地磁盘读取缓冲数据。当 reduce worker 读完全部中间数据后,按中间 key 排序,使相同 key 的所有出现聚在一起。排序是必要的,因为通常多个不同 key 会映射到同一 reduce task。若中间数据量过大无法放入内存,则使用外部排序。
|
||
6. **Reduce**:reduce worker 遍历排序后的中间数据,对遇到的每个唯一中间 key,将 key 与对应的中间 value 集合传给用户的 Reduce 函数。Reduce 函数的输出被追加到该 reduce 分区的最终输出文件中。
|
||
7. **完成**:当所有 map task 和 reduce task 都完成后,master 唤醒用户程序;此时用户程序中的 MapReduce 调用返回到用户代码。
|
||
|
||
成功完成后,mapreduce 执行的输出位于 R 个输出文件中(每个 reduce task 一个,文件名由用户指定)。通常用户不需要将这 R 个输出文件合并为一个——它们常被作为另一次 MapReduce 调用的输入,或供能处理多文件分区的其他分布式应用使用。
|
||
|
||
### 3.2 Master 数据结构
|
||
|
||
Master 维护若干数据结构。对每个 map task 和 reduce task,它保存其状态(idle、in-progress 或 completed)以及 worker 机器标识(对非 idle 的 task)。
|
||
|
||
Master 是 map task 产生的中间文件区域位置传播到 reduce task 的通道。因此,对每个已完成的 map task,master 保存该 map task 产生的 R 个中间文件区域的位置与大小。随着 map task 完成,会收到对这些位置与大小信息的更新,并增量推送给正在进行 reduce task 的 worker。
|
||
|
||
### 3.3 容错
|
||
|
||
由于 MapReduce 库被设计为在数百或数千台机器上处理海量数据,库必须能妥善应对机器故障。
|
||
|
||
#### Worker 故障
|
||
|
||
Master 定期 ping 每个 worker。若在约定时间内未收到某 worker 的响应,master 将该 worker 标记为失败。该 worker 已完成的任何 map task 会被重置为初始 idle 状态,从而可被调度到其他 worker。同样,在该故障 worker 上正在执行的任何 map 或 reduce task 也会被重置为 idle 并可供重新调度。
|
||
|
||
已完成的 map task 在故障时会重新执行,因为其输出保存在故障机器的本地磁盘上而无法访问。已完成的 reduce task 不需要重新执行,因为其输出保存在全局文件系统中。
|
||
|
||
当某 map task 先由 worker A 执行、后因 A 故障又由 worker B 执行时,所有正在执行 reduce task 的 worker 会收到重新执行的通知;尚未从 worker A 读取数据的 reduce task 将从 worker B 读取数据。
|
||
|
||
MapReduce 能应对大规模 worker 故障。例如,在一次 MapReduce 运行期间,对运行中集群的网络维护导致每次约 80 台机器在数分钟内不可达;MapReduce 的 master 只需重新执行这些不可达 worker 已完成的工作,并继续推进,最终完成该次 MapReduce 操作。
|
||
|
||
#### Master 故障
|
||
|
||
可以很容易地让 master 对上述 master 数据结构做定期 checkpoint。若 master 进程退出,可从最近一次 checkpoint 状态启动新副本。但由于只有一个 master,其故障概率较低,我们当前实现中若 master 故障则中止该次 MapReduce 计算;客户端可检测该情况并按需重试 MapReduce 操作。
|
||
|
||
#### 故障下的语义
|
||
|
||
当用户提供的 map 与 reduce 算子对其输入是确定性函数时,我们的分布式实现产生的输出与整个程序在无故障顺序执行下将产生的输出相同。
|
||
|
||
我们依赖 map 与 reduce task 输出的原子提交来保证这一点。每个进行中的 task 将其输出写入私有临时文件:reduce task 产生一个此类文件,map task 产生 R 个(每个 reduce task 一个)。map task 完成时,worker 向 master 发送消息,其中包含这 R 个临时文件的名称。若 master 收到的是关于一个已完成 map task 的完成消息,则忽略;否则将该 R 个文件名记入 master 数据结构。
|
||
|
||
reduce task 完成时,reduce worker 将其临时输出文件原子地重命名为最终输出文件。若同一 reduce task 在多台机器上执行,会对同一最终输出文件执行多次 rename;我们依赖底层文件系统提供的原子 rename 操作,保证最终文件系统状态中只包含该 reduce task 一次执行产生的数据。
|
||
|
||
我们绝大多数 map 与 reduce 算子都是确定性的,此时语义与顺序执行等价,便于程序员推理程序行为。当 map 和/或 reduce 算子非确定性时,我们提供较弱但仍合理的语义(详见论文)。
|
||
|
||
### 3.4 局部性
|
||
|
||
在我们的计算环境中,网络带宽是相对稀缺的资源。我们利用输入数据(由 GFS [8] 管理)存储在组成集群的机器本地磁盘上这一事实来节省网络带宽。GFS 将每个文件划分为 64 MB 的 block,并在不同机器上保存每个 block 的若干副本(通常 3 份)。MapReduce 的 master 会考虑输入文件的位置信息,尽量在包含对应输入数据副本的机器上调度 map task;若做不到,则尽量在靠近该 task 输入数据副本的机器上调度(例如与存有数据的机器在同一台网络交换机上的 worker)。在集群中相当比例的 worker 上运行大型 MapReduce 操作时,大部分输入数据从本地读取,不占用网络带宽。
|
||
|
||
### 3.5 任务粒度
|
||
|
||
如上所述,我们将 map 阶段细分为 M 份、reduce 阶段细分为 R 份。理想情况下 M 和 R 应远大于 worker 机器数。让每个 worker 执行多种 task 有利于动态负载均衡,也能在 worker 故障时加快恢复:该 worker 已完成的众多 map task 可分散到其他所有 worker 上重新执行。
|
||
|
||
在我们的实现中,M 和 R 的大小有实际限制,因为 master 需要做 O(M + R) 次调度决策并如上所述在内存中维护 O(M × R) 的状态。(但内存占用的常数因子很小:O(M × R) 部分约为每个 map task/reduce task 对一字节。)
|
||
|
||
此外,R 常受用户约束,因为每个 reduce task 的输出最终进入单独的输出文件。实践中我们倾向于将 M 选为每个 task 约 16 MB 到 64 MB 输入数据(使上述局部性优化最有效),并将 R 设为预期使用的 worker 数量的较小倍数。我们常以 M = 200,000、R = 5,000、使用 2,000 台 worker 机器执行 MapReduce 计算。
|
||
|
||
### 3.6 备份任务
|
||
|
||
导致 MapReduce 操作总时间延长的一个常见原因是「掉队者」:某台机器完成计算中最后几个 map 或 reduce task 之一时异常缓慢。掉队者可能由多种原因造成(如坏盘、资源竞争、bug)。
|
||
|
||
我们有一种通用机制来缓解掉队者问题。当 MapReduce 操作接近完成时,master 会为剩余进行中的 task 调度备份执行。只要主执行或备份执行之一完成,该 task 即标记为已完成。我们已将该机制调优为通常仅使操作使用的计算资源增加几个百分点。实践表明,这能显著缩短完成大型 MapReduce 操作的时间。例如,第 5.3 节描述的 sort 程序在关闭备份 task 机制时,完成时间要长 44%。
|
||
|
||
---
|
||
|
||
## 4 改进
|
||
|
||
尽管仅编写 Map 和 Reduce 函数提供的基本功能对大多数需求已足够,我们发现若干扩展很有用。本节描述这些扩展。
|
||
|
||
### 4.1 分区函数
|
||
|
||
MapReduce 的用户指定期望的 reduce task/输出文件数量 R。数据通过基于中间 key 的分区函数分布到这些 task。我们提供默认分区函数,采用哈希(如 "hash(key) mod R"),往往得到较均衡的分区。但在某些情况下,按 key 的其它函数分区更有用。例如,使用 "hash(Hostname(urlkey)) mod R" 作为分区函数可使同一 host 的所有 URL 落入同一输出文件。
|
||
|
||
### 4.2 顺序保证
|
||
|
||
我们保证在给定分区内,中间 key/value 对按 key 递增顺序被处理。这一顺序保证便于按分区生成有序输出文件,在输出文件格式需要支持按 key 的高效随机访问、或输出的使用者希望数据已排序时很有用。
|
||
|
||
### 4.3 Combiner 函数
|
||
|
||
有时每个 map task 产生的中间 key 存在大量重复,且用户指定的 Reduce 函数可交换、可结合。我们允许用户指定可选的 **Combiner** 函数,在数据通过网络发送前对其进行部分合并。Combiner 函数在每台执行 map task 的机器上运行。通常用同一段代码同时实现 combiner 与 reduce 函数。部分合并能显著加速某类 MapReduce 操作。附录 A 包含使用 combiner 的示例。
|
||
|
||
### 4.4 输入与输出类型
|
||
|
||
MapReduce 库支持以多种格式读取输入(例如 "text" 模式将每行视为一个 key/value 对)。用户可通过实现简单的 reader 接口来支持新的输入类型。类似地,我们支持多种输出类型以产生不同格式的数据。
|
||
|
||
### 4.5 副作用
|
||
|
||
有时 MapReduce 用户希望从 map 和/或 reduce 算子产生辅助文件作为额外输出。我们依赖应用作者使这类副作用具有原子性与幂等性;通常做法是写入临时文件,在完全生成后原子地重命名该文件。
|
||
|
||
### 4.6 跳过坏记录
|
||
|
||
有时用户代码中的 bug 会使 Map 或 Reduce 函数在特定 record 上确定性地崩溃。我们提供一种可选执行模式:MapReduce 库检测导致确定性崩溃的 record,并跳过这些 record 以继续推进。每个 worker 进程安装 signal handler 捕获段错误与总线错误;在调用用户代码前保存参数的序列号;发生 signal 时向 master 发送「最后一息」UDP 包;当 master 对某条 record 看到超过一次失败时,会在下次重新执行时标记跳过该 record。
|
||
|
||
### 4.7 本地执行
|
||
|
||
为便于调试、性能剖析与小规模测试,我们实现了 MapReduce 库的另一种版本,在单机上顺序执行一次 MapReduce 操作的全部工作。用户可将计算限制在特定的 map task 上。用户使用特殊 flag 启动程序后,即可方便地使用任何调试或测试工具(如 gdb)。
|
||
|
||
### 4.8 状态信息
|
||
|
||
Master 运行内部 HTTP 服务并导出一组供人查看的状态页。状态页展示计算进度,如已完成与进行中的 task 数、输入/中间/输出字节数、处理速率等。页面还包含各 task 生成的标准错误与标准输出文件的链接。
|
||
|
||
### 4.9 计数器
|
||
|
||
MapReduce 库提供计数器功能以统计各类事件。用户代码创建具名 counter 对象,并在 Map 和/或 Reduce 函数中适当增加计数。示例:
|
||
|
||
```cpp
|
||
Counter* uppercase;
|
||
uppercase = GetCounter("uppercase");
|
||
map(String name, String contents):
|
||
for each word w in contents:
|
||
if (IsCapitalized(w)):
|
||
uppercase->Increment();
|
||
EmitIntermediate(w, "1");
|
||
```
|
||
|
||
各 worker 机器上的 counter 值会定期传播到 master(搭载在 ping 响应上)。Master 汇总成功完成的 map 与 reduce task 的 counter 值,在 MapReduce 操作完成时返回给用户代码。部分 counter 值由 MapReduce 库自动维护,如已处理的输入 key/value 对数量与产生的输出 key/value 对数量。
|
||
|
||
---
|
||
|
||
## 5 性能
|
||
|
||
本节我们在大型机器集群上对两种计算测量 MapReduce 的性能:一种在约 1 TB 数据中搜索特定 pattern;另一种对约 1 TB 数据进行排序。
|
||
|
||
### 5.1 集群配置
|
||
|
||
所有程序在约 1800 台机器组成的集群上运行。每台机器为双路 2GHz Intel Xeon、开启 Hyper-Threading、4GB 内存、两块 160GB IDE 盘、千兆以太网。机器组成两层树形交换网络,根处聚合带宽约 100–200 Gbps。所有机器在同一托管设施内,任意两台机器间往返时延小于 1 毫秒。4GB 内存中约 1–1.5GB 被集群上其他任务占用。程序在周末下午运行,此时 CPU、磁盘与网络大多空闲。
|
||
|
||
### 5.2 Grep
|
||
|
||
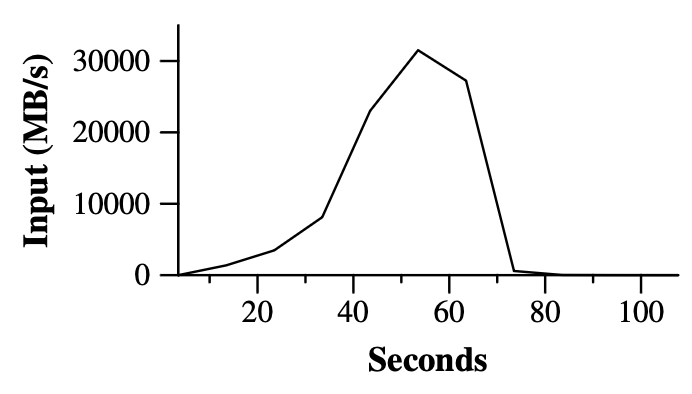
grep 程序扫描 10^10 条 100 字节的 record,搜索一个相对罕见的三字符 pattern(该 pattern 在 92,337 条 record 中出现)。输入被切分为约 64MB 的块(M = 15000),整个输出放在一个文件中(R = 1)。
|
||
|
||
|
||
|
||
**图 2:随时间的数据传输速率**
|
||
|
||
### 5.3 Sort
|
||
|
||
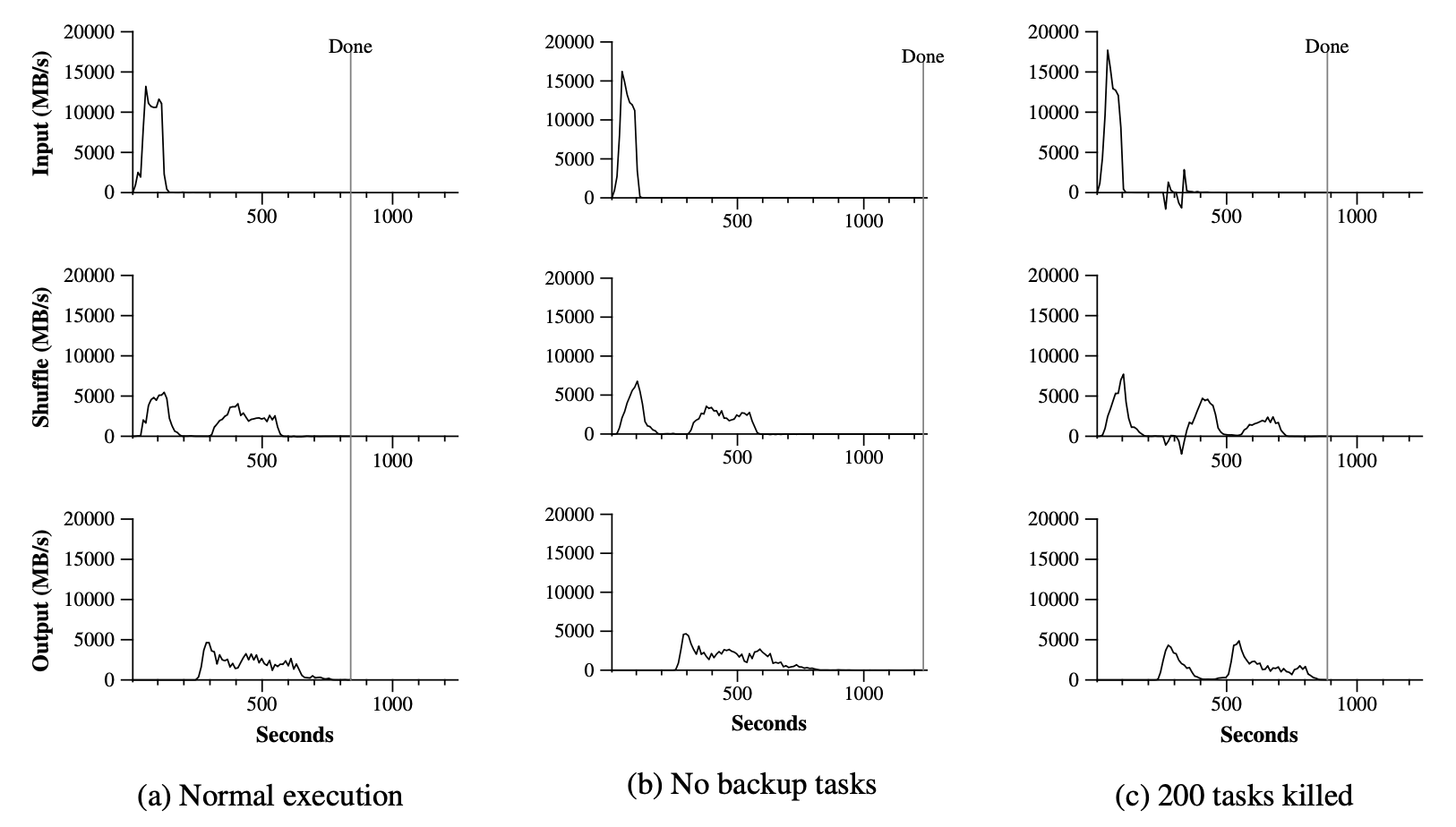
sort 程序对 10^10 条 100 字节的 record(约 1 TB 数据)排序,该程序仿照 TeraSort benchmark [10]。排序程序用户代码不足 50 行:三行 Map 函数从文本行中提取 10 字节的排序 key,并输出 key 与原始文本行作为中间 key/value 对;我们使用内置的 Identity 函数作为 Reduce 算子。输入数据切分为 64MB 块(M = 15000),排序输出划分为 4000 个文件(R = 4000)。
|
||
|
||
|
||
|
||
**图 3:sort 程序不同执行随时间的数据传输速率**
|
||
|
||
### 5.4 备份任务的效果
|
||
|
||
关闭备份任务时,执行会出现很长的尾部,期间几乎没有任何写活动。960 秒后,除 5 个外的所有 reduce task 都已完成,但最后几个掉队者直到 300 秒后才完成。整个计算耗时 1283 秒,比启用时增加 44%。
|
||
|
||
### 5.5 机器故障
|
||
|
||
在一次执行中,我们在计算开始数分钟后故意终止 1746 个 worker 进程中的 200 个。Worker 的终止体现为负的输入速率,因为部分先前完成的 map 工作消失并需要重做。这部分 map 工作的重新执行相对较快。包含启动开销在内,整个计算在 933 秒内完成(相对正常执行时间仅增加约 5%)。
|
||
|
||
---
|
||
|
||
## 6 经验
|
||
|
||
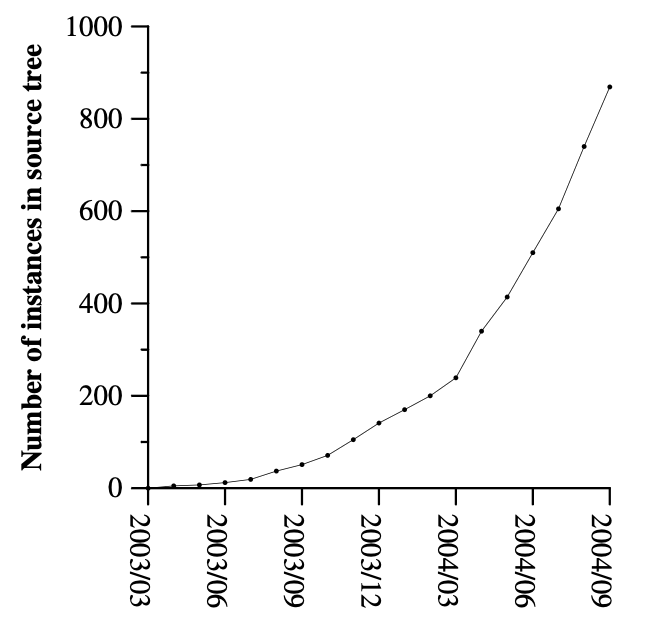
我们在 2003 年 2 月完成 MapReduce 库的第一个版本,并在 2003 年 8 月做了重要增强。此后,MapReduce 在 Google 内部被广泛应用于多个领域,包括:
|
||
|
||
- 大规模机器学习问题;
|
||
- Google News 与 Froogle 产品的聚类问题;
|
||
- 用于生成热门查询报告的数据提取(如 Google Zeitgeist);
|
||
- 从 Web 页面提取属性以支持新实验与产品;
|
||
- 以及大规模图计算。
|
||
|
||
|
||
|
||
**图 4:MapReduce 实例随时间变化** — 从 2003 年初的 0 增长到 2004 年 9 月末的近 900 个独立实例。
|
||
|
||
| 指标 | 数值 |
|
||
|------|------|
|
||
| Number of jobs | 29,423 |
|
||
| Average job completion time | 634 secs |
|
||
| Machine days used | 79,186 days |
|
||
| Input data read | 3,288 TB |
|
||
| Intermediate data produced | 758 TB |
|
||
| Output data written | 193 TB |
|
||
| Average worker machines per job | 157 |
|
||
| Average worker deaths per job | 1.2 |
|
||
| Average map tasks per job | 3,351 |
|
||
| Average reduce tasks per job | 55 |
|
||
| Unique map implementations | 395 |
|
||
| Unique reduce implementations | 269 |
|
||
| Unique map/reduce combinations | 426 |
|
||
|
||
**表 1:** 2004 年 8 月运行的 MapReduce 作业统计
|
||
|
||
### 6.1 大规模索引
|
||
|
||
我们迄今对 MapReduce 最重要的应用之一,是对生产 index 系统的完整重写——该系统生成 Google Web 搜索服务所用的数据结构。index 系统以大量文档为输入(原始内容超过 20 TB)。index 过程以五到十次 MapReduce 操作的序列运行。带来的好处包括:
|
||
|
||
- index 代码更简单、更短、更易理解(例如,某一阶段从约 3800 行 C++ 在用 MapReduce 表达后降至约 700 行);
|
||
- MapReduce 库的性能足够好,我们能把概念上无关的计算分开,便于修改 index 流程;
|
||
- index 过程的运维简单得多,因为机器故障、慢机与网络抖动等问题大多由 MapReduce 库自动处理。
|
||
|
||
---
|
||
|
||
## 7 相关工作
|
||
|
||
许多系统通过限制编程模型并利用这些限制自动并行化计算。基于我们在大型实际计算上的经验,MapReduce 可视为这类模型的简化与提炼。更重要的是,我们提供了可扩展到数千处理器的容错实现。
|
||
|
||
- **Bulk Synchronous Programming [17]** 与 **MPI [11]**:MapReduce 利用受限的编程模型自动并行化用户程序并提供透明容错。
|
||
- **局部性**:我们的局部性优化借鉴了 **active disks [12, 15]** 等技术,将计算推向靠近本地磁盘的位置。
|
||
- **备份任务**:与 **Charlotte System [3]** 中的 eager scheduling 机制类似;我们通过跳过坏 record 的机制修复了部分重复失败的情况。
|
||
- **集群管理**:在思路上与 **Condor [16]** 相似。
|
||
- **排序**:在操作上与 **NOW-Sort [1]** 类似;MapReduce 增加了用户可定义的 Map 与 Reduce 函数。
|
||
- **River [2]**:MapReduce 将问题划分为大量细粒度 task,并在作业末尾通过冗余执行缩短完成时间。
|
||
- **BAD-FS [5]**、**TACC [7]**:类似地通过重新执行与感知局部性的调度实现容错。
|
||
|
||
---
|
||
|
||
## 8 结论
|
||
|
||
MapReduce 编程模型已在 Google 被成功用于多种用途。我们将成功归因于以下几点:
|
||
|
||
1. 模型易于使用,即使对没有并行与分布式系统经验的程序员也是如此;
|
||
2. 大量问题可以方便地表达为 MapReduce 计算;
|
||
3. 我们实现的规模可扩展到由数千台机器组成的大规模集群。
|
||
|
||
我们得到的认识包括:(1) 限制编程模型便于并行化与分布计算,并使其容错;(2) 网络带宽是稀缺资源,优化应着眼于减少经网络传输的数据;(3) 冗余执行可用于减轻慢机影响并应对机器故障与数据丢失。
|
||
|
||
---
|
||
|
||
## 致谢
|
||
|
||
Josh Levenberg 修订并扩展了用户层 MapReduce API。MapReduce 从 Google File System [8] 读取输入并写入输出。感谢 Mohit Aron、Howard Gobioff、Markus Gutschke、David Kramer、Shun-Tak Leung、Josh Redstone(GFS);Percy Liang、Olcan Sercinoglu(集群管理);以及 Mike Burrows、Wilson Hsieh、Josh Levenberg、Sharon Perl、Rob Pike、Debby Wallach、匿名 OSDI 审稿人与 shepherd Eric Brewer。
|
||
|
||
---
|
||
|
||
## References
|
||
|
||
[1] Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, David E. Culler, Joseph M. Hellerstein, and David A. Patterson. High-performance sorting on networks of workstations. In *Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data*, Tucson, Arizona, May 1997.
|
||
|
||
[2] Remzi H. Arpaci-Dusseau, Eric Anderson, Noah Treuhaft, David E. Culler, Joseph M. Hellerstein, David Patterson, and Kathy Yelick. Cluster I/O with River: Making the fast case common. In *Proceedings of the Sixth Workshop on Input/Output in Parallel and Distributed Systems (IOPADS '99)*, pages 10–22, Atlanta, Georgia, May 1999.
|
||
|
||
[3] Arash Baratloo, Mehmet Karaul, Zvi Kedem, and Peter Wyckoff. Charlotte: Metacomputing on the web. In *Proceedings of the 9th International Conference on Parallel and Distributed Computing Systems*, 1996.
|
||
|
||
[4] Luiz A. Barroso, Jeffrey Dean, and Urs Hölzle. Web search for a planet: The Google cluster architecture. *IEEE Micro*, 23(2):22–28, April 2003.
|
||
|
||
[5] John Bent, Douglas Thain, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, and Miron Livny. Explicit control in a batch-aware distributed file system. In *Proceedings of the 1st USENIX Symposium on Networked Systems Design and Implementation NSDI*, March 2004.
|
||
|
||
[6] Guy E. Blelloch. Scans as primitive parallel operations. *IEEE Transactions on Computers*, C-38(11), November 1989.
|
||
|
||
[7] Armando Fox, Steven D. Gribble, Yatin Chawathe, Eric A. Brewer, and Paul Gauthier. Cluster-based scalable network services. In *Proceedings of the 16th ACM Symposium on Operating System Principles*, pages 78–91, Saint-Malo, France, 1997.
|
||
|
||
[8] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google file system. In *19th Symposium on Operating Systems Principles*, pages 29–43, Lake George, New York, 2003.
|
||
|
||
[9] S. Gorlatch. Systematic efficient parallelization of scan and other list homomorphisms. In L. Bouge, P. Fraigniaud, A. Mignotte, and Y. Robert, editors, *Euro-Par'96. Parallel Processing*, Lecture Notes in Computer Science 1124, pages 401–408. Springer-Verlag, 1996.
|
||
|
||
[10] Jim Gray. Sort benchmark home page. http://research.microsoft.com/barc/SortBenchmark/.
|
||
|
||
[11] William Gropp, Ewing Lusk, and Anthony Skjellum. *Using MPI: Portable Parallel Programming with the Message-Passing Interface*. MIT Press, Cambridge, MA, 1999.
|
||
|
||
[12] L. Huston, R. Sukthankar, R. Wickremesinghe, M. Satyanarayanan, G. R. Ganger, E. Riedel, and A. Ailamaki. Diamond: A storage architecture for early discard in interactive search. In *Proceedings of the 2004 USENIX File and Storage Technologies FAST Conference*, April 2004.
|
||
|
||
[13] Richard E. Ladner and Michael J. Fischer. Parallel prefix computation. *Journal of the ACM*, 27(4):831–838, 1980.
|
||
|
||
[14] Michael O. Rabin. Efficient dispersal of information for security, load balancing and fault tolerance. *Journal of the ACM*, 36(2):335–348, 1989.
|
||
|
||
[15] Erik Riedel, Christos Faloutsos, Garth A. Gibson, and David Nagle. Active disks for large-scale data processing. *IEEE Computer*, pages 68–74, June 2001.
|
||
|
||
[16] Douglas Thain, Todd Tannenbaum, and Miron Livny. Distributed computing in practice: The Condor experience. *Concurrency and Computation: Practice and Experience*, 2004.
|
||
|
||
[17] L. G. Valiant. A bridging model for parallel computation. *Communications of the ACM*, 33(8):103–111, 1997.
|
||
|
||
[18] Jim Wyllie. Spsort: How to sort a terabyte quickly. http://almaden.ibm.com/cs/spsort.pdf.
|
||
|
||
---
|
||
|
||
## 附录 A:词频统计
|
||
|
||
本节给出一个程序,用于统计命令行指定的一组输入文件中每个不同词的出现次数。
|
||
|
||
```cpp
|
||
#include "mapreduce/mapreduce.h"
|
||
|
||
// User's map function
|
||
class WordCounter : public Mapper {
|
||
public:
|
||
virtual void Map(const MapInput& input) {
|
||
const string& text = input.value();
|
||
const int n = text.size();
|
||
for (int i = 0; i < n; ) {
|
||
// Skip past leading whitespace
|
||
while ((i < n) && isspace(text[i]))
|
||
i++;
|
||
// Find word end
|
||
int start = i;
|
||
while ((i < n) && !isspace(text[i]))
|
||
i++;
|
||
if (start < i)
|
||
Emit(text.substr(start,i-start),"1");
|
||
}
|
||
}
|
||
};
|
||
REGISTER_MAPPER(WordCounter);
|
||
|
||
// User's reduce function
|
||
class Adder : public Reducer {
|
||
virtual void Reduce(ReduceInput* input) {
|
||
// Iterate over all entries with the same key and add the values
|
||
int64 value = 0;
|
||
while (!input->done()) {
|
||
value += StringToInt(input->value());
|
||
input->NextValue();
|
||
}
|
||
// Emit sum for input->key()
|
||
Emit(IntToString(value));
|
||
}
|
||
};
|
||
REGISTER_REDUCER(Adder);
|
||
|
||
int main(int argc, char** argv) {
|
||
ParseCommandLineFlags(argc, argv);
|
||
MapReduceSpecification spec;
|
||
// Store list of input files into "spec"
|
||
for (int i = 1; i < argc; i++) {
|
||
MapReduceInput* input = spec.add_input();
|
||
input->set_format("text");
|
||
input->set_filepattern(argv[i]);
|
||
input->set_mapper_class("WordCounter");
|
||
}
|
||
// Specify the output files
|
||
MapReduceOutput* out = spec.output();
|
||
out->set_filebase("/gfs/test/freq");
|
||
out->set_num_tasks(100);
|
||
out->set_format("text");
|
||
out->set_reducer_class("Adder");
|
||
// Optional: do partial sums within map tasks to save network bandwidth
|
||
out->set_combiner_class("Adder");
|
||
// Tuning parameters
|
||
spec.set_machines(2000);
|
||
spec.set_map_megabytes(100);
|
||
spec.set_reduce_megabytes(100);
|
||
// Now run it
|
||
MapReduceResult result;
|
||
if (!MapReduce(spec, &result)) abort();
|
||
return 0;
|
||
}
|
||
```
|